







大数据学习(3)
本次主要讲述Hadoop中的Hive的DML语法和函数,Hive数据库也有类似的sql语句。
1 Hive-SQL-DML语句
在数据库中一般分为DDL语言和DML语言,DDL(Data Define Language)是数据定义语言,主要是进行定义/改变表的结构、数据类型、表之间的链接等操作。常用的语句关键字有 CREATE、DROP、ALTER 等。而接下来要学习的是DML(Data Manipulation Language)数据操纵语言,主要是对数据进行增加、删除、修改操作。常用的语句关键字有 INSERT、UPDATE、DELETE 等。
DDL在大数据学习 2中已经介绍过了,主要是对数据库,数据表的建立,删除,更改等操作,比较像面向对象编程中的类,对类进行属性的确认。那么DML进行的操作就是对数据库中实际数据的处理,类比于面向对象编程中的实例。
1.1 Hive SQL Load 加载数据语句
如果不使用Hive sql语句来完成加载数据的话,Hadoop的HDFS系统有一个web端口,可以在其应用中通过上传文件来完成加载数据的操作。
- 在Hive中建表成功之后,就会在HDFS上创建一个与之对应的文件夹,且文件夹名字就是表名。
- 文件夹父路径是由参数hive.metastore.warehouse.dir控制,默认值是/user/hive/warehouse。在其中找到自己创建的表,upload对应的文件就行。
