







TLS1.3握手流程以及参数详解

TLS1.3总共有两层,分别是握手协议(handshake protocol)和记录协议(record protocol),握手协议在记录协议的上层,记录协议是一个分层协议。其中握手协议中还包括了警告协议(alert protocol)。本文将详细阐述握手协议,并且抓包分析。
我在一年前写了一篇介绍TLS1.3的文章,最近工作遇到了TLS1.3协议。重新复习了下。
这篇文章想详细的阐述交互过程,以及抓包分析参数的含义。
文章目录
- TLS1.3概述
- TLS1.3记录协议:
- TLS1.3警告协议:
- TLS1.3握手协议:
- 分析ClinetHello:
- 分析ServerHello:
- client的认证部分:
- 数据传输部分
TLS1.3概述
TLS1.3总共有两层,分别是握手协议(handshake protocol)和记录协议(record protocol),握手协议在记录协议的上层,记录协议是一个分层协议。其中握手协议中还包括了警告协议(alert protocol)。
TLS1.3概括如表格所示:
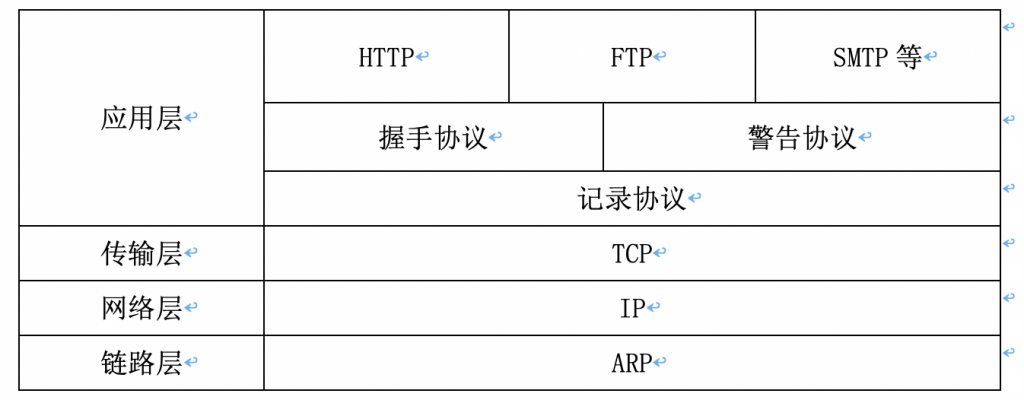
本文将详细阐述握手协议,并且抓包分析。
TLS1.3记录协议:
