







并查集算法最全最详细讲解
1.并查集介绍:
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题
例如: 给我们一个图结构,其中存在六个顶点: 1,2,3,4,5,6,我们要求将相连或者间接相连的顶点进行分组保存,此时,就需要使用到并查集,它的主要方法有两个:
(1) union(x,y) : 合并两个顶点的方法
(2)find_parent(x): 查找x顶点的父节点的方法
我们进行以下图解分析并查集的使用:
图解分析并查集:


并查集数据结构通用模板java代码实现:
class DisjointedSet {
//定义一个数组parent[]: 用于记录该节点的父节点,使得所有相关的节点位于同一个连通图中
int[] parent;
//定义一个数组rank[]: 主要用于优化,在合并两个父节点的时候,通过rank的大小判断谁是父节点,谁是子节点
int[] rank;
int count; //记录并查集的个数
//构造方法
public DisjointedSet(int n) {
this.parent = new int[n];
this.rank = new int[n];
this.count = n;
//我们选择将初始化的parent[]数组和rank数组的值设置为索引i本身
for (int i = 0; i < n; i++) {
this.parent[i] = i;
this.rank[i] = i;
}
}
//合并两个节点的方法
public boolean union(int x, int y) {
//找出x节点和y节点的根节点
int rootX = find(x);
int rootY = find(y);
//如果x的根节点和y的根节点相同:则说明已经合并了,直接返回即可
if (rootX == rootY) {
return false;
}
//此时表示x的根节点和y的根节点是不同的:我们需要利用rank[]数组进行优化
if (rank[rootX] == rank[rootY]) {
parent[rootX] = rootY;
// 此时以rootY为根结点的树的高度仅加了 1
rank[rootY]++;
} else if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
// 此时以 rootY 为根结点的树的高度不变
} else {
// 同理,此时以 rootX 为根结点的树的高度不变
parent[rootY] = rootX;
}
//此时将count数量减1
count--;
return true;
}
//查找当前x节点的父节点的方法
public int find(int x) {
//如果当前节点x的根节点不是其本身:
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
//如果当前节点x的根节点是其本身,则说明该点是独立的,我们直接返回x,即x的根节点parent[x]
return parent[x];
}
//判断两个节点的父节点是否一致的方法
public boolean isConnected(int x , int y) {
int Root_X = find(x);
int Root_Y = find(y);
return Root_X == Root_Y;
}
//返回并查集个数的方法
public int getCount() {
return count;
}
}
//注意:count属性:记录并查集的数量[非必要],根据实际情况进行添加
2.并查集LeetCode初识题目篇
第一题: LeetCode200题. 岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出:1
示例 2:
输入:grid = [
["1","1","0","0","0"],
["1","1","0","0","0"],
["0","0","1","0","0"],
["0","0","0","1","1"]
]
输出:3
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]的值为'0'或'1'
第二题: LeetCode第323题.无向图中连通分量的数目(并查集)[Plus会员问题,做的时候告诉我,我去开通一下会员_]
给定编号从 0 到 n-1 的 n 个节点和一个无向边列表(每条边都是一对节点),请编写一个函数来计算无向图中连通分量的数目。
示例 1:
输入: n = 5 和 edges = [[0, 1], [1, 2], [3, 4]]
0 3
| |
1 --- 2 4
输出: 2
示例 2:
输入: n = 5 和 edges = [[0, 1], [1, 2], [2, 3], [3, 4]]
0 4
| |
1 --- 2 --- 3
输出: 1
注意:
你可以假设在 edges 中不会出现重复的边。
而且由于所以的边都是无向边,[0, 1] 与 [1, 0] 相同,所以它们不会同时在 edges 中出现。
第三题: LeetCode第1202题.交换字符串的位置问题