- 不管路径在哪里,只有把数据文件移动到对应的表文件夹下面,Hive才能映射解析成功;
- 最原始暴力的方式就是使用hadoop fs -put|-mv等方式直接将数据移动到表文件夹下;
- 但是,Hive官方推荐使用Load命令将数据加载到表中。
1.1.1 Load功能
- 所谓加载是指:将数据文件移动到与Hive表对应的位置,移动时是纯复制、移动操作。
- 纯复制、移动指在数据load加载到表中时,Hive不会对表中的数据内容进行任何转换,任何操作。
1.1.2 Load语法规则
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename;
1.1.3 Load 语法实验
Load语法有两种操作方法:
- Load Data From Local FS
- Load Data From HDFS
1.1.3.1 Load Data From Local FS
这里主要的关键是Local关键字的含义,对于集群的HDFS系统来说,Local就是安装了hadoop的那台主机,并非是其他打开Beeline,Datagrip或者其他连接工具所在的机器。
Load Data From Local FS,是从本机上直接复制已经结构化的数据文件到hdfs的文件系统对应的数据表目录下,完成数据的加载。其本质和hadoop的fs命令是一样的。
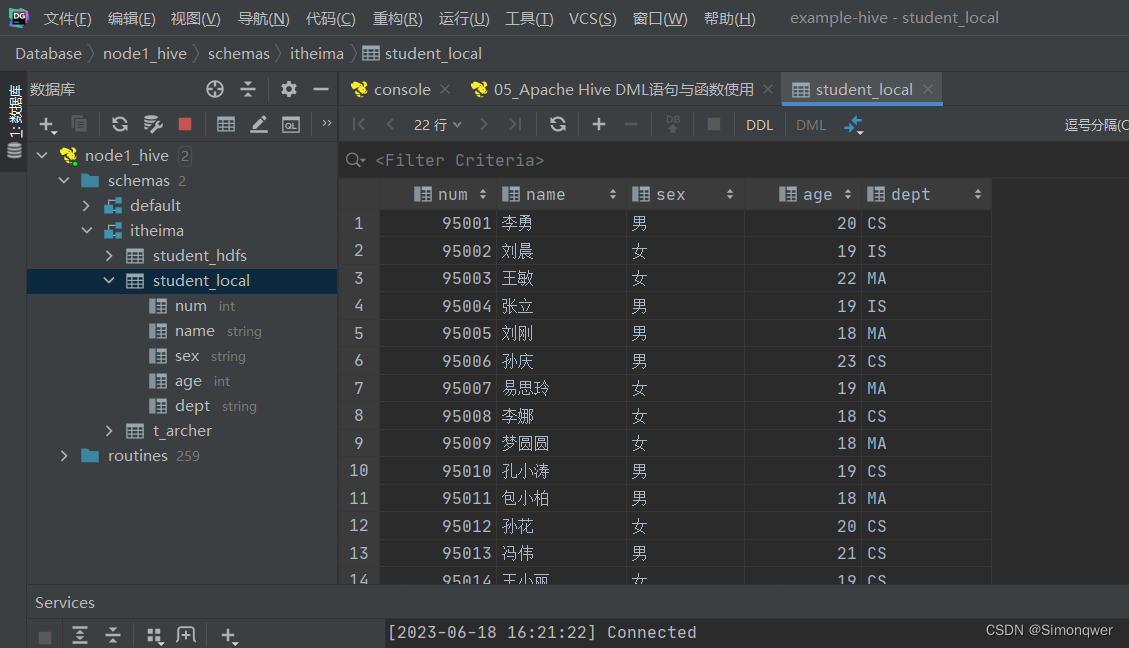
LOAD DATA LOCAL INPATH '/root/hivedata/students.txt' INTO TABLE student_local;
