







参考:
https://mp.weixin.qq.com/s/J3kCOJwyv2nzvI0_X0tlnA
丁奇《 MySQL 实战 45 讲》
https://www.bilibili.com/video/BV12b411K7Zu?p=242&t=1686
基础概念
存储引擎
Myisam
批量插入速度快,不支持事务,支持全文检索,表锁,底层B+树叶子节点value存放的是地址,通过地址查询数据
InnoDb
批量插入速度慢,支持事务,不支持全文检索,行锁,底层B+树叶子节点,主键索引 value存放的是整行数据,非主键索引 value存放的是主键的ID。
B+树

索引
聚簇索引(主索引)和非聚簇索引(辅助索引)
主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
有主键,则主键是主索引,如果没有主键选择没有Null值得唯一索引作为主索引,如果没有唯一索引,那么会生成一个6字节的row_id来作为主索引。

辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找,这个过程也被称作回表。

分类
- 主键索引
主键是一种唯一性索引,但它必须指定为“PRIMARY KEY” - 全文索引
FULLTEXT - 普通索引
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。
CREATE INDEX - 唯一索引
这种索引和前面的“普通索引”基本相同,但有一个区别:索引列的所有值都只能出现一次,即必须唯一。CREATE UNIQUE INDEX
事务
四大特性
- 原⼦性(Atomicity): 事务是最⼩的执⾏单位,不允许分割。事务的原⼦性确保动作要么全部完成,要么完全不起作⽤;
- ⼀致性(Consistency): 执⾏事务前后,数据保持⼀致,多个事务对同⼀个数据读取的结果是相同的;
- 隔离性(Isolation): 并发访问数据库时,⼀个⽤户的事务不被其他事务所⼲扰,各并发事务之间数据库是独⽴的;
- 持久性(Durability): ⼀个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发⽣故障也不应该对其有任何影响。
并发事务带来哪些问题
-
脏读(Dirty read) : 脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据,依据“脏数据”所做的操作可能是不正确的。
-
丢失修改(Lost to modify) : 指在⼀个事务读取⼀个数据时,另外⼀个事务也访问了该数据,那么在第⼀个事务中修改了这个数据后,第⼆个事务也修改了这个数据。这样第⼀个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
-
不可重复读(Unrepeatableread) : 事务A读取一行数据。然后事务B修改或删除该行数据,并执行提交。然后事务A尝试重新读取该行数据,它可能会接收修改后的值或发现该行已被删除。这样在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
-
幻读(Phantom read) : 幻读与不可重复读类似。它发⽣在⼀个事务(T1)读取了⼏⾏数据,接着另⼀个并发事务(T2)新增了⼀些数据时。在随后的查询中,第⼀个事务(T1)就会发现多了⼀些原本不存在的记录,就好像发⽣了幻觉⼀样,所以称为幻读。
参考:
http://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt

隔离级别

MVCC
参考:
https://mp.weixin.qq.com/s/CZHuGT4sKs_QHD_bv3BfAQ
https://www.bilibili.com/video/BV1YJ411J7vb?t=934
数据表中的一行记录,其实可能有多个版本(row),每个版本有自己的row trx_id。
MVCC 只在REPEATABLE READ和READ COMMITIED两个隔离级别下工作。其他两个隔离级别都和 MVCC不兼容 ,因为READ UNCOMMITIED总是读取最新的数据行,而不是符合当前事务版本的数据行。而SERIALIZABLE则会对所有读取的行都加锁。
事务ID(DB_TRX_ID)和回滚指针(DB_ROLL_PT)
InnoDB的MVCC是通过在每行记录后面保存两个隐藏的列来实现的。一个保存了行的事务ID(DB_TRX_ID),一个保存了行的回滚指针(DB_ROLL_PT)。每开始一个新的事务,都会自动递增产生一个新的事务id。事务开始时刻的会把事务id放到当前事务影响的行事务id中,当查询时需要用当前事务id和每行记录的事务id进行比较。