记录协议位于握手协议下层,发送方从高层接受任意长度的非空数据,对其进行合并或分块处理,然后利用带有辅助数据的认证加密AEAD(authenticated encryption with associated data)进行加密传输。
接收方接受数据后对其进行解密和验证,重组后再传送给高层用户。
TLS1.3警告协议:
目的是以简单的通知机制告知通信出现异常情况,警告消息通常会携带Close_notify异常,在连接关闭的时候报告错误,Alert_Level字段标识告警的严重程度,可取值Warning或者Fatal,严重程度为Fatal时会立即终止当前连接。
TLS1.3握手协议:
握手协议主要分为三个流程
- 密钥交换:选择TLS协议版本和加密的算法,并且协商算法所需的参数。这段是明文传输的
- 服务器参数:建立其他握手协议参数,例如是否需要认证客户端,支持何种应用层协议等。
- 认证:对服务器进行认证(包括可选的客户端认证)并且提供密钥确认和验证握手完整性功能。
这三个阶段完成后就可以进行应用层数据传输。
流程图如下所示:
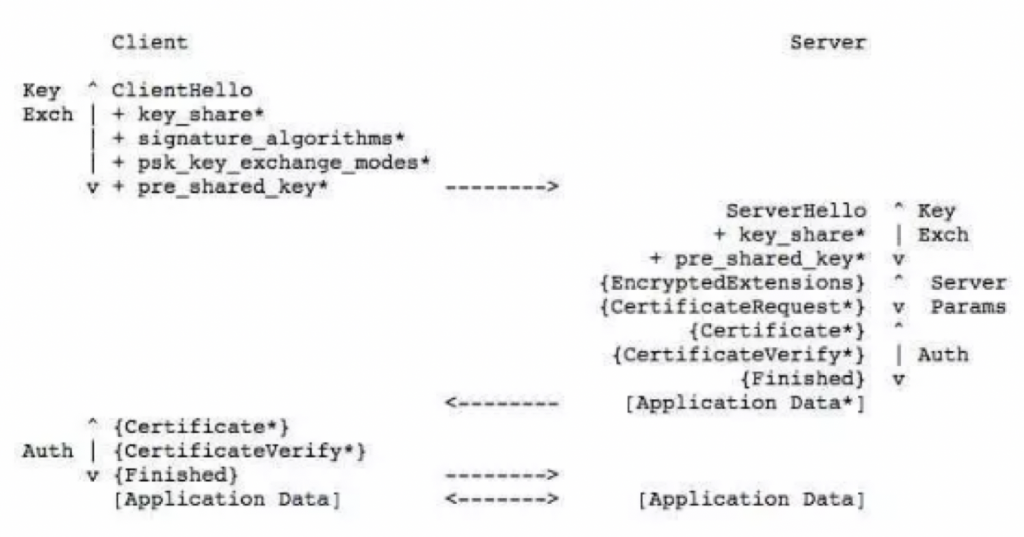
注:+:上一消息的扩展消息;*:可选发送
{}:用握手层流密钥加密;[]:用流密钥加密
TLS1.3的交互过程分为1-RTT,RTT是时延往返的意思。RTT越小速度越快。