给你一个字符串 s,以及该字符串中的一些「索引对」数组 pairs,其中 pairs[i] = [a, b] 表示字符串中的两个索引(编号从 0 开始)。
你可以 任意多次交换 在 pairs 中任意一对索引处的字符。
返回在经过若干次交换后,s 可以变成的按字典序最小的字符串。
示例 1:
输入:s = "dcab", pairs = [[0,3],[1,2]]
输出:"bacd"
解释:
交换 s[0] 和 s[3], s = "bcad"
交换 s[1] 和 s[2], s = "bacd"
示例 2:
输入:s = "dcab", pairs = [[0,3],[1,2],[0,2]]
输出:"abcd"
解释:
交换 s[0] 和 s[3], s = "bcad"
交换 s[0] 和 s[2], s = "acbd"
交换 s[1] 和 s[2], s = "abcd"
示例 3:
输入:s = "cba", pairs = [[0,1],[1,2]]
输出:"abc"
解释:
交换 s[0] 和 s[1], s = "bca"
交换 s[1] 和 s[2], s = "bac"
交换 s[0] 和 s[1], s = "abc"
提示:
1 <= s.length <= 10^50 <= pairs.length <= 10^50 <= pairs[i][0], pairs[i][1] < s.lengths中只含有小写英文字母
第四题: 面试题 17.07. 婴儿名字
每年,政府都会公布一万个最常见的婴儿名字和它们出现的频率,也就是同名婴儿的数量。有些名字有多种拼法,例如,John 和 Jon 本质上是相同的名字,但被当成了两个名字公布出来。给定两个列表,一个是名字及对应的频率,另一个是本质相同的名字对。设计一个算法打印出每个真实名字的实际频率。注意,如果 John 和 Jon 是相同的,并且 Jon 和 Johnny 相同,则 John 与 Johnny 也相同,即它们有传递和对称性。
在结果列表中,选择字典序最小的名字作为真实名字。
示例:
输入:names = ["John(15)","Jon(12)","Chris(13)","Kris(4)","Christopher(19)"], synonyms = ["(Jon,John)","(John,Johnny)","(Chris,Kris)","(Chris,Christopher)"]
输出:["John(27)","Chris(36)"]
提示:
names.length <= 100000
第五题: LeetCode684 冗余连接
在本问题中, 树指的是一个连通且无环的无向图。
输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, …, N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v] ,满足 u < v,表示连接顶点u 和v的无向图的边。
返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边 [u, v] 应满足相同的格式 u < v。
示例 1:
输入: [[1,2], [1,3], [2,3]]
输出: [2,3]
解释: 给定的无向图为:
1
/ \
2 - 3
示例 2:
输入: [[1,2], [2,3], [3,4], [1,4], [1,5]]
输出: [1,4]
解释: 给定的无向图为:
5 - 1 - 2
| |
4 - 3
注意:
- 输入的二维数组大小在 3 到 1000。
- 二维数组中的整数在1到N之间,其中N是输入数组的大小。
更新(2017-09-26):
我们已经重新检查了问题描述及测试用例,明确图是***无向*** 图。对于有向图详见**冗余连接II。**对于造成任何不便,我们深感歉意。
第六题: 947. 移除最多的同行或同列石头
n 块石头放置在二维平面中的一些整数坐标点上。每个坐标点上最多只能有一块石头。
如果一块石头的 同行或者同列 上有其他石头存在,那么就可以移除这块石头。
给你一个长度为 n 的数组 stones ,其中 stones[i] = [xi, yi] 表示第 i 块石头的位置,返回 可以移除的石子 的最大数量。
示例 1:
输入:stones = [[0,0],[0,1],[1,0],[1,2],[2,1],[2,2]]
输出:5
解释:一种移除 5 块石头的方法如下所示:
1. 移除石头 [2,2] ,因为它和 [2,1] 同行。
2. 移除石头 [2,1] ,因为它和 [0,1] 同列。
3. 移除石头 [1,2] ,因为它和 [1,0] 同行。
4. 移除石头 [1,0] ,因为它和 [0,0] 同列。
5. 移除石头 [0,1] ,因为它和 [0,0] 同行。
石头 [0,0] 不能移除,因为它没有与另一块石头同行/列。
示例 2:
输入:stones = [[0,0],[0,2],[1,1],[2,0],[2,2]]
输出:3
解释:一种移除 3 块石头的方法如下所示:
1. 移除石头 [2,2] ,因为它和 [2,0] 同行。
2. 移除石头 [2,0] ,因为它和 [0,0] 同列。
3. 移除石头 [0,2] ,因为它和 [0,0] 同行。
