







安静的学习,真好
媳妇儿带着孩子去旅游,终于可以一个人听着陶喆的歌学习、写博客了,这感觉真好!(明天我媳妇儿看到文章,又要…)
今天早上收到了份哭笑不得的鼓励,一位朋友说我真勤劳,每天早上早起看一篇python文章,然后还发到朋友圈。
写公众号一个月了,每天早上朋友圈转发一下文章,算是我最大的推广了,然后被认为是我读别人的文章。
好吧,那我读文章的时候,比这个写文章的人时间不落分毫,哈哈。
说说selenium这个系列
这个大型情感剧集selenium系列,从开始做到现在第七集。一直在更新些零碎的知识,也没有系统的写过这方面代码。
很多朋友觉得这个系列的文章,就只是面向自动化测试去写的,其他人没必要看,学了没用。然后导致这个系列整体的阅读量炒鸡低!
那么今天,针对咱们之前学的只是,再补充一些,来做一个练习吧,名字就叫:**使用selenium,让整个简书网站都认识我!**张狂吧?其实开玩笑的,简书有安全回复机制,禁止短时间进行刷屏的…
通过这篇文章我想告诉你,任何人学selenium,都不是白费的!想做微商、推广的更应该关注我这篇文章,哈哈。
避坑指南与涉及知识点
大概罗列下场景覆盖中,涉及到的知识点
cookie登陆简书
本来想找个新账号的,但就我一个人,这会儿2点了朋友圈求不怕封想出名的账号,貌似也没结果
携带cookie登陆简书的方法,我上篇文章说了,就不再赘述了。
动态刷新简书首页文章链接
这里要详细说下简书的文章刷新方式…
- 进入简书进来后,默认展示10-15篇文章
- 页面下拉框滑动,会通过Ajax刷新文章,一次刷新5篇刷新3次
- 之后滑动刷新失效,需要点击“阅读更多”来获取新的文章
- 读取刷新日志,如该文章之前回复过,则跳过访问下一篇文章
- 这几种场景,我们可以通过js控制滚动条滑动到底部来实现刷新文章
- 通过try … except 判断是否出现阅读更多的文章来进行点击事件
- 通过link.text与我们之前保存的日志文件进行对比,判断新文章访问
- 点击链接会弹出新标签页,此处涉及标签切换、访问、关闭和主handle的返回
文章回复
本来这里没什么知识点的,但是简书做的比较溜,文章内容也是Ajax成段展示,刚进入页面无法后去到所有的内容,更没办法定位到回复栏
开始使用直接下拉到底部的方式,但这种方式依然无法获取所有内容及回复窗口
需要逐步刷新,加载所有内容后,才能显示回复栏…
for循环每次下拉500单位,最终得到文章内容的方式完成此方式
WebDriverWait(driver,totaltime,checksplit).until()
其实本来这里,用不到WebDriverWait的,这种一般都是在页面访问后,进行动态等待的,但咱们没这个场景就生硬的使用下吧…
设置刷新文章页数
根据想刷新的页数,来控制主页面进行多少次下拉框拖动和点击“阅读更多”…
最终结束时,将访问过的文章重新写入到日志文件中…
代码实现
由于cookie涉及到我的登陆验证,所有就在代码中隐藏了,如何获取,上篇文章说过了…
我习惯不太好,注释写的比较少,抱歉,有不清楚的可以微信问我…
# -*- coding: utf-8 -*-
# @Author : 王翔
# @JianShu : 清风Python
# @Date : 2019/7/4 02:19
# @Software : PyCharm
# @version :Python 3.7.3
# @File : Be_A_Famous.py
import time
import os
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException, \
ElementNotInteractableException, TimeoutException
class FamousPerson:
# 简书首页地址
BaseUrl = "https://www.jianshu.com"
# 脚本目录
BaseDir = os.path.dirname(os.path.realpath(__file__))
# 日志文件
text_name = 'comment.txt'
# 默认评论页面数
Page = 3
# 设置变量,定位已访问的文章数目
ContentNo = 0
def __init__(self):
self.log_text = os.path.join(self.BaseDir, self.text_name)
self.log_list = self.get_log()
self.driver = self.init_driver()
self.base_handle = None
self.note_list = []
def get_log(self):
if os.path.exists(self.log_text):
with open(self.log_text, 'r', encoding='utf-8') as f:
return f.readlines()
return []
@staticmethod
def init_driver():
"""
basic option:
set screen size
disable info bar
:return: driver
"""
options = webdriver.ChromeOptions()
options.add_argument('window-size=900,600')
options.add_argument('disable-infobars')
return webdriver.Chrome(options=options)
def prepare_work(self):
"""
1. add cookie
2. set base handle
"""
self.driver.get(self.BaseUrl)
self.driver.add_cookie(cookie)
self.driver.refresh()
self.base_handle = self.driver.current_window_handle
def control_scrollbar(self):
"""
use js to control scroll down ...