结果:

完成的是复制操作,原来的文件并没有发生变化

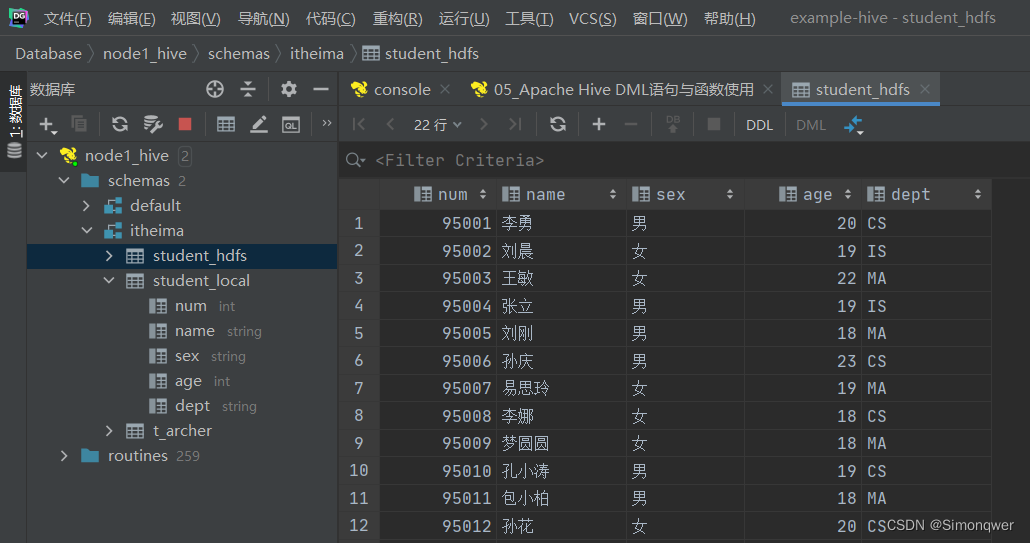
查询表的结果:
1.1.3.2 Load Data From HDFS
对于从HDFS系统中的操作,首先要将文件上传到Hadoop的HDFS中,有两种上传方式,一种是用hadoop fs命令上传,另一种是直接从web端的文件上传。个人认为这主要取决于上传的文件多少和具体的开发环境,网络的设置。
hadoop fs 命令上传:
hadoop fs -put /root/hivedata/students.txt /
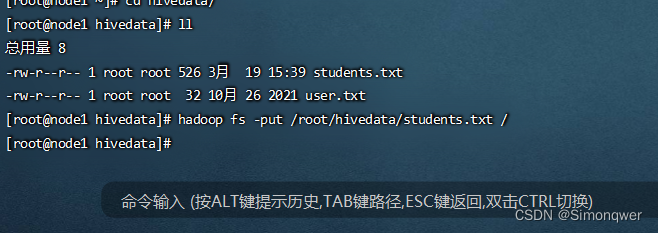
可以在HDFS系统中看到上传的students.txt,同时原本的txt文件也没有变化。
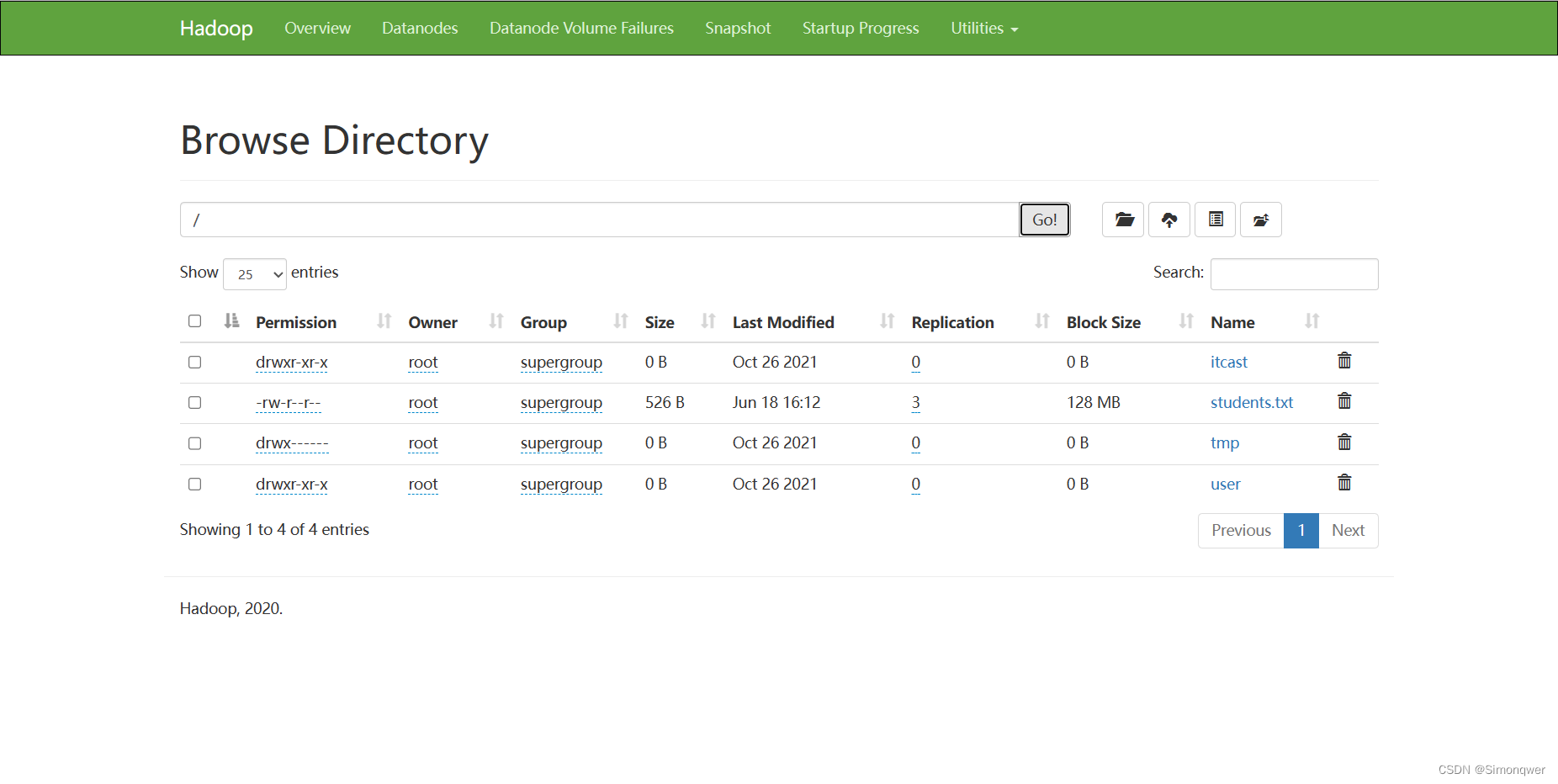

使用Load命令,可以发现加载的方式不同,结果:

同时可以看到原本在根目录下的txt文件被移动
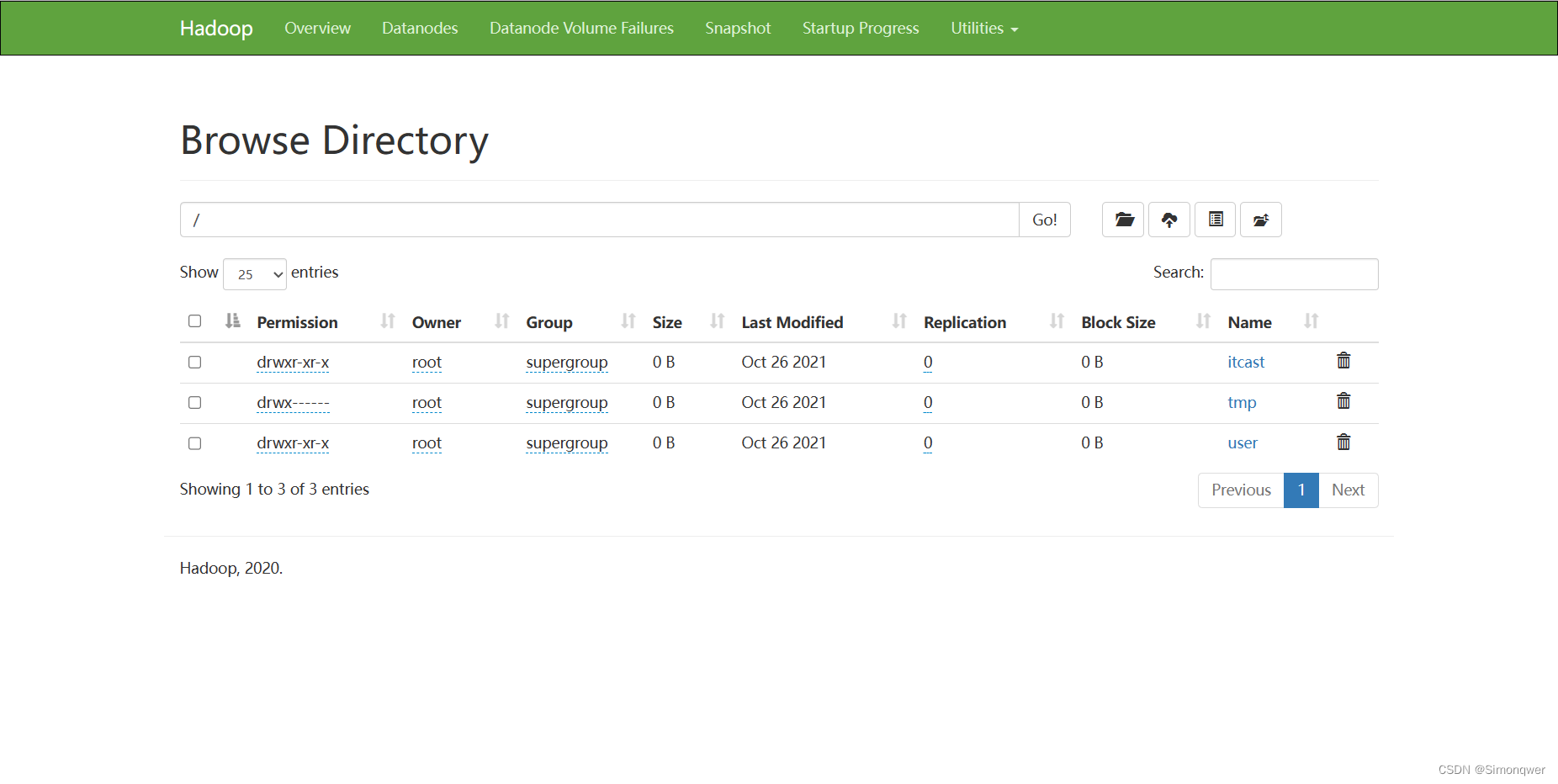
查询表的结果:
1.1.3.3 Overwrite选项
这个补充命令慎用,会将之前加载的数据全部清除,重新写入此次的加载数据。
同时也注意,同一个文件是可以多次加载的,如果sql文件的逻辑不对,可能会一直加载同一个文件,造成数据库里重复。