undo log
根据行为的不同,undo log分为两种:insert undo log 和 update undo log



ReadView(快照)
当执行查询SQL是会生成一致性视图 read view,它由执行查询时所有未提交事务ID组(数组里最小的ID为min_id)和已创建的最大事务ID(max_id)组成,我们把这个列表命名为为m_ids。
查询数据的结果需要跟read view做对比从而得到快照结果。
对于查询时的版本链数据是否看见的判断逻辑:
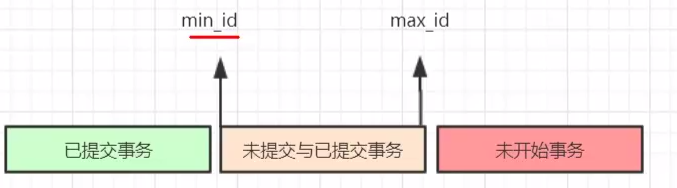
- 如果被访问版本的 trx_id落在绿色部分(trx_id<min_id),则表示这个版本是由已经提交的事务生成的,所以该版本可以被当前事务访问。
- 如果被访问版本的 trx_id落在红色部分(trx_id>max_id),则表示这个版本是由将来启动的事务生成的,所以该版本不可以被当前事务访问。
- 如果被访问版本的 trx_id落在橙色部分(min_id<=trx_id<=max_id),两种情况
a. 若trx_id 在 m_ids数组里,表示这个版本是由还没提交的事务生成的,所以该版本不可以被当前事务访问。
b.若trx_id 不在 m_ids不数组里,表示这个版本是由已提交的事务生成的,所以该版本可以被当前事务访问。
例子
READ COMMITTED 隔离级别下的ReadView
每次读取数据前都生成一个ReadView (m_ids列表)!!!
基础数据
(id,name)
(1,Mbappe)

时间点 T5 情况下的 SELECT 语句:

生成一个ReadView,此时m_ids列表[777,888],
(1)被访问版本的 trx_id=777,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=777
(2)此时被访问版本的 trx_id变成777,落在橙色区A情况,无法访问数据,继续通过undo log找上一个版本,获得上一个访问版本的 trx_id=111
(3)此时被访问版本的 trx_id变成111,落在绿色区,可以访问数据,返回结果Mbappe。
时间点 T8 情况下的 SELECT 语句:

生成一个ReadView,此时m_ids列表[888],
(1)被访问版本的 trx_id=888,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=777
(2)此时被访问版本的 trx_id变成777,落在绿色区,可以访问数据,返回结果Messi。
时间点 T11 情况下的 SELECT 语句:

生成一个ReadView,此时m_ids列表[],
(1)被访问版本的 trx_id=888,m_ids列表为空,直接返回数据Dybala。
REPEATABLE READ 隔离级别下的ReadView
在事务开始后第一次读取数据时生成一个ReadView(m_ids列表)

时间点 T5 情况下的 SELECT 语句:

生成一个ReadView,此时m_ids列表[777,888],
(1)被访问版本的 trx_id=777,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=777
(2)被访问版本的 trx_id=777,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=111
(2)此时被访问版本的 trx_id=111,落在绿色区,可以访问数据,返回结果Mbappe。
时间点 T8 情况下的 SELECT 语句:

不生成新的ReadView,使用之前的ReadView,此时m_ids列表[777,888],
(1)被访问版本的 trx_id=888,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=777
(2)被访问版本的 trx_id=777,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=777
(3)被访问版本的 trx_id=777,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=111
(4)此时被访问版本的 trx_id=111,落在绿色区,可以访问数据,返回结果Mbappe。
时间点 T11 情况下的 SELECT 语句:

