






前言
Lucene 是一种高性能、可伸缩的信息搜索(IR)库,在 2000 年开源,最初由鼎鼎大名的 Doug Cutting 开发,是基于 Java 实现的高性能的开源项目。
Lucene 采用了基于倒排表的设计原理,可以非常高效地实现文本查找,在底层采用了分段的存储模式,使它在读写时几乎完全避免了锁的出现,大大提升了读写性能。
基本概念
在深入解读Lucene之前,先了解下Lucene的几个基本概念,以及这几个概念背后隐藏的一些东西。
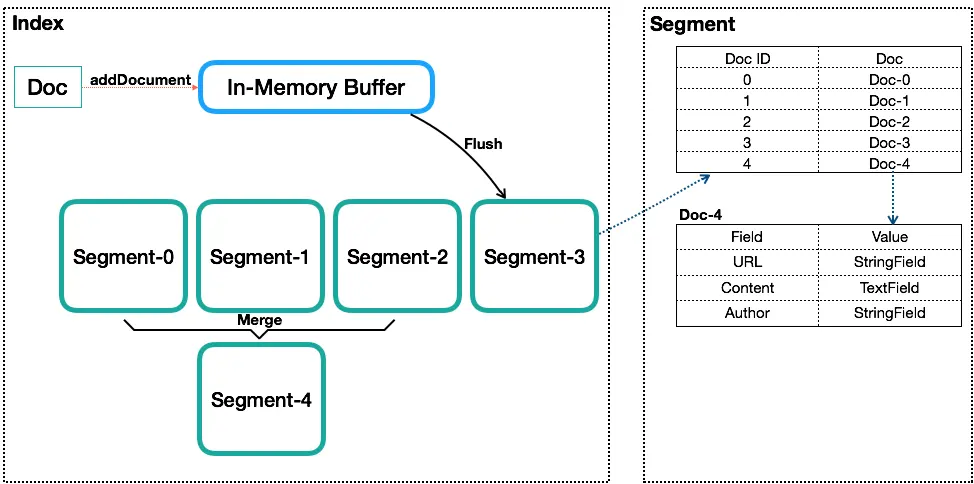
如图是一个Index内的基本组成,Segment内数据只是一个抽象表示,不代表其内部真实数据结构。
Index(索引)
类似数据库的表的概念,但是与传统表的概念会有很大的不同。传统关系型数据库或者NoSQL数据库的表,在创建时至少要定义表的Scheme,定义表的主键或列等,会有一些明确定义的约束。而Lucene的Index,则完全没有约束。Lucene的Index可以理解为一个文档收纳箱,你可以往内部塞入新的文档,或者从里面拿出文档,但如果你要修改里面的某个文档,则必须先拿出来修改后再塞回去。这个收纳箱可以塞入各种类型的文档,文档里的内容可以任意定义,Lucene都能对其进行索引。
Document(文档)
类似数据库内的行或者文档数据库内的文档的概念,一个Index内会包含多个Document。写入Index的Document会被分配一个唯一的ID,即Sequence Number(更多被叫做DocId),关于Sequence Number后面会再细说。
Field(字段)
一个Document会由一个或多个Field组成,Field是Lucene中数据索引的最小定义单位。Lucene提供多种不同类型的Field,例如StringField、TextField、LongFiled或NumericDocValuesField等,Lucene根据Field的类型(FieldType)来判断该数据要采用哪种类型的索引方式(Invert Index、Store Field、DocValues或N-dimensional等),关于Field和FieldType后面会再细说。
Term和Term Dictionary
Lucene中索引和搜索的最小单位,一个Field会由一个或多个Term组成,Term是由Field经过Analyzer(分词)产生。Term Dictionary即Term词典,是根据条件查找Term的基本索引。
词典的数据结构可以有很多种,每种都有自己的优缺点。
- 排序数组:排序数组通过二分查找来检索数据。
- HashMap(哈希表):比排序数组的检索速度更快,但是会浪费存储空间。
- FST(finite-state transducer):有更高的数据压缩率和查询效率,因为词典是常驻内存的,而 FST 有很好的压缩率,所以 FST 在 Lucene 的最新版本中有非常多的使用场景,也是默认的词典数据结构。