在TLS1.2里交互过程需要2-RTT,可见TLS1.3加快了交互的速度。
正常连接(1-RTT)流程如下:
第1步,客户端发送 ClientHello 消息,该消息主要包括客户端支持的协议版本、会话ID、密码套件、压缩算法、以及扩展消息(密钥共享、预共享密钥、预共享密钥模式);
第2步,服务端回复 ServerHello,包含选定的加密套件;发送证书给客户端;使用证书对应的私钥对握手消息签名,将结果发送给客户端;选用客户端提供的参数生成临时公钥,结合选定的参数计算出用于加密 HTTP 消息的共享密钥;服务端生成的临时公钥通过 KeyShare 消息发送给客户端;
第3步,客户端接收到 KeyShare 消息后,使用证书公钥进行签名验证,获取服务器端的临时公钥,生成会话所需要的共享密钥;
第4步,双方使用生成的共享密钥对消息加密传输,保证消息安全。
简单的说就是:
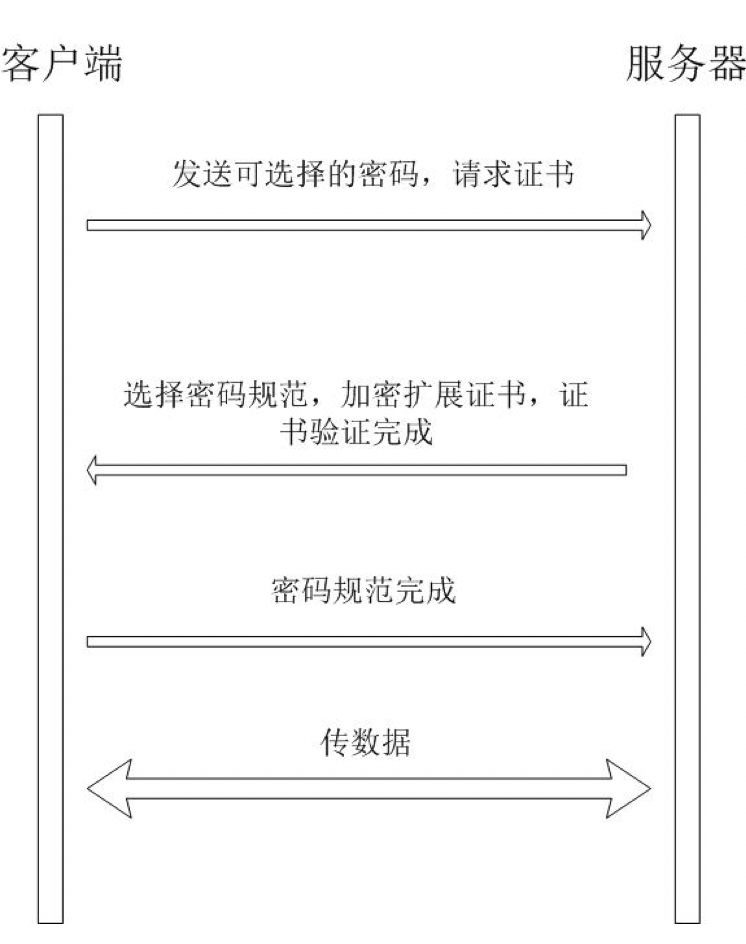
即4部分。ClientHello,SeverHello,Client认证,数据交互。
接下来分析这4个部分。
分析ClinetHello:
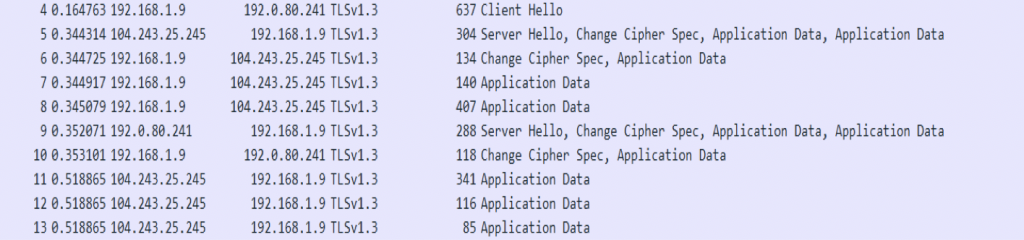
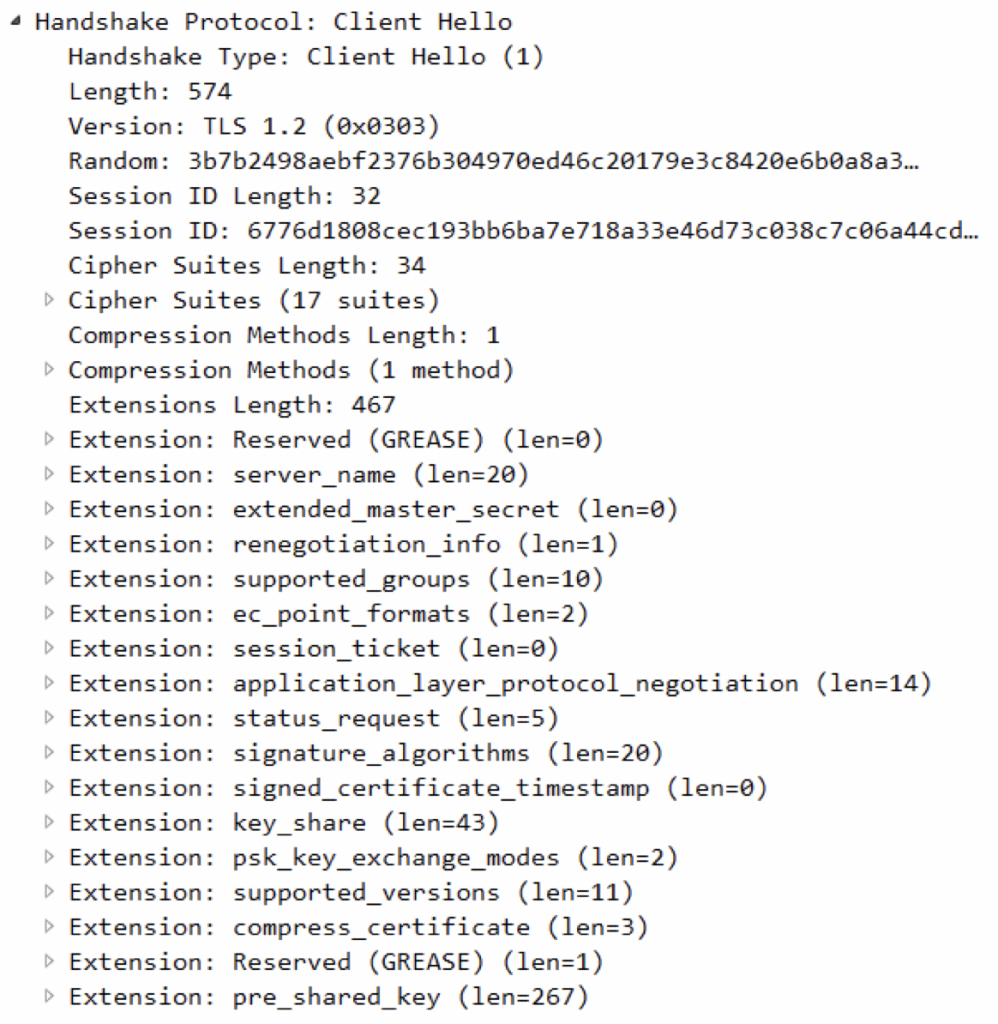