不生成新的ReadView,使用之前的ReadView,此时m_ids列表[777,888],
(1)被访问版本的 trx_id=888,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=888
(2)被访问版本的 trx_id=888,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=777
(3)被访问版本的 trx_id=777,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=777
(4)被访问版本的 trx_id=777,按照规则,落在橙色区A情况,无法访问数据,通过版本链找上一个版本,获得上一个访问版本的 trx_id=111
(5)此时被访问版本的 trx_id=111,落在绿色区,可以访问数据,返回结果Mbappe。
锁
- 表锁
MySQL中锁定 粒度最⼤的⼀种锁,对当前操作的整张表加锁,实现简单,资源消耗也⽐较少,加锁快,不会出现死锁。其锁定粒度最⼤,触发锁冲突的概率最⾼,并发度最低。 - 行锁
MySQL中锁定 粒度最⼩的⼀种锁,只针对当前操作的⾏进⾏加锁。 ⾏级锁能⼤⼤减少数据库操作的冲突。其加锁粒度最⼩,并发度⾼,但加锁的开销也最⼤,加锁慢,会出现死锁。
InnoDB存储引擎的锁的算法有三种:
- Record lock:单个⾏记录上的锁
- Gap lock:间隙锁,锁定⼀个范围,不包括记录本身
- Next-key lock: record+gap 锁定⼀个范围,包含记录本身


SQL执行过程

如何调优
1.通过慢查询日志找出慢SQL

2.检查表是否有建索引,如果没有此时要考虑哪些情况需要建?哪些情况不需要建?

3.explain 模拟SQL执行情况,是否使用索引,查询行数等。。。
3.1 explain是什么
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。
3.2 explain能干吗
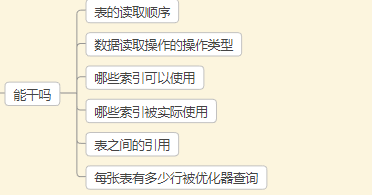
3.3 explain字段说明
- id
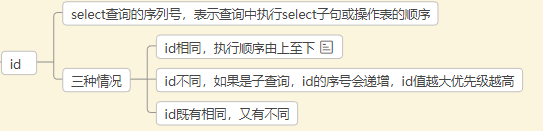
- select_type 查询的类型,主要用于区别普通查询,联合查询,子查询等复杂查询

- table 显示这一行的数据是关于哪张表的
- type
显示查询使用了何种类型,从最好到最差依次是:system>const>eq_ref>ref>range>index>all
一般来说,保证查询至少达到range级别,最好能达到ref。

- possible_keys
显示可能应用到这张表中的索引,一个或多个。查询涉及到的字段若存在索引,则该索引将被列出,但不一定被查询实际使用 - key
实际使用的索引,如果为NULL,则没使用索引;
查询中若使用了覆盖索引,该索引仅出现在key列表中。 - key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精度的情况下,长度越短越好。
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,是根据表的定义计算得到,不是通过表内检索出的。 - ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值 - rows
根据表统计信息及索引选用情况,大致估算出找到所需记录需要读取的行数。 - extra

3.4 explain两个需要注意的地方
- 排除缓存⼲扰

- rows 不一定正确
MySQL中数据的单位都是⻚, MySQL⼜采⽤了采样统计的⽅法,采样统计的时候, InnoDB默认会选择N个数据⻚,统计这些⻚⾯上的不同值,得到⼀个平均值,然后乘以这个索引的⻚⾯数,就得到了这个索引的基数。
如果是上⾯的统计信息错了,那简单,我们⽤analyze table tablename 就可以重新统计索引信息了,所以在实践中,如果你发现explain的结果预估的rows值跟实际情况差距⽐较⼤,可以采⽤这个⽅法来处理。
3.4 SQL优化
3.4.1 避免索引失效