另外Load指令只是官方推荐给用户使用的加载方法,但是在一些情况下也可以在了解原理的情况下使用其他(非安全但快速)方法来解决加载。
1.2 Hive SQL Insert 插入数据语句
Hive官方推荐加载数据的方式:
清洗数据成为结构化文件,再使用Load语法加载数据到表中。
但是Insert的功能就类似于传统的sql语言,直接通过在控制端的手输脚本来向表中添加数据。**不过Hive运行插入很慢,非常慢。**执行mapreduce,还要申请资源,非常慢。
insert into table Tablename values(......);
在Hive的最常使用的配合就是将查询返回的结果插入到另一张表中。
insert+select
insert into table Tablename select statement1,statement2 from From_tablename;
insert+select表示:将后面查询返回的结果作为内容插入到指定表中
- 需要保证查询结果列的树木和需要插入数据表格的列数目一致。
- 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证一定成功,转换失败的数据会为NULL。
实验结果:
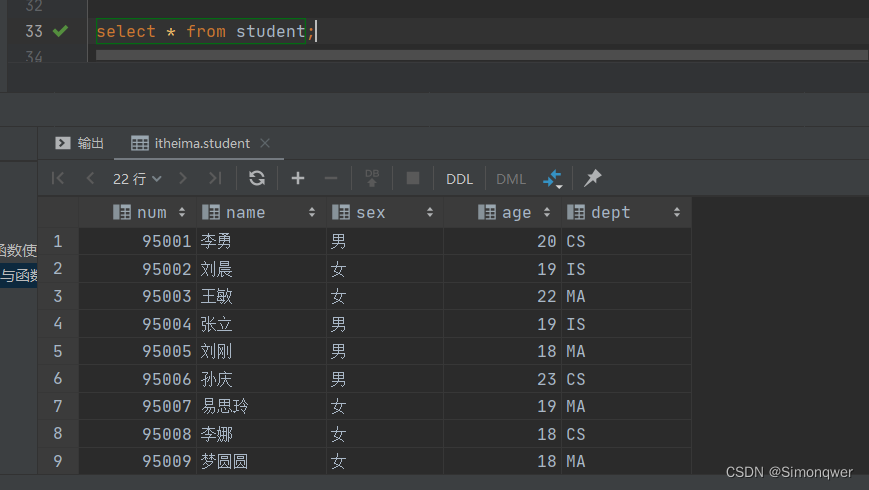
- 建表,加载数据
create table student(num int,name string,sex string,age int,dept string)