Segment
索引中最小的独立存储单元。
一个Index会由一个或多个sub-index构成,sub-index被称为Segment。Lucene的Segment设计思想,与LSM类似但又有些不同,继承了LSM中数据写入的优点,但是在查询上只能提供近实时而非实时查询。
Segment在Lucene中的段有不变性,也就是说段一旦生成,在其上只能有读操作,不能有写操作。
Lucene中的数据写入会先写内存的一个Buffer(类似LSM的MemTable,但是不可读),当Buffer内数据到一定量后会被flush成一个Segment,每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。这种模式避免了随机写,数据写入都是Batch和Append,能达到很高的吞吐量。Segment中写入的文档不可被修改,但可被删除,删除的方式也不是在文件内部原地更改,而是会由另外一个文件保存需要被删除的文档的DocID,保证数据文件不可被修改。Index的查询需要对多个Segment进行查询并对结果进行合并,还需要处理被删除的文档,为了对查询进行优化,Lucene会有策略对多个Segment进行合并,这点与LSM对SSTable的Merge类似。
Segment在被flush或commit之前,数据保存在内存中,是不可被搜索的,这也就是为什么Lucene被称为提供近实时而非实时查询的原因。原因是Lucene中数据搜索依赖构建的索引(例如倒排依赖Term Dictionary),Lucene中对数据索引的构建会在Segment flush时,而非实时构建,目的是为了构建最高效索引。当然它可引入另外一套索引机制,在数据实时写入时即构建,但这套索引实现会与当前Segment内索引不同,需要引入额外的写入时索引以及另外一套查询机制,有一定复杂度。
Sequence Number
Sequence Number(后面统一叫DocId)是Lucene中一个很重要的概念,数据库内通过主键来唯一标识一行,而Lucene的Index通过DocId来唯一标识一个Doc。不过有几点要特别注意:
DocId实际上并不在Index内唯一,而是Segment内唯一,Lucene这么做主要是为了做写入和压缩优化。那既然在Segment内才唯一,又是怎么做到在Index级别来唯一标识一个Doc呢?方案很简单,Segment之间是有顺序的,举个简单的例子,一个Index内有两个Segment,每个Segment内分别有100个Doc,在Segment内DocId都是0-100,转换到Index级的DocId,需要将第二个Segment的DocId范围转换为100-200。
DocId在Segment内唯一,取值从0开始递增。但不代表DocId取值一定是连续的,如果有Doc被删除,那可能会存在空洞。
一个文档对应的DocId可能会发生变化,主要是发生在Segment合并时。