"""
_scrollTop = 0
# 渐进下拉,避免大幅度页面偏移,导致的textarea获取失败...
for i in range(20):
_scrollTop += 400
js = "var q=document.documentElement.scrollTop={}".format(_scrollTop)
self.driver.execute_script(js)
time.sleep(0.2)
# 简书AJax刷新3次后,必须点击一次查看更多,才能继续刷新...
try:
self.driver.find_element_by_class_name('load-more').click()
except NoSuchElementException:
pass
except ElementNotInteractableException:
pass
def add_comment(self):
# 判断窗口并切换
for handle in self.driver.window_handles:
if handle != self.base_handle:
self.driver.switch_to.window(handle)
print("访问文章:{}".format(self.driver.title))
# 滚动至页面底部
self.control_scrollbar()
try:
WebDriverWait(self.driver, 5, 0.5).until(
ec.presence_of_element_located((By.TAG_NAME, 'textarea')))
self.driver.find_element_by_tag_name('textarea').send_keys(comment_info)
self.driver.find_element_by_class_name('btn-send').click()
print("回复成功")
except TimeoutException:
print("回复失败,未找到textarea,蓝瘦...")
# 为展示效果,等待2秒,使用时可删除...
time.sleep(1)
self.driver.close()
# 切换至主窗口
self.driver.switch_to.window(self.base_handle)
def get_content(self):
while self.Page:
notes = self.driver.find_elements_by_css_selector('.note-list li')
for note in notes[self.ContentNo:]:
try:
note_link = note.find_element_by_tag_name('a')
note_name = note_link.text + '\n'
if note_name in self.log_list:
continue
self.log_list.append(note_name)
note_link.click()
time.sleep(1)
self.add_comment()
self.ContentNo += 1
except:
pass
self.Page -= 1
# 下拉刷新一次页面
self.control_scrollbar()
with open(self.log_text, 'w') as f:
f.writelines(self.log_list)
def run():
# 实例化方法
start_test = FamousPerson()