row format delimited fields terminated by ',';
load data local inpath '/root/hivedata/students.txt' into table student;
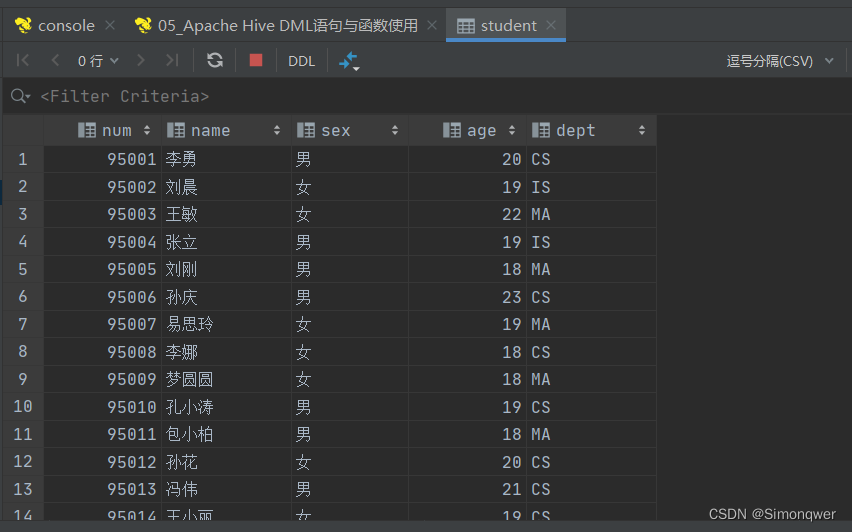
- 查看student表
datagrip中可以直接点击表查看里面的数据,也可以用select语句来查看。
3. 再创建一个目标表,只有两个字段
create table student_from_insert(sno int,sname string);
这时新建的student_from_insert表是空的
- 使用Insert+select语句
insert into table student_from_insert select num,name from student;
- 查看插入之后的student_from_insert
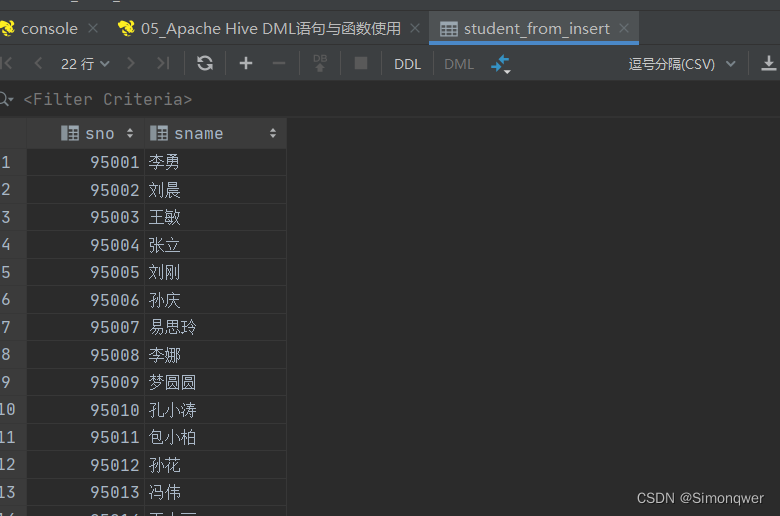
可以看到表中的变化,但是由于底层是完成了一个mr程序,是有点慢的,在vm虚拟机上大概是运行了30s。
1.3 Hive SQL Select 基础查询语句
1.3.1 select 语法树
- FROM后面的参数就是查询操作的对象
- 表名和列名不区分大小写
select [all|distinct] select_expr1,select_expr2...