Lucene内最核心的倒排索引,本质上就是Term到所有包含该Term的文档的DocId列表的映射。所以Lucene内部在搜索的时候会是一个两阶段的查询,第一阶段是通过给定的Term的条件找到所有Doc的DocId列表,第二阶段是根据DocId查找Doc。Lucene提供基于Term的搜索功能,也提供基于DocId的查询功能。
DocId采用一个从0开始底层的Int32值,是一个比较大的优化,同时体现在数据压缩和查询效率上。例如数据压缩上的Delta策略、ZigZag编码,以及倒排列表上采用的SkipList等。
Lucene的底层存储格式
Lucene 的底层存储格式如下图所示,由词典和倒排序两部分组成,其中的词典就是 Term 的集合
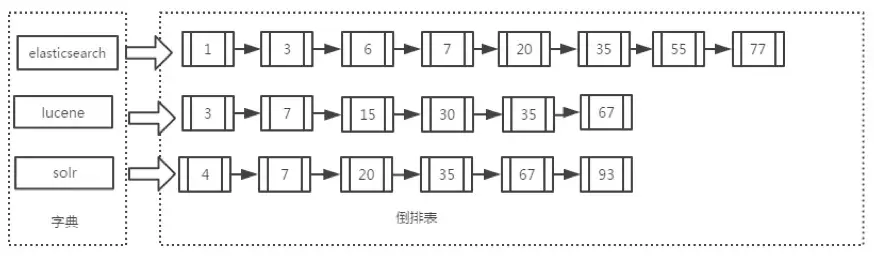
词典中的 Term 指向的文档链表的集合,叫做倒排表。词典和倒排表是 Lucene 中很重要的两种数据结构,是实现快速检索的重要基石。
词典和倒排表是分两部分存储的,在倒排表中不但存储了文档编号,还存储了文档id,词频,位置等信息。
Lucene 的查找过程中只需在词典中找到这些 Term,根据 Term 获得文档链表,然后根据具体的查询条件对链表进行交、并、差等操作,就可以准确地查到我们想要的结果。
Lucene读写流程
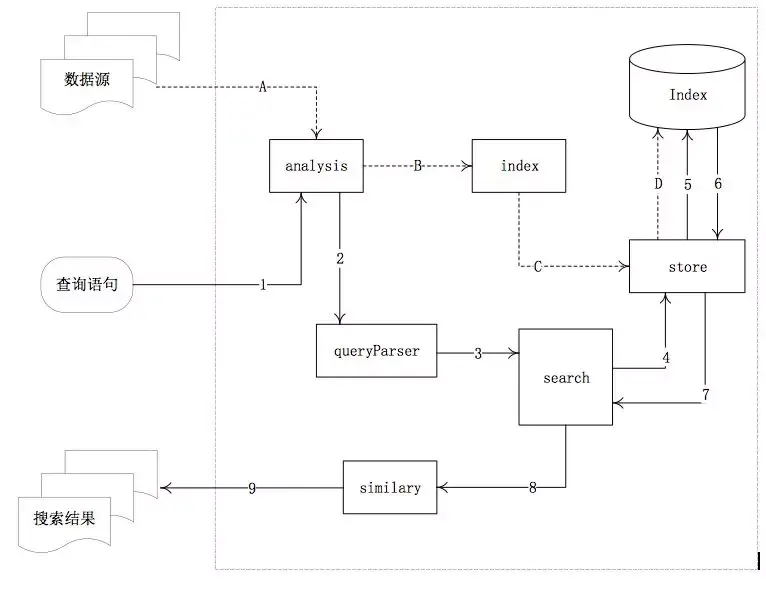
其中,虚线箭头(A、B、C、D)表示写索引的主要过程,实线箭头(1-9)表示查询的主要过程。
- analysis模块:主要负责词法分析及语言处理,也就是分词,形成存储或者搜索的最小单元Term。
- index模块:主要负责索引的创建工作。
- store模块:主要负责索引的读写。
- queryParser:主要负责语法分析,把查询语句生成Lucene底层可以识别的条件。
- search模块:主要负责对索引的搜索工作。
- similarity模块:主要负责相关性打分和排序的实现。
Lucene分段存储
前面已经介绍了Segment的概念,在分段的思想下,对数据写操作的过程如下。
新增:当有新的数据需要创建索引时,由于段的不变性,所以选择新建一个段来存储新增的数据。
删除:当需要删除数据时,由于数据所在的段只可读,不可写,所以Lucene在索引文件下新增了一个.del的文件,用来专门存储被删除的数据id。当查询时,被删除的数据还是可以被查到的,只是在进行文档链表合并时,才把已经删除的数据过滤掉。被删除的数据在进行段合并时才会真正被移除。
更新:更新的操作其实就是删除和新增的组合,先在.del文件中记录旧数据,再在新段中添加一条更新后的数据。
Segment的优点:
- 不需要锁。因为数据不会更新,所以不用考虑多线程下的读写不一致情况。
- 可以常驻内存。段在被加载到内存后,由于具有不变性,所以只要内存的空间足够大,就可以长时间驻存,大部分查询请求会直接访问内存,而不需要访问磁盘,使得查询的性能有很大的提升。