Handshake Type:ClientHello,表示握手消息类型,此处是ClientHelloLength:574,即长度为574Version:TLS1.2(0x0303),表示版本号为1.2,TLS1.3中规定此处必须置为0x0303,即TLS1.2,起到向后兼容的作用。1.3版本用来协商版本号的部分在扩展当中,而之前的版本就在此处进行。Random,随机数,是由安全随机数生成器生成的32个字节。Session ID Length:会话ID的长度。Session ID,会话ID,TLS 1.3之前的版本支持“会话恢复”功能,该功能已与1.3版本中的预共享密钥合并。为了兼容以前的版本,该字段必须是非空的,因此不提供TLS 1.3之前会话的客户端必须生成一个新的32字节值。该值不必是随机的,但应该是不可预测的,以避免实现固定在特定值,否则,必须将其设置为空。Cipher Suites Length,即下面Cipher Suites的长度
Cipher Suites是密码套件,表示客户端提供可选择的加密方式,如图所示:
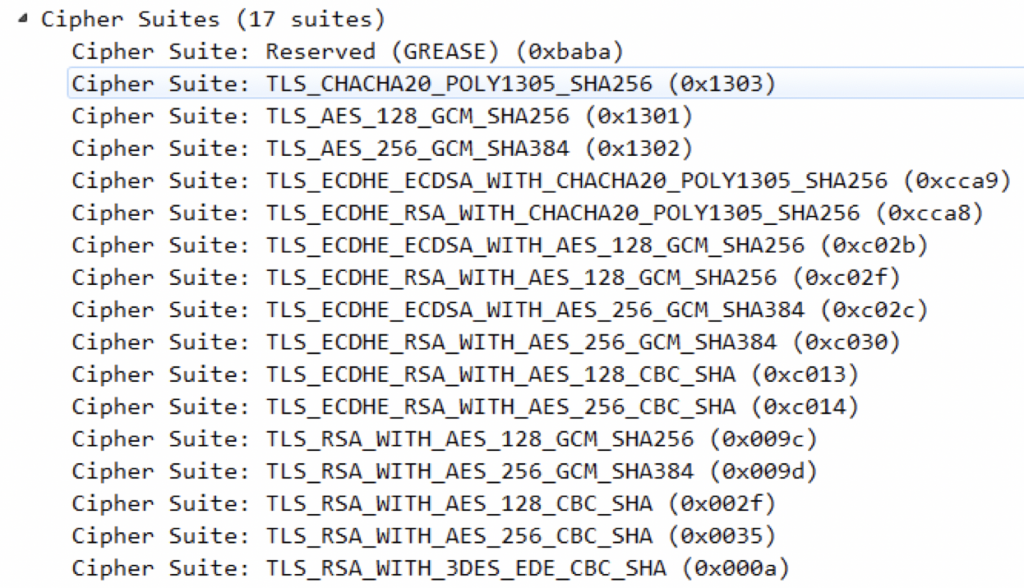
每个加密套件都包含,密钥交换,签名算法,加密算法,哈希算法。