石头 [0,0] 和 [1,1] 不能移除,因为它们没有与另一块石头同行/列。
示例 3:
输入:stones = [[0,0]]
输出:0
解释:[0,0] 是平面上唯一一块石头,所以不可以移除它。
提示:
1 <= stones.length <= 10000 <= xi, yi <= 10^4- 不会有两块石头放在同一个坐标点上
第七题: 721. 账户合并
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该账户的邮箱地址。
现在,我们想合并这些账户。如果两个账户都有一些共同的邮箱地址,则两个账户必定属于同一个人。请注意,即使两个账户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的账户,但其所有账户都具有相同的名称。
合并账户后,按以下格式返回账户:每个账户的第一个元素是名称,其余元素是按顺序排列的邮箱地址。账户本身可以以任意顺序返回。
示例 1:
输入:
accounts = [["John", "johnsmith@mail.com", "john00@mail.com"], ["John", "johnnybravo@mail.com"], ["John", "johnsmith@mail.com", "john_newyork@mail.com"], ["Mary", "mary@mail.com"]]
输出:
[["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'], ["John", "johnnybravo@mail.com"], ["Mary", "mary@mail.com"]]
解释:
第一个和第三个 John 是同一个人,因为他们有共同的邮箱地址 "johnsmith@mail.com"。
第二个 John 和 Mary 是不同的人,因为他们的邮箱地址没有被其他帐户使用。
可以以任何顺序返回这些列表,例如答案 [['Mary','mary@mail.com'],['John','johnnybravo@mail.com'],
['John','john00@mail.com','john_newyork@mail.com','johnsmith@mail.com']] 也是正确的。
提示:
accounts的长度将在[1,1000]的范围内。accounts[i]的长度将在[1,10]的范围内。accounts[i][j]的长度将在[1,30]的范围内。
第八题: 1584. 连接所有点的最小费用
给你一个points 数组,表示 2D 平面上的一些点,其中 points[i] = [xi, yi] 。
连接点 [xi, yi] 和点 [xj, yj] 的费用为它们之间的 曼哈顿距离 :|xi - xj| + |yi - yj| ,其中 |val| 表示 val 的绝对值。
请你返回将所有点连接的最小总费用。只有任意两点之间 有且仅有 一条简单路径时,才认为所有点都已连接。
示例 1:


输入:points = [[0,0],[2,2],[3,10],[5,2],[7,0]]
输出:20
解释:
我们可以按照上图所示连接所有点得到最小总费用,总费用为 20 。
注意到任意两个点之间只有唯一一条路径互相到达。
示例 2:
输入:points = [[3,12],[-2,5],[-4,1]]
输出:18
示例 3:
输入:points = [[0,0],[1,1],[1,0],[-1,1]]
输出:4
示例 4:
输入:points = [[-1000000,-1000000],[1000000,1000000]]
输出:4000000
示例 5:
输入:points = [[0,0]]
输出:0
提示:
1 <= points.length <= 1000-106 <= xi, yi <= 106- 所有点
(xi, yi)两两不同。
3.初识题目解析篇
第一题题解:
使用DFS进行求解更方便:
java代码实现:
//使用dfs方法进行求解...
public int numIslands(char[][] grid) {
if (grid == null || grid.length == 0)
return 0;
//定义count计数器: 记录grad中岛屿的个数
int count = 0;
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[0].length; j++) {
if (grid[i][j] == '1') {
//将count的数量加1
count++;
dfs(grid,i,j);
}
}
}
return count;
}
private void dfs(char[][] grid, int i, int j) {
if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == '0') {
return;
}
grid[i][j] = '0';
dfs(grid,i - 1,j);
dfs(grid,i + 1,j);
dfs(grid,i,j - 1);
dfs(grid,i,j + 1);
}
JavaScript代码实现:
第二题题解:
会员题目,未解锁!