from table_reference
[where where_condition]
[group by col_list]
[order by col_list]
[limit [offset,] rows];
1.3.1.1 select_expr
1. 查询所有字段和指定字段
基本和其他的sql语言一样,前面准备和加载t_usa_covid19表格的操作略去。
select * from t_usa_covid19;
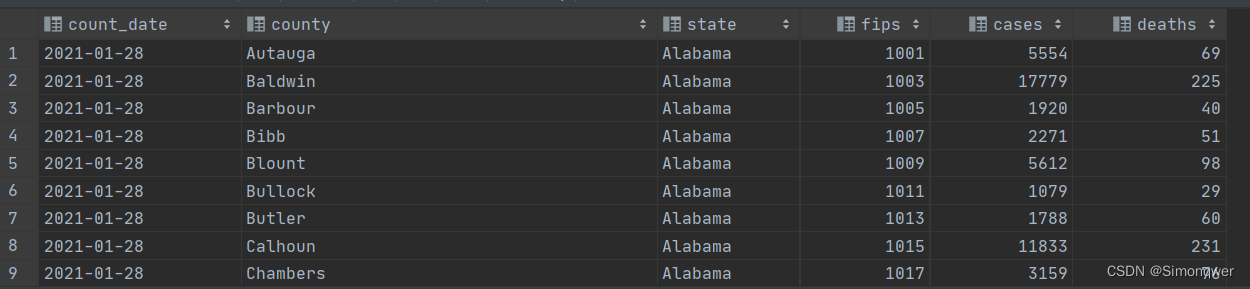
上面的sql语句是查询表中所有字段的数据,对于数据量比较小的开发情况的话,可以这样暴力拉整个表的数据来看,但是表太大的话也是会爆内存的。
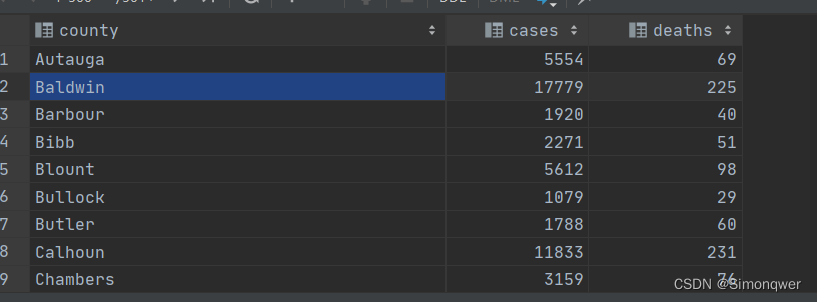
select county, cases, deaths from t_usa_covid19;
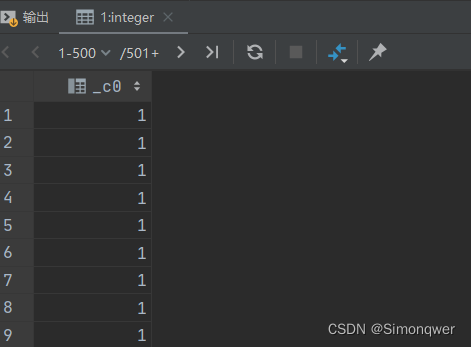
2. 查询常数返回
查询常数返回 此时返回的结果和表中字段无关
select 1 from t_usa_covid19;
在开发的某些情况下有用。
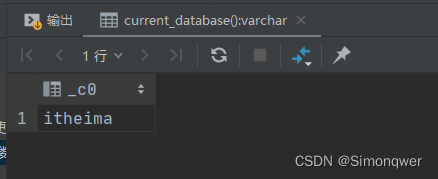
3. 查询当前数据库
select current_database();
这种写法可以省略FROM关键字,查询当前处于哪个数据库下。
1.3.1.2 all、distinct
用于指定查询返回结果中重复的行如何处理
- 如果没有写参数,则默认值为ALL(返回所有匹配的行)。
- DISTINCT指定从结果集中删除重复的行。
如果查询有多个字段时,再加上distinct是对整体去重。
1.3.1.3 where
- where后面所接的是一个布尔表达式(结果要么是true,要么是false),用于查询过滤,当布尔表达式为true时,返回select后面expr表达式的结果,否则返回空。
- 在where表达式中,可以使用hive支持的任何函数和运算符,但聚合函数除外
支持比较运算和逻辑运算
比较运算:> < = != >= <= <>
逻辑运算:and or
支持特殊条件
1.空值判断: is null
select * from emp where comm is null;
查询emp表中comm列中的空值
2.between and(在 之间的值)
select * from emp where sal between 1500 and 3000;
查询emp表中sal列中大于1500的小于300的值。
注意:大于等于1500且小于等于3000,1500为下限,3000为上限,上限在后,查询的范围包涵有上下限的值。
3.in
select * from emp where sal in (5000,3000,1500);
查询emp表sal列中等于5000,3000,1500的值。
1.3.1.4 聚合操作
- SQL中拥有很多可用于计数和计算的内建函数,其使用的语法是:SELECT function(列)FROM 表。
- 这里我们要介绍的叫做聚合(Aggregate)操作函数,如:Count、Sum、Max、Min、Avg等函数。
- 聚合函数的最大特点是不管原始数据有多少行记录,经过聚合操作只返回一条数据,这一条数据就是聚合的结果。
常见的聚合操作函数
| 函数作用 | 例子 |
|---|---|
| 返回某列的平均值 | AVG(column) |
| 返回某列的行数(不包括NULL值) | COUNT(column) |
| 返回被选行数 | COUNT(*) |
| 返回某列的最高值 | MAX(column) |
| 返回某列的最低值 | MIN(column) |
| 返回某列的总和 | SUM(column) |
--统计美国总共有多少个县county
select county as ct from t_usa_covid19;
--学会使用as 给查询返回的结果起个别名
select count(county) as county_cnts from t_usa_covid19;
--去重distinct
select count(distinct county) as county_cnts from t_usa_covid19;
--统计美国加州有多少个县
select count(county) from t_usa_covid19 where state = "California";
--统计德州总死亡病例数
select sum(deaths) from t_usa_covid19 where state = "Texas";
--统计出美国最高确诊病例数是哪个县
select max(cases) from t_usa_covid19;
1.3.1.5 group by
- GROUP BY语句用于结合聚合函数,根据一个或多个列对结果集进行分组;
- 如果没有group by语法,则表中的所有行数据当成一组。
GROUP BY语法限制:
- 出现在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段。
- 原因:避免出现一个字段多个值的歧义。
1.分组字段出现select_expr中,一定没有歧义,因为就是基于该字段分组的,同一组中必相同;
2.被聚合函数应用的字段,也没歧义,因为聚合函数的本质就是多进一出,最终返回一个结果。
1.3.1.6 having
- 在SQL中增加HAVING子句原因是,WHERE关键字无法与聚合函数一起使用。
- HAVING子句可以让我们筛选分组后的各组数据,并且可以在Having中使用聚合函数,因为此时where,group by已经执行结束,结果集已经确定。
where和having的区别:
- having是在分组后对数据进行过滤
