







OpenAI Audio Models: Transcription and Voice-Generating AI
北京时间2025年3月21日凌晨,OpenAI宣布在语音技术领域实现重大突破,正式发布三款新模型:GPT-4o Transcribe、GPT-4o Mini Transcribe以及GPT-4o Mini TTS。这些模型为AI智能体带来了更自然流畅的语音交互能力,也意味着与上一代的Whisper模型相比,在处理复杂语音场景和输出个性化语音方面有了显著提升。
Open AI三款新语言模型介绍
一、GPT-4o Transcribe
-
高性能语音转文本
GPT-4o Transcribe在复杂环境(如嘈杂音、多口音、变速语音)下的转录准确度有了大幅提升。通过对超大规模音频数据进行训练,它能够更好地捕捉语音中的微小差异,显著降低了词错误率(WER)。
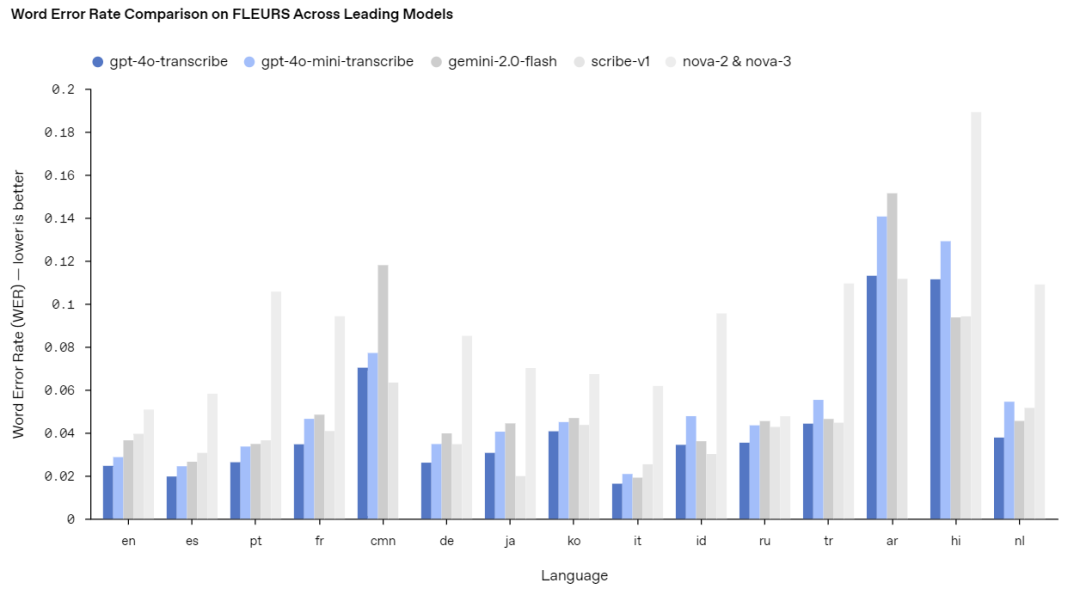
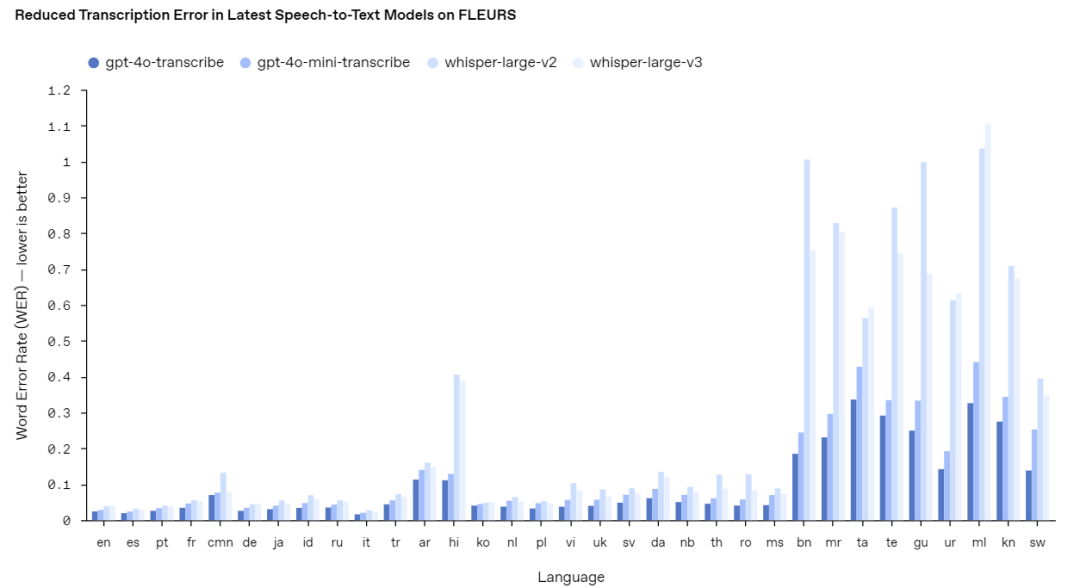
(WER 数值越低代表转录准确度越高)
最新语音转文本模型在 FLEURS 数据集上实现的转录错误率降低
-
多语言与多场景适配
该模型的训练语料包含各种语言、方言以及真实场景下的音频数据,因此在不同语言环境和行业领域中,都具备较高的适用性。对于需要高精准度的使用场景(如会议记录、法律文档、医学访谈等),GPT-4o Transcribe显然更具优势。
二、GPT-4o Mini Transcribe
-
轻量化设计
-
实时性与低资源占用
得益于模型小型化,它能够在资源有限的移动端或嵌入式设备上快速运行,兼顾实时性与准确度。在满足中等规模的语音转录需求方面更有弹性,并降低了部署成本。