第三题题解:
分析一下我们的示例如下所示:

第 1 步:先遍历 pairs 中的索引对,将索引对中成对的索引输入并查集,并查集会帮助我们实现同属于一个连通分量中的元素的合并工作。注意:并查集管理的是「索引」不是「字符」。

第 2 步:遍历输入字符串 s,对于每一个索引,找到这个索引在并查集中的代表元,把同属于一个代表元的字符放在一起。这一步需要建立一个映射关系。键:并查集中的代表元,值:同属于一个代表元的 s 中的字符。可以使用哈希表建立映射关系。

第 3 步:分组排序。即对同属于一个连通分量中的字符进行排序。

这一步实现可以这样做:重新生成一个长度和 s 相同的字符串,对于每一个索引,查询索引在并查集中的代表元,再从哈希表中获得这个代表元对应的字符集列表,从中移除 ASCII 值最小的字符依次拼接起来。
这一步我们每一次需要从一个集合中选出 ASCII 值最小的字符,选出以后不再用它,带排序功能的集合有「平衡树(二叉搜索树)」和「优先队列(堆)」等,可以使用「优先队列」。
java代码实现:
public String smallestStringWithSwaps(String s, List<List<Integer>> pairs) {
//如果pairs为null或者pairs的长度为0: 则直接返回s
if (pairs == null || pairs.size() == 0) return s;
//第一步: 我们将任意交换的节点对输入到并查集中
int n = s.length();
UnionFind unionFind = new UnionFind(n);
for (List<Integer> pair : pairs) {
int left = pair.get(0);
int right = pair.get(1);
unionFind.union(left,right);
}
//第二步: 构建映射关系
char[] charArray = s.toCharArray();
//创建一个map集合: key表示连通分量的代表元,value表示同一个连通分量的字符集合
//将字符集合保存在一个优先队列中
Map<Integer, PriorityQueue<Character>> map = new HashMap<>(n);
for (int i = 0; i < n; i++) {
int root = unionFind.find(i);
if (map.containsKey(root)) {
//offer()方法
map.get(root).offer(charArray[i]);
}else {
PriorityQueue<Character> queue = new PriorityQueue<>();
//优先队列的offer方法:按照元素大小进行添加:加acdb,使用offer()方法添加以后为abcd
queue.offer(charArray[i]);
map.put(root,queue);
}
}
//第三步: 重组字符串
StringBuilder ans = new StringBuilder();
for (int i = 0; i < n; i++) {
int root = unionFind.find(i);
ans.append(map.get(root).poll());
}
return ans.toString();
}
//我们需要定义并查集的数据结构
class UnionFind {
//定义一个数组parent[]: 用于记录该节点的父节点,使得所有相关的节点位于同一个连通图中
int[] parent;
//定义一个数组rank[]: 主要用于优化,在合并两个父节点的时候,通过rank的大小判断谁是父节点,谁是子节点
int[] rank;
//构造方法
public UnionFind(int n) {
this.parent = new int[n];
this.rank = new int[n];
for (int i = 0; i < n; i++) {
this.parent[i] = i;
this.rank[i] = i;
}
}
//合并两个父节点的方法
public void union(int x, int y) {
//找出x节点和y节点的根节点
int rootX = find(x);
int rootY = find(y);
//如果x的根节点和y的根节点相同:则说明已经合并了,直接返回即可
if (rootX == rootY) {
return;
}
//此时表示x的根节点和y的根节点是不同的:我们需要利用rank[]数组进行优化
if (rank[rootX] == rank[rootY]) {
parent[rootX] = rootY;
// 此时以rootY为根结点的树的高度仅加了 1
rank[rootY]++;
} else if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
// 此时以 rootY 为根结点的树的高度不变
} else {
// 同理,此时以 rootX 为根结点的树的高度不变
parent[rootY] = rootX;
}
}
//查找方法
public int find(int x) {
//如果当前节点x的根节点不是其本身:
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
//如果当前节点x的根节点是其本身,则说明该点是独立的,我们直接返回x,即x的根节点parent[x]
return parent[x];
}
}
JavaScript代码实现:
第四题题解:
请把你自己写的并查集思路写在这里吧…我的小公主_
java代码实现:
private int[] parent;//定义并查集的parent数组
//其中name_id和id_name的value和key值分别为对应的索引位置
private Map<String,Integer> name_id = new HashMap<>();
private Map<Integer,String> id_name = new HashMap<>();
private Map<String,Integer> freMap = new HashMap<>();
//使用并查集进行求解:
public String[] trulyMostPopular(String[] names, String[] synonyms) {
//获取names数组的长度n
int n = names.length;
parent = new int[n];
//我们进行初始化工作:先将每一个顶点的根节点定义为其本身
//我们将names数组中名字以及对应的索引位置保存到name_id和id_name集合中
for (int i = 0; i < n; i++) {
parent[i] = i;
int index = names[i].indexOf('(');//获取'('的索引位置
String name = names[i].substring(0,index);//获取名字"John"