Compression Methons (1 method)表示压缩方法,长度为1,内容为空
Exentisons扩展部分,是TLS1.3才开始使用,是TLS1.3的显著特征。每一个扩展都包含类型(type),长度(length)和数据(data)三个部分。
下面分析几个相对重要的扩展:
1)key_share
key_share 是椭圆曲线类型对应的公钥,如图所示
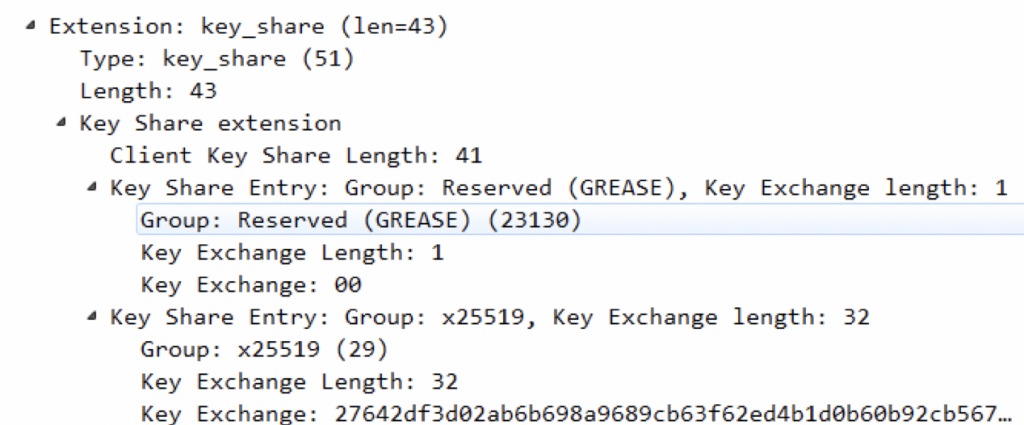
此处包含两个KeyShareEntry,第一个是预留的空值,第二个是x25519曲线组,具体数据在KeyExchange字段中;每个KeyShareEntry都代表一组密钥交换参数。
2)signature_algorithms
Signature_algorithms扩展是,客户端提供签名算法,让服务器选择

以第一个签名算法为例,ecdsa_secp256r1_sha256,使用sha256作为签名中的哈希,签名算法为ecdsa。
3)psk_key_exchange_modes
psk_key_exchange_modes是psk密钥交互模式选择

此处的PSK模式为(EC)DHE下的PSK,客户端和服务器必须提供KeyShare
如果是仅PSK模式,则服务器不需要提供KeyShare。
4)pre_shared_key
