







 本文介绍了一位Java开发者如何通过Python进行NLP情感分析,详细讲述了从搭建环境、训练模型到使用Java调用Python模型的过程,包括Python环境配置、版本选择、第三方库的安装以及Java调用Python的实现方法。
本文介绍了一位Java开发者如何通过Python进行NLP情感分析,详细讲述了从搭建环境、训练模型到使用Java调用Python模型的过程,包括Python环境配置、版本选择、第三方库的安装以及Java调用Python的实现方法。
最近项目中要使用NLP进行情感分析,作为一个Java程序员,对于NLP是一窍不通,就连python语言也是没入门。这可难坏了。
通过各种百度找资料,发现了这个帖子(链接如下:https://www.cnblogs.com/jclian91/p/10886031.html),参考这个帖子写了一个NLP的demo案例。其中参考的源代码和部分数据:https://github.com/renjunxiang/Text-Classification/blob/master/TextClassification/data/data_single.csv
我讲GitHub的代码拉到本地之后,用pycharm打开 下载好相关包之后运行,这里不得不说python的环境之多真是大坑,各种版本不匹配的问题以及版本问题导致的代码不兼容,哎,实在是大坑。
1. 首先看看经过我更改之后的python项目目录结构:
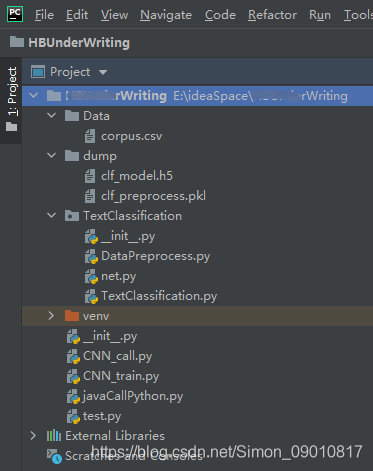
其中TextClassification中的代码就是上面GitHub上的,其中就有CNN训练的一些封装的代码。注意这个目录结构,因为后面Java调用python的时候我遇到的问题就在这。
2.python自身和依赖第三方包的版本
首先是python自己的版本,我选用的是anaconda
![]()
安装之后就是python3.8 注意安装的时候选择将路劲添加到环境变量中,自己配置过于繁琐。大概就是这样的:
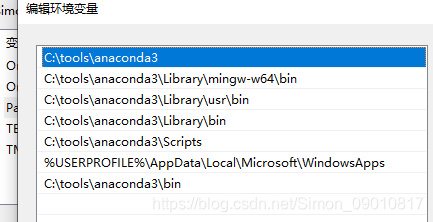
其次是项目中依赖的第三方包:
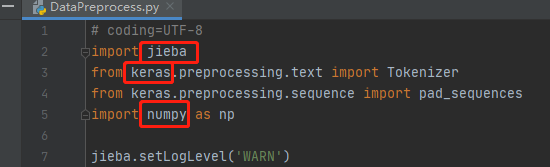
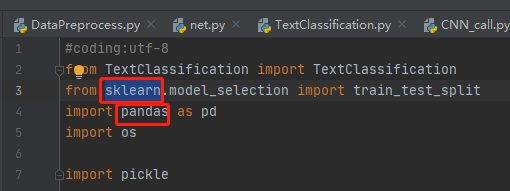
主要就是这几个,这里特别说明的是keras是需要tensorflow的,所以还是间接需要tensorflow的包
具体的版本就是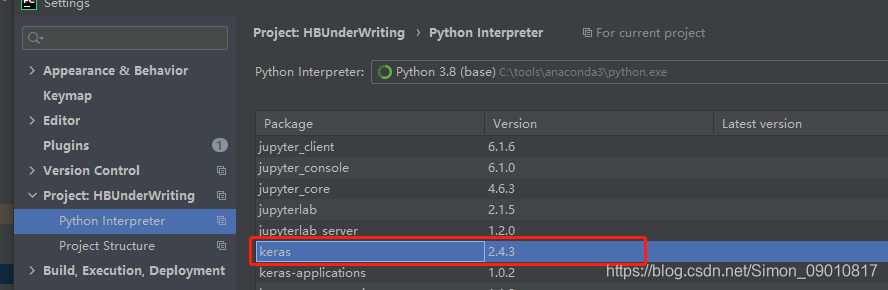
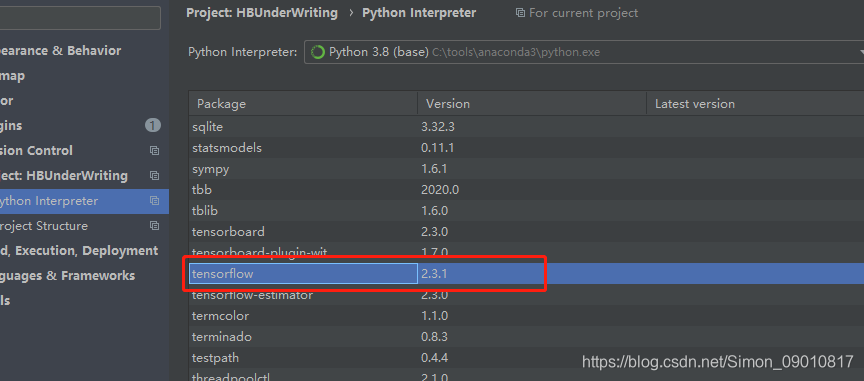
其他的版本下载最新版就可以 问题应该不大。
这里说下下载第三方包。在pycharm中下载很有可能下载不成功。即使是配置了豆瓣的镜像http://pypi.douban.com/simple