-
广泛应用前景
对实时性要求较高的领域(如短语音命令、即时翻译、语音助手)可优先考虑Mini Transcribe,以便在保证准确度的同时提升用户体验。
三、GPT-4o Mini TTS
-
自然流畅的文本转语音
这款模型不仅在合成语音的清晰度和逼真度上表现突出,也能通过模拟人类发声特征,让转换后的语音听来更加自然。
-
可定制的情感与风格
对语调、情感和发音风格的精细化控制——可以让AI以“富有同情心的客服代表”、或“富有戏剧效果的故事讲述者”的口吻进行发声。这种定制化能力远超以往的TTS系统。 -
多语言、多角色支持
模型可生成多种不同性别、年龄甚至口音的语音,适合在客服热线、有声书、播客等场景进行更贴合用户或内容需求的个性化呈现。
总之,与上一代Whisper模型的对比,这三款新模型在识别准确度、性能与速度以及情感与个性化方面都有显著提升,无论是需要更精准的语音转录、多端高效的实时应用,还是对定制化语音风格的追求,都能获得更加出色的表现。
四、API & Agents SDK
目前已通过API向全球开发者开放,大家能够轻松地将语音功能集成到现有的应用中。
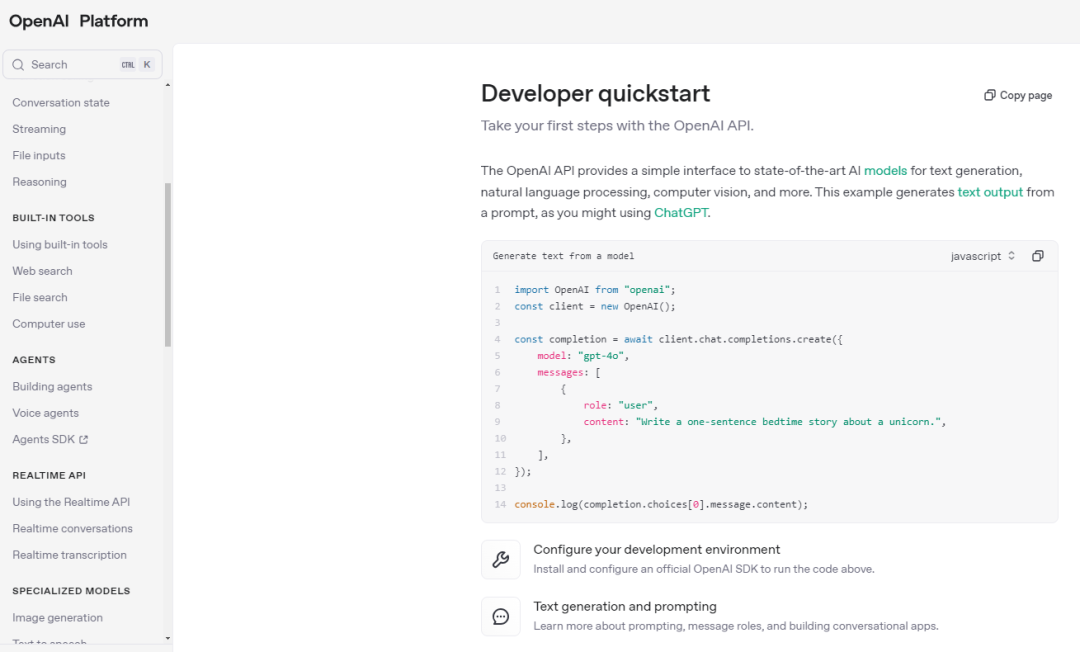
OpenAI还推出了更新的Agents SDK,简化了将文本智能体转换为语音智能体的过程。开发者可以通过仅几行代码就实现语音交互。

一直以来,Sinokap都紧随AI发展步伐,致力于为各行业提供ChatGPT培训与IT技术支持。关注我们!我们将持续为大家带来最新资讯与实战经验,帮助各行各业快速掌握并应用前沿AI技术。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