psk是预共享密钥认证机制,相当于session ticket再加一些检验的东西
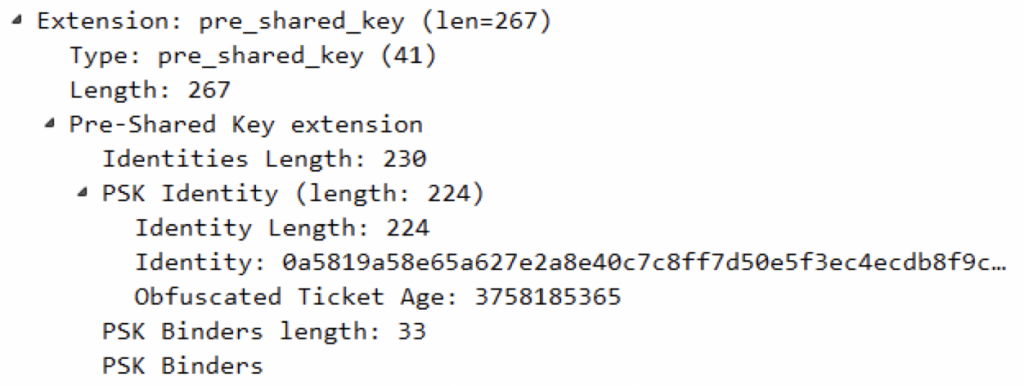
Identity中包含的是客户端愿意进行协商的服务器身份列表
PSK binder表示已经构建当前PSK与当前握手之间的绑定。
分析ServerHello:
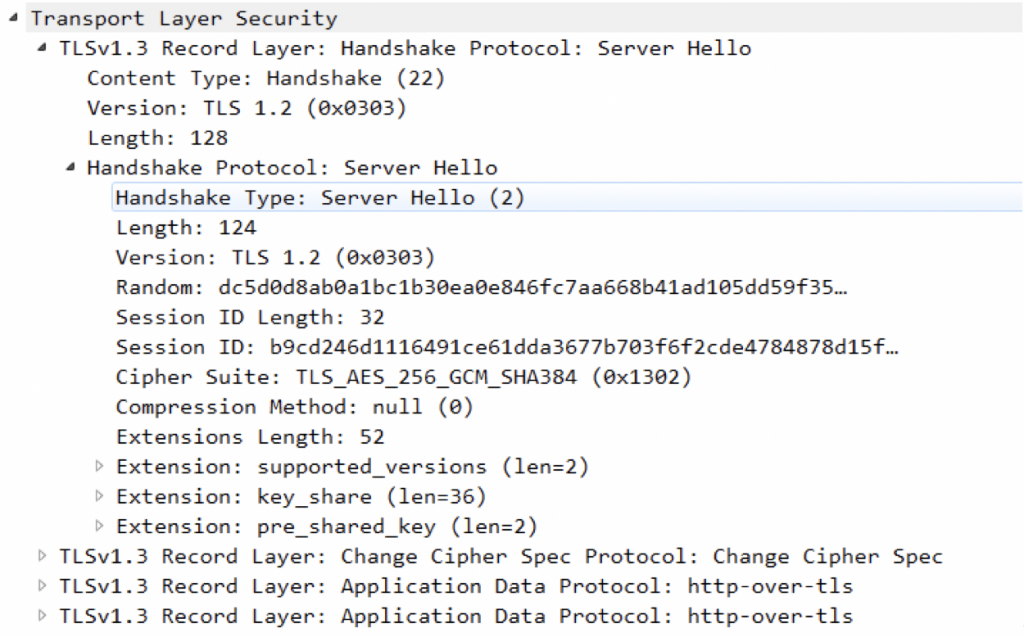
发现和ClientHello类似。
CkientHello提供加密方式的选择,而ServerHello实质是在Client提供的多种加密中选定加密的方式
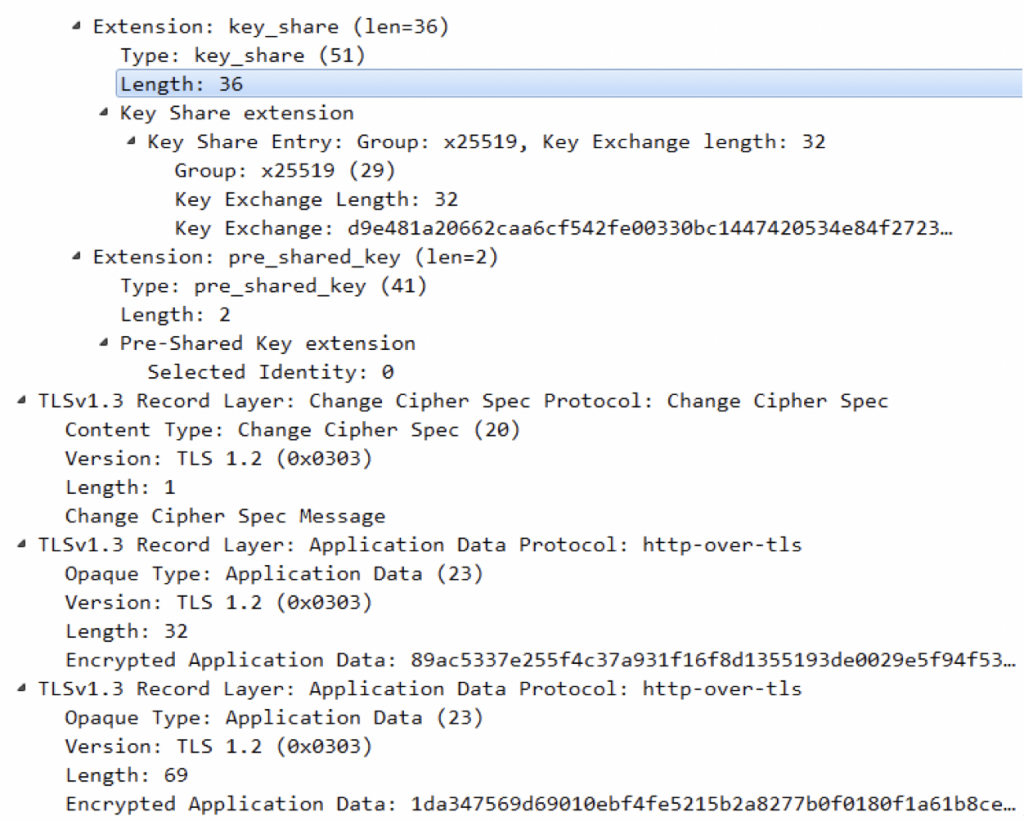
client的认证部分:
待到client认证完成,发送给服务端,至此建立连接,可以发送数据。
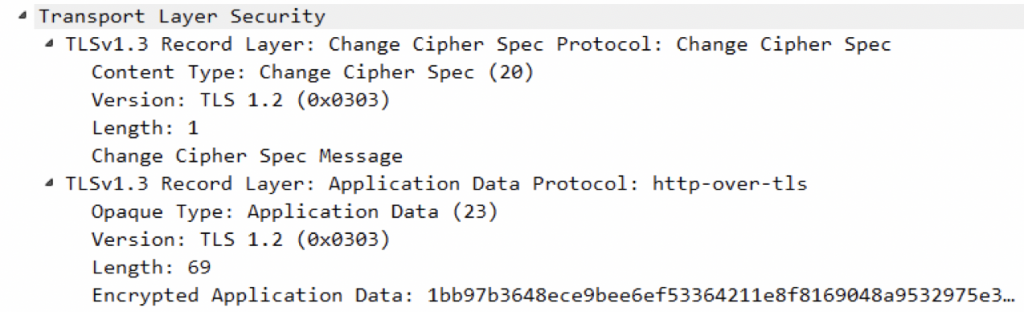
数据传输部分

可见数据经过TLS1.3加密,进行传输。
转载请注明:“转自绿盟科技博客”: 原文链接. http://blog.nsfocus.net/tls1-3protocol/

















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