- 缓存友好。在段的声明周期内始终有效,不需要在每次数据更新时被重建。
- 增量创建。分段可以做到增量创建索引,可以轻量级地对数据进行更新,由于每次创建的成本很低,所以可以频繁地更新数据,使系统接近实时更新。
Segment的缺点:
- 当对数据进行删除时,旧数据不会被马上删除,而是在.del文件中被标记为删除。而旧数据只能等到段更新时才能真正被移除,这样会有大量的空间浪费。
- 更新。更新数据由删除和新增这两个动作组成。若有一条数据频繁更新,则会有大量的空间浪费。
- 由于索引具有不变性,所以每次新增数据时,都需要新增一个段来存储数据。当段的数量太多时,对服务器的资源的消耗会非常大,查询的性能也会受到影响。
- 在查询后需要对已经删除的旧数据进行过滤,这增加了查询的负担。
为了提升写的性能,Lucene并没有每新增一条数据就增加一个段,而是采用延迟写的策略,每当有新增的数据时,就将其先写入内存中,然后批量写入磁盘中。若有一个段被写到硬盘,就会生成一个提交点,提交点就是一个用来记录所有提交后的段信息的文件。一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限;相反,当段在内存中时,就只有写数据的权限,而不具备读数据的权限,所以也就不能被检索了。
延迟写的策略:Lucene默认是一秒钟,或者当内存中的数据量达到一定阶段时,再批量提交到磁盘中,当然,默认的时间和数据量的大小是可以通过参数控制的。通过延时写的策略,可以减少数据往磁盘上写的次数,从而提升整体的写入性能。
Segment合并策略
虽然分段比每次都全量创建索引有更高的效率,但由于在每次新增数据时都会新增一个段,所以经过长时间的积累,会导致在索引中存在大量的段,当索引中段的数量太多时,不仅会严重消耗服务器的资源,还会影响检索的性能。
因为索引检索的过程是:查询所有段中满足查询条件的数据,然后对每个段里查询的结果集进行合并,所以为了控制索引里段的数量,必须定期进行段合并操作。但是如果每次合并全部的段,则将造成很大的资源浪费,特别是“大段”的合并。
所以Lucene现在的段合并思路是:
根据段的大小先将段进行分组,再将属于同一组的段进行合并。但是由于对超级大的段的合并需要消耗更多的资源,所以Lucene会在段的大小达到一定规模,或者段里面的数据量达到一定条数时,不会再进行合并。所以Lucene的段合并主要集中在对中小段的合并上,这样既可以避免对大段进行合并时消耗过多的服务器资源,也可以很好地控制索引中段的数量。
段合并的主要参数如下:
mergeFactor:每次合并时参与合并的段的最少数量,当同一组的段的数量达到此值时开始合并,如果小于此值则不合并,这样做可以减少段合并的频率,其默认值为10。
SegmentSize:指段的实际大小,单位为字节。
minMergeSize:小于这个值的段会被分到一组,这样可以加速小片段的合并。