- where是在分组前对数据进行过滤
- having后面可以使用聚合函数
- where后面不可以使用聚合函数
1.3.1.7 order by
- ORDER BY 语句用于根据指定的列对结果集进行排序。
- ORDER BY 语句默认按照升序(ASC)对记录进行排序。如果您希望按照降序对记录进行排序,可以使用DESC关键字
1.3.1.8 limit
- LIMIT用于限制SELECT语句返回的行数。
- LIMIT接受一个或两个数字参数,这两个参数都必须是非负整数常量。
- 第一个参数指定要返回的第一行的偏移量(从Hive 2.0.0开始),第二个参数指定要返回的最大行数。当给出单个参数时,它代表最大行数,并且偏移量默认为0。
1.3.1.9 执行顺序
- 在查询过程中执行顺序:from>where>group(含聚合)>having >order>select;
1.聚合语句(sum,min,max,avg,count)要比having子句优先执行
2.where子句在查询过程中执行优先级别优先于聚合语句(sum,min,max,avg,count)
1.4 Hive SQL Join 查询语句
join查询背景:
- 根据数据库的三范式设计要求和日常工作习惯来说,我们通常不会设计一张大表把所有类型的数据都放在一起,而
是不同类型的数据设计不同的表存储。 - 在这种情况下,有时需要基于多张表查询才能得到最终完整的结果。
- join语法的出现是用于根据两个或多个表中的列之间的关系,从这些表中共同组合查询数据。
1.4.1 hive join 语法规则
- 在Hive中,使用最多,最重要的两种join分别是:
inner join(内连接)、left join(左连接)
table_reference:是join查询中使用的表名。
table_factor:与table_reference相同,是联接查询中使用的表名。
join_condition:join查询关联的条件,如果在两个以上的表上需要连接,则使用AND关键字。
join_table:
- table_reference [INNER] JOIN table_factor [join_condition]
- | table_reference YLEFT} [OUTER] JOIN table_reference join_condition
join_condition:
- ON expression
上面写的公式可能比较抽象,具体的例子。
table1 t_1 inner join table2 t_2
on t_1.id =t_2.id;
上面的结果是一张表,是table1和table2两张表进行内连接。
1.4.2 inner join 内连接
- 内连接是最常见的一种连接,它也被称为普通连接,其中inner可以省略:inner join= join;
- 只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。
select e.id,e.name,e_a.city,e_a.street
from employee e inner join employee_address e_a
on e.id =e_a.id;

同理也可以省略掉inner,直接将inner join写成join。
select e.id,e.name,e_a.city,e_a.street
from employee e join employee_address e_a
on e.id =e_a.id;
隐式连接写法也可以达到相同的结果。(这个写法在mysql和oracle database也比较常见)
select e.id,e.name,e_a.city,e_a.street
from employee e , employee_address e_a
where e.id =e_a.id;
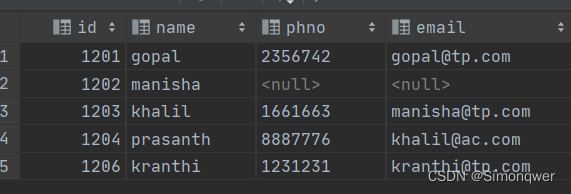
1.4.3 left join 左连接
- left join中文叫做是左外连接(Left Outer Join)或者左连接,其中outer可以省略,left outer join是早期的写法。
- left join的核心就在于left左。左指的是join关键字左边的表,简称左表。
- 通俗解释:join时以左表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关联不上的显示null返回。
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left join employee_connection e_conn
on e.id =e_conn.id;
2 Hive函数
2.1 概述
Hive内建了不少函数,用于满足用户不同使用需求,提高SQL编写效率:
- 使用show functions查看当下可用的所有函数;
- 通过describe function extended funcname来查看函数的使用方式。
2.2 分类标准
Hive的函数分为两大类:内置函数(Built-in Functions)、用户定义函数UDF(User-Defined Functions):
2.2.1 内置函数
内置函数可分为:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等;
2.2.2 用户定义函数UDF分类标准
用户定义函数根据输入输出的行数可分为3类:UDF、UDAF、UDTF。
根据函数输入输出的行数:
- UDF(User-Defined-Function)普通函数,一进一出
- UDAF(User-Defined Aggregation Function)聚合函数,多进一出