我用anaconda下载比较快速:
首先配置pip的全局镜像:
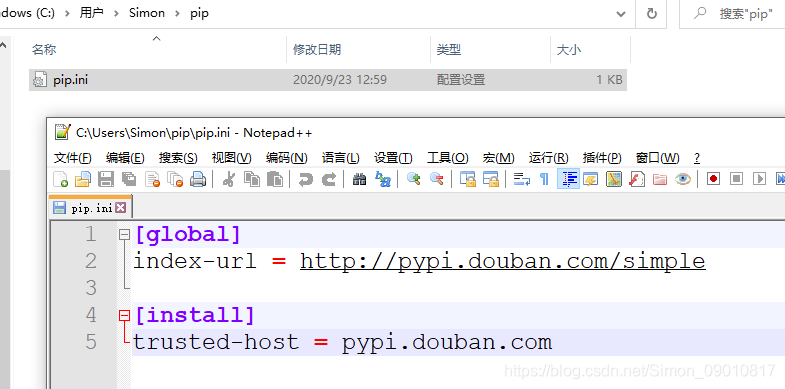
在用户目录下新建pip文件夹和pip.ini,pip文件内容如下:
[global]
index-url = http://pypi.douban.com/simple
[install]
trusted-host = pypi.douban.com
在anaconda安装目录下cmd 进行安装各自的依赖:
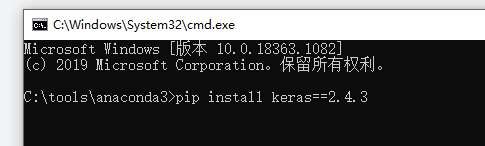
安装好之后就可以进行训练了。
整个训练序列化了两个文件,分别是封装类中的preprocess和model,这里需要用不同的序列化方式。
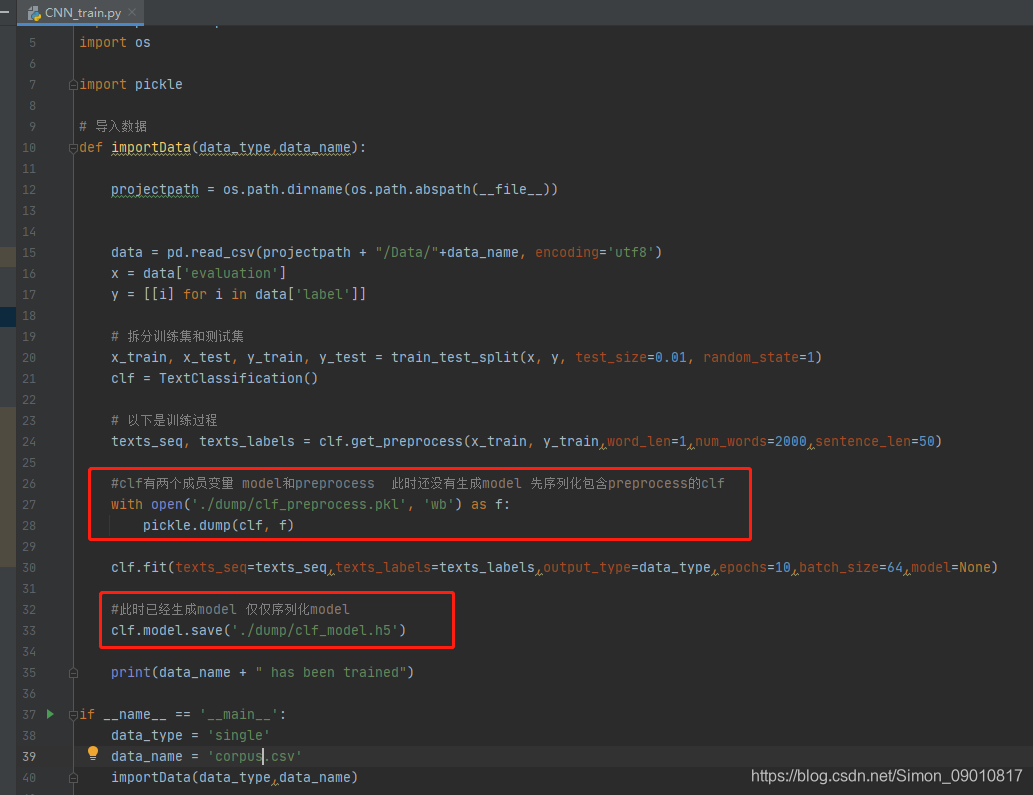
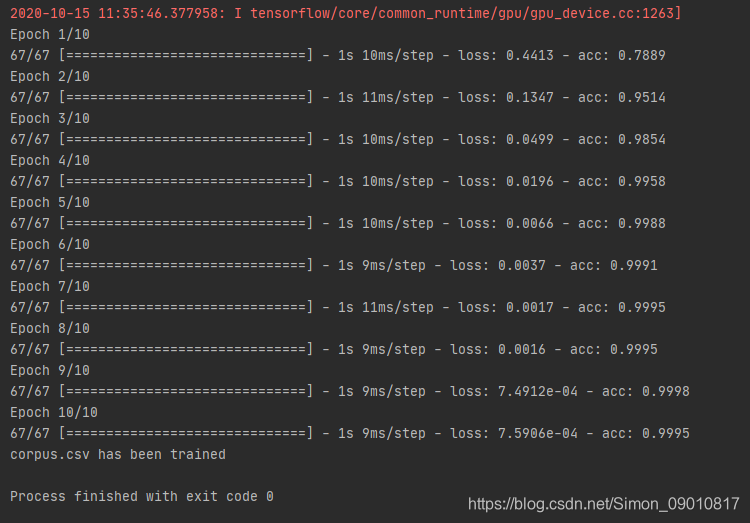
序列化成功之后,进行模型调用和预测:
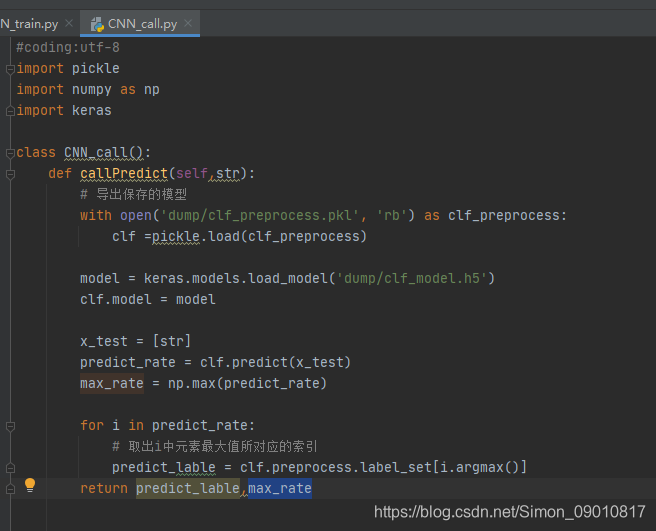
读取训练时保存的pkl和h5文件,类似与java中class对象的成员变量。再调用封装类的predict方法。
进行测试:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