测试SQL:
CREATE TABLE `test01` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c1` int(10) NULL DEFAULT NULL,
`c2` int(10) NULL DEFAULT NULL,
`c3` int(10) NULL DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `c123`(`c1`, `c2`, `c3`) USING BTREE,
INDEX `cname`(`name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 6 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
EXPLAIN SELECT * FROM `test01` WHERE c1 = 1 AND c2 =2 AND c3 =3; # 用上了三个索引
EXPLAIN SELECT * FROM `test01` WHERE c2 =2 AND c3 =3 AND c1 = 1; # 自动优化 优化后 WHERE c1 = 1 and c2 =2 AND c3 =3; 用上了三个索引
EXPLAIN SELECT * FROM `test01` WHERE c2 =2 AND c3 =3 ; # 带头大哥死了 一个索引都没用上
EXPLAIN SELECT * FROM `test01` WHERE c1 = 1 AND c3 =3; # 中间兄弟断了,只用上了第一个C1索引
EXPLAIN SELECT * FROM `test01` WHERE c1 = 1 ; # 用到C1的索引
EXPLAIN SELECT * FROM `test01` WHERE c1 = 1 AND c2 =2; # 用到C1 C2的索引
EXPLAIN SELECT * FROM `test01` WHERE c1 = 1 AND c2 >2 AND c3 =3; # 存储引擎不能使用索引中范围条件右边的列 只用到了C1 C2的索引
EXPLAIN SELECT * FROM `test01` WHERE c1 > 1 AND c2 =2 AND c3 =3; # 存储引擎不能使用索引中范围条件右边的列 只用到了C1 的索引
EXPLAIN SELECT * FROM `test01` WHERE c1 = 1 AND c3 >2 AND c2 =3; # 自动优化 优化后:WHERE c1 = 1 AND c2 =3 AND c3 >2; 用上了三个索引
EXPLAIN SELECT * FROM `test01` WHERE c1 != 1 ; # 无法使用索引
EXPLAIN SELECT * FROM `test01` WHERE c1 <> 1 ; # 无法使用索引
EXPLAIN SELECT c1 FROM `test01` WHERE c1 != 1 ; # 覆盖索引,会使用索引
#默认为Null的列,存在Null值会导致mysql优化器处理起来比较复杂,但是到底走不走索引,或者走那个索引,是要靠mysql优化器预先预估走那个索引成本比较低来决定的
EXPLAIN SELECT * FROM `test01` WHERE c1 is null; # 无法使用索引
EXPLAIN SELECT * FROM `test01` WHERE c1 is not null; # 用到C1的索引
EXPLAIN SELECT * FROM `test01` WHERE name LIKE '%1%'; # 无法使用索引
EXPLAIN SELECT name FROM `test01` WHERE name LIKE '%1%'; # 覆盖索引,会使用索引
EXPLAIN SELECT * FROM `test01` WHERE name LIKE '%1'; # 无法使用索引
EXPLAIN SELECT * FROM `test01` WHERE name LIKE '1%'; # 使用索引
#test02与test01结构一样, c1 c2 c3 是varchar
EXPLAIN SELECT * FROM `test02` WHERE c1 = '1' AND c2 Like'kk%' AND c3 ='3'; # 用上了三个索引
EXPLAIN SELECT * FROM `test02` WHERE c1 = '1' AND c2 Like'%kk%' AND c3 ='3'; # 只用上了c1
EXPLAIN SELECT * FROM `test02` WHERE c1 = '1' AND c2 Like'%kk' AND c3 ='3'; # 只用上了c1
EXPLAIN SELECT * FROM `test01` WHERE name = '1'; # 使用索引
EXPLAIN SELECT * FROM `test01` WHERE name = 1; # 无法使用索引,字符串不加单引号索引失效
EXPLAIN SELECT * FROM `test01` WHERE c1 = 1 or c2 =2 ;# 无法使用索引,少用or,用它连接索引失效
3.4.1 小表永远驱动大表

3.4.1 order by关键字优化


3.4.1 group by关键字优化

4.Show Profile查看SQL执行详情

5.找DBA进行数据库服务器参数调优
几个关键名词解释:
回表
辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找,这个过程也被称作回表。
索引下推




覆盖索引

可以用于处理 %%索引失效的情况
EXPLAIN SELECT * FROM `test01` WHERE name LIKE '%1%'; # 无法使用索引

#name字段有索引
EXPLAIN SELECT id,name FROM `test01` WHERE name LIKE '%1%'; # 覆盖索引,会使用索引

主从复制
数据库主从复制原理
(1):主库db的更新事件(update、insert、delete)被写到binlog
(2):主库创建一个binlog dump thread线程,把binlog的内容发送到从库
(3):从库创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
(4):从库还会创建一个SQL线程,从relay log里面读取内容写入到slave的db














 894
894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