maxMergeSize:若一个段的文本数量大于此值,就不再参与合并,因为大段合并会消耗更多的资源。
段分组的步骤如下:
1.根据段生成的时间对段进行排序,然后根据上述标准化公式计算每个段的大小并且存放到段信息中,后面用到的描述段大小的值都是标准化后的值。
2.在数组中找到最大的段,然后生成一个由最大段的标准化值作为上限,减去LEVEL_LOG_SPAN(默认值为0.75)后的值作为下限的区间。小于等于上限并且大于下限的段,都被认为是属于同一个组的段,可以合并。
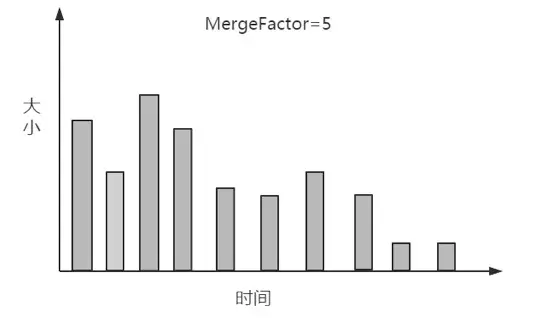
3.在确定一个分组的上下限值后,就需要查找属于这个分组的段了,具体过程是:创建两个指针start和end,start指向数组的第1个段,end指向第start+MergeFactor个段,然后从end逐个向前查找落在区间的段,当找到第1个满足条件的段时,则停止,并把当前段到start之间的段统一分到一个组,无论段的大小是否满足当前分组的条件。如图所示,第2个段明显小于该分组的下限,但还是被分到了这一组。
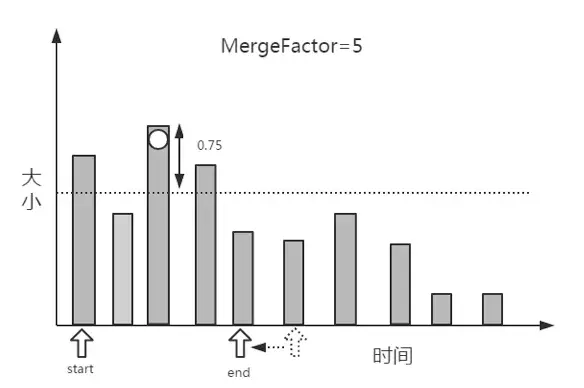
4.在分组找到后,需要排除不参加合并的“超大”段,然后判断剩余的段是否满足合并的条件,如图10所示,mergeFactor=5,而找到的满足合并条件的段的个数为4,所以不满足合并的条件,暂时不进行合并,继续寻找下一个分组的上下限。
5.由于在第4步并没有找到满足段合并的段的数量,所以这一分组的段不满足合并的条件,继续进行下一分组段的查找。具体过程是:将start指向end,在剩下的段(从end指向的元素开始到数组的最后一个元素)中寻找最大的段,在找到最大的值后再减去LEVEL_LOG_SPAN的值,再生成一个分组的区间值;然后把end指向数组的第start+MergeFactor个段,逐个向前查找第1个满足条件的段;重复第3步和第4步。
6.如果一直没有找到满足合并条件的段,则一直重复第5步,直到遍历完整个数组。
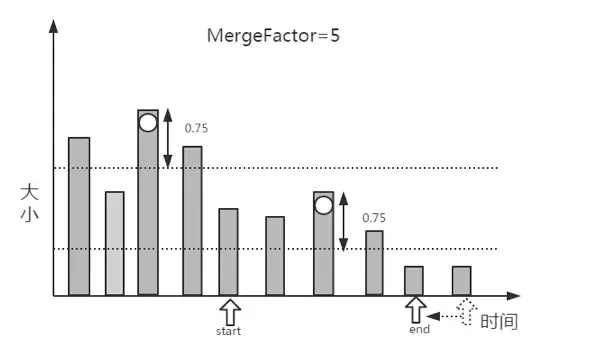
在找到满足条件的mergeFactor个段时,就需要开始合并了。但是在满足合并条件的段大于mergeFactor时,就需要进行多次合并,也就是说每次依然选择mergeFactor个段进行合并,直到该分组的所有段合并完成,再进行下一分组的查找合并操作。
通过上述几步,如果找到了满足合并要求的段,则将会进行段的合并操作。因为索引里面包含了正向信息和反向信息,所以段合并的操作分为两部分:一个是正向信息合并,例如存储域、词向量、标准化因子等;二个是反向信息的合并,例如词典、倒排表等。在段合并时,除了需要对索引数据进行合并,还需要移除段中已经删除的数据。















 6050
6050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









