







平常心
昨天因为看小说不方便,所以拿python撸了个小说批量下载工具。为了大家方便所以打包成exe分享给大家。
可今天朋友就说了,这东西不能乱发,不论是各大盗版小说平台,还是淘宝上卖小说的店铺,触及了太多人的利益,这么做很危险。
果不其然,先后遇到了好几个陌生人,关注公众号回复关键字下载文件后立即取关…
只想说,你通过什么途径挣钱是你的事情,但请不要恶心我,谢谢。
今天说点什么?
中午和同事闲聊,说到我的大型情感剧集selenium太监了…其实不是不想写,主要是写了没人看,你愿意花时间去做无用功么?
在公司的博客,也同步更新着我公众号的文章,这两天有一个新的关注朋友,几乎每篇博客都评论,他在最后一篇selenium的文章说,还想看看剩余的内容,那今天就再更一篇吧。
网站登录
现在各大平台在反爬虫功能上,可谓花样繁多。总结下来按照破解成功率排名,最高的是滑动解锁、其次是验证码数字、之后是一次点击对应的汉字,最后是想12306之前那种反人类的让你说那些是奶糖吧,哈哈…
为什么我这么排序?很多人可能不赞同,认为验证码数字是最简单的…其实不然,因为验证码数字现在不仅是背景的色块,还穿插这很多混乱的线条,别说是系统识别,就是人仔细看都还会经常出错,所以成功率实在不高。至于滑动解锁,网上教程很多…剩下的两种就难度更高了…
那么如何能跳过这些步骤?在访问前添加cookie,是最简单粗暴的办法!
如何获取cookie
当我们成功登陆网址后,网站会将登陆验证信息保存在浏览器的Headers中,我们通过F12即可获取,但直接从headers中看是long long 的字符串不方便审查,所以切换到cookie栏,如下图:
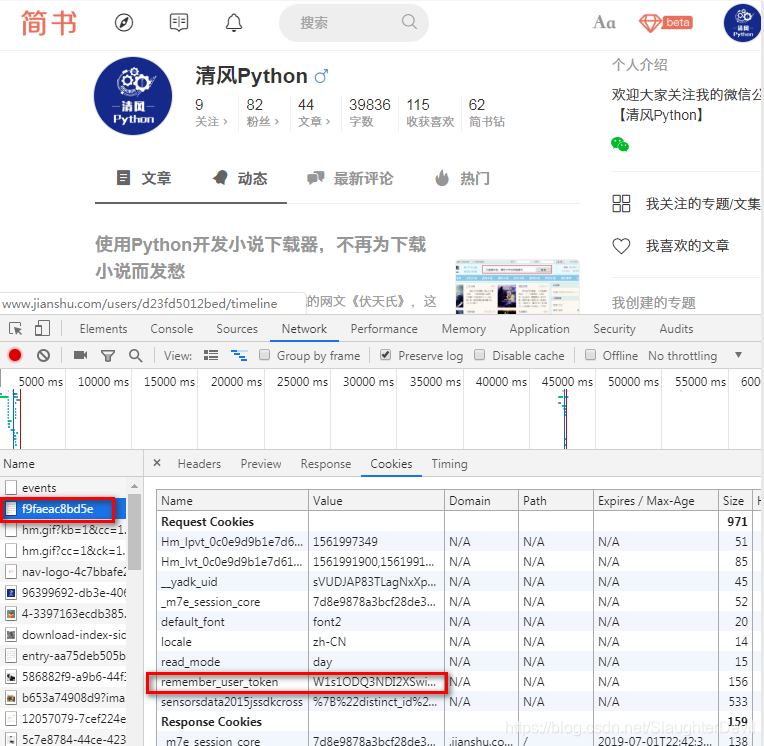 在cookie中不仅有登陆凭证,还会有很多其他网站附带的属性。此时需要我们过滤掉无关的数据,仅保存我们需要的内容即可。
在cookie中不仅有登陆凭证,还会有很多其他网站附带的属性。此时需要我们过滤掉无关的数据,仅保存我们需要的内容即可。
你问我怎么甄别?如简书这样的,什么local、read_mode、default_font肯定是打酱油的属性,没必要关注。
但上面的__yadk_uid等等的是否需要那就只能靠实验了…先只加token,不行再尝试添加其他的呗。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4522
4522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