- UDTF(User-Defined Table-Generating Functions)表生成函数,一进多出
2.2.3 UDF分类标准扩大化
UDF分类标准本来针对的是用户自己编写开发实现的函数。UDF分类标准可以扩大到Hive的所有函数中:包括内置函数和用户自定义函数。
因为不管是什么类型的函数,一定满足于输入输出的要求,那么从输入几行和输出几行上来划分没有任何问题。
千万不要被UD(User-Defined)这两个字母所迷惑,照成视野的狭隘。
比如Hive官方文档中,针对聚合函数的标准就是内置的UDAF类型。
2.3 常用内置函数
内置函数(build-in)指的是Hive开发实现好,直接可以使用的函数,也叫做内建函数。
官方文档地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
内置函数根据应用归类整体可以分为8大种类型,我们将对其中重要的,使用频率高的函数使用进行详细讲解。
------------String Functions 字符串函数------------
select length("itcast");
select reverse("itcast");
select concat("angela","baby");
--带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)
select concat_ws('.', 'www', array('itcast', 'cn'));
--字符串截取函数:substr(str, pos[, len]) 或者 substring(str, pos[, len])
select substr("angelababy",-2); --pos是从1开始的索引,如果为负数则倒着数
select substr("angelababy",2,2);
--分割字符串函数: split(str, regex)
--split针对字符串数据进行切割 返回是数组array 可以通过数组的下标取内部的元素 注意下标从0开始的
select split('apache hive', ' ');
select split('apache hive', ' ')[0];
select split('apache hive', ' ')[1];
----------- Date Functions 日期函数 -----------------
--获取当前日期: current_date
select current_date();
--获取当前UNIX时间戳函数: unix_timestamp
select unix_timestamp();
--日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp("2011-12-07 13:01:03");
--指定格式日期转UNIX时间戳函数: unix_timestamp
select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss');
--UNIX时间戳转日期函数: from_unixtime
select from_unixtime(1618238391);
select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss');
--日期比较函数: datediff 日期格式要求'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'
select datediff('2012-12-08','2012-05-09');
--日期增加函数: date_add
select date_add('2012-02-28',10);
--日期减少函数: date_sub
select date_sub('2012-01-1',10);
----Mathematical Functions 数学函数-------------
--取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);
--指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926,4);
--取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
--指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);
-----Conditional Functions 条件函数------------------
--使用之前课程创建好的student表数据
select * from student limit 3;
--if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1=2,100,200);
select if(sex ='男','M','W') from student limit 3;
--空值转换函数: nvl(T value, T default_value)
select nvl("allen","itcast");
select nvl(null,"itcast");
--条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
select case sex when '男' then 'male' else 'female' end from student limit 3;
















 55
55











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