# add cookie set base_handle
start_test.prepare_work()
# 启动评论
start_test.get_content()
if __name__ == '__main__':
comment_info = ("为作者点赞! 小弟技术公众号 【清风Python】 刚刚创建,"
"欢迎大家关注,谢谢支持。")
cookie = {
'name': 'remember_user_token',
'value': 'token_value' # 练习时请自行获取,方法上篇文章写了
}
run()
代码执行效果
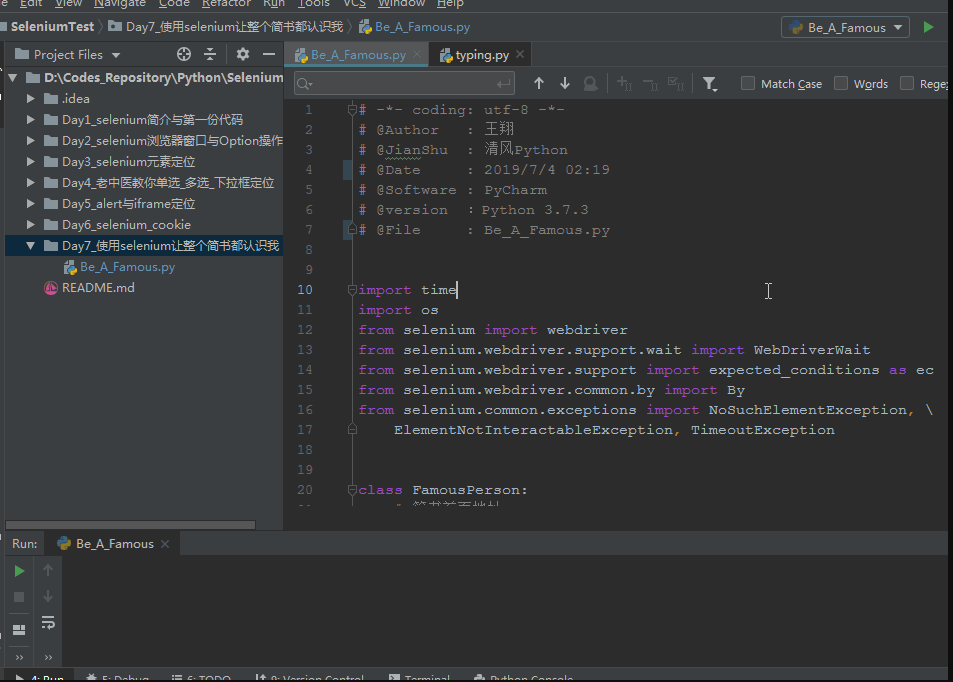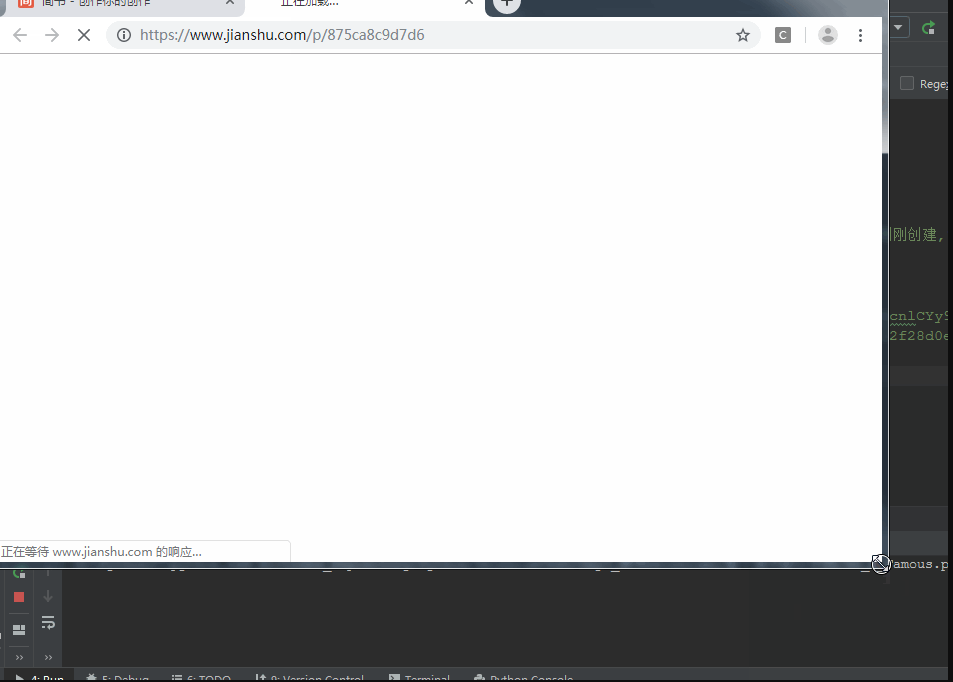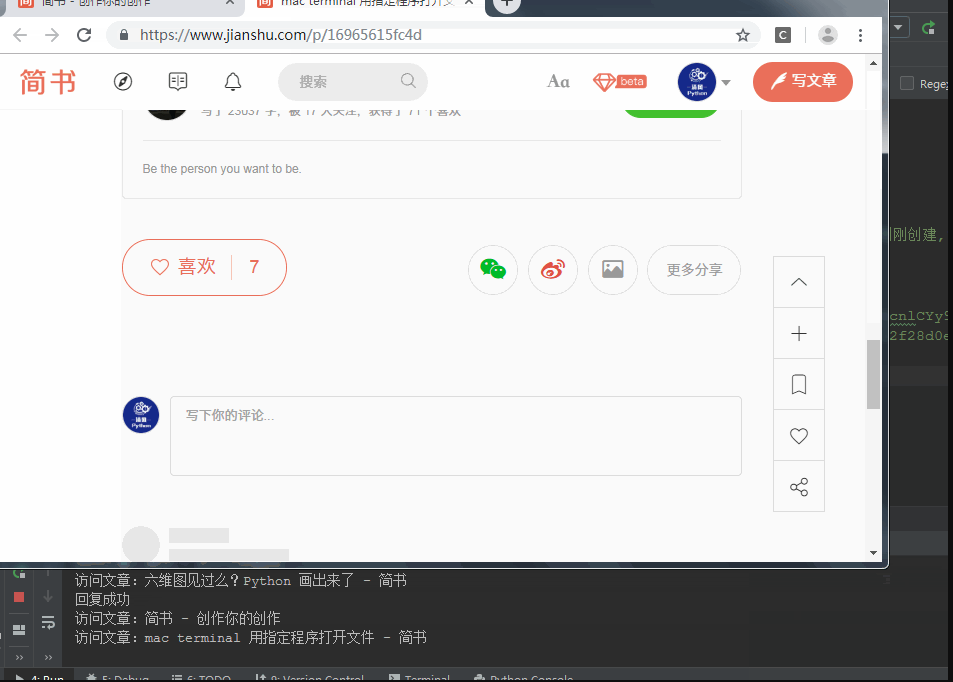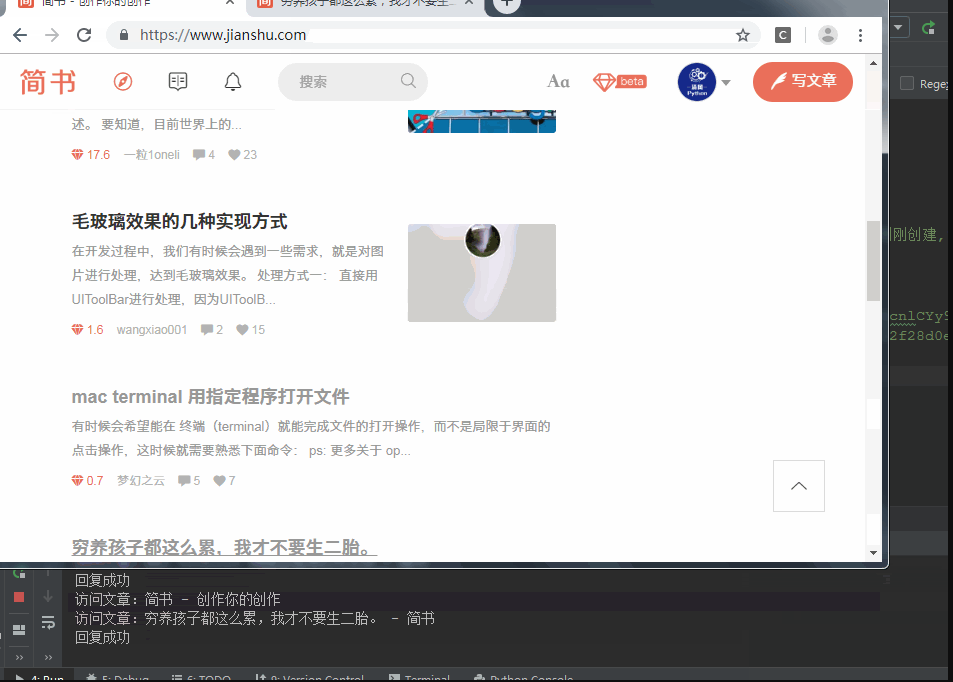
大家看到了间隔时间太短,连续回复,会被系统禁止操作…至于间隔多久,我只是为了写文章,就不去仔细考究了…
The End
今天的selenium内容就更新到这里,算是对之前知识的一个总结,和剩余内容的一个总体概括与练习吧。
其实selenium涉及的知识还有很多,以及与它相关的一些部署、搭建、自动化报告等等功能。但因为这个系列看的人实在太少,懒得更新了啊…
先暂时告一段落吧,如果还有人催更,我在想想下来写点什么吧。
OK,如果觉得这篇文章对你有帮助,欢迎将文章或我的微信公众号【清风Python】转发分享给更多喜欢python的朋友们,谢谢。















 1281
1281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