String freq = names[i].substring(index + 1,names[i].length() - 1);//获取名字出现的频率"15"
name_id.put(name,i);
id_name.put(i,name);
freMap.put(name,Integer.parseInt(freq));
}
//然后我们遍历synonyms数组:
for (String synonym : synonyms) {
//获取每一个相关联名字的字符串数组
String[] nameArr = synonym.substring(1,synonym.length() - 1).split(",");
String name1 = nameArr[0];
String name2 = nameArr[1];
//此时synonyms中可能未包含name1或者name2
if (!name_id.containsKey(name1)) {
continue;
}
if (!name_id.containsKey(name2)) {
continue;
}
int id1 = name_id.get(name1);
int id2 = name_id.get(name2);
//我们选择将id1和id2进行合并操作
union(id1,id2);
}
//最后定义结果集ans
List<String> ans = new ArrayList<>();
freMap.forEach((name,freq) -> {
//int id = name_id.get(name);
ans.add(name + '(' + freq + ')');
});
//最后将ans转换成String数组进行返回
return ans.stream().toArray(String[]::new);
}
//编写并查集的两个方法:
//方法1: 查找x节点的根节点的方法
private int find(int x) {
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
return parent[x];
}
//方法2: 合并两个顶点的方法
private void union(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) {
return;
}
//我们按照字典序的的大小进行排序:将字典序小的设置为新的根节点
String nameX = id_name.get(rootX);
String nameY = id_name.get(rootY);
if (nameX.compareTo(nameY) < 0) {
//说明nameX的字典序小
freMap.put(nameX,freMap.get(nameX) + freMap.get(nameY));
parent[rootY] = rootX;
freMap.remove(nameY);
}else {
//说明nameY的字典序小
freMap.put(nameY,freMap.get(nameY) + freMap.get(nameX));
parent[rootX] = rootY;
freMap.remove(nameX);
}
}
第五题题解:
在一棵树中,边的数量比节点的数量少 1。如果一棵树有 N 个节点,则这棵树有 N−1 条边。这道题中的图在树的基础上多了一条附加的边,因此边的数量也是 N。
树是一个连通且无环的无向图,在树中多了一条附加的边之后就会出现环,因此附加的边即为导致环出现的边。
可以通过并查集寻找附加的边。初始时,每个节点都属于不同的连通分量。遍历每一条边,判断这条边连接的两个顶点是否属于相同的连通分量。
- 如果两个顶点属于不同的连通分量,则说明在遍历到当前的边之前,这两个顶点之间不连通,因此当前的边不会导致环出现,合并这两个顶点的连通分量。
- 如果两个顶点属于相同的连通分量,则说明在遍历到当前的边之前,这两个顶点之间已经连通,因此当前的边导致环出现,为附加的边,将当前的边作为答案返回。
java代码实现:
//使用并查集进行求解
int[] parent;
int[] rank;
public int[] findRedundantConnection(int[][] edges) {
//定义一个set集合: 求解edges二维数组中总共图的顶点的个数
HashSet<Integer> vertexs = new HashSet<>();
for (int i = 0; i < edges.length; i++) {
vertexs.add(edges[i][0]);
vertexs.add(edges[i][1]);
}
//定义并查集的parent数组
parent = new int[vertexs.size() + 1]; //因为顶点[整数]在1到N之间,为了使得parent[i] = i:即顶点的数字和对应的根节点相对应
rank = new int[vertexs.size() + 1]; //因为顶点[整数]在1到N之间
//进行初始化
for (int i = 0; i < parent.length; i++) {
parent[i] = i;
rank[i] = i;
}
//定义结果集
int[] ans = new int[2];
for (int i = 0; i < edges.length ; i++) {
//int x = edges[i][0];
//int y = edges[i][1];
int x_parent = find(edges[i][0]);
int y_parent = find(edges[i][1]);
if (x_parent != y_parent) {
//如果当前edges[i][0]和edges[i][1]的根节点不一致,我们选择进行根节点的合并工作
union(edges[i][0],edges[i][1]);
}else {
//如果相同,则直接输出最后一组边
ans[0] = edges[i][0];
ans[1] = edges[i][1];
}
}
//返回结果集
return ans;
}
//查找当前x节点的父节点的方法
public int find(int x) {
//如果当前节点x的根节点不是其本身:
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
//如果当前节点x的根节点是其本身,则说明该点是独立的,我们直接返回x,即x的根节点parent[x]
return parent[x];
}
//合并两个节点的方法
public void union(int x, int y) {
//找出x节点和y节点的根节点
int rootX = find(x);
int rootY = find(y);
//进行优化
if (rootX == rootY) {
return;
}
//此时表示x的根节点和y的根节点是不同的:我们需要利用rank[]数组进行优化
if (rank[rootX] == rank[rootY]) {
parent[rootX] = rootY;
// 此时以rootY为根结点的树的高度仅加了 1
rank[rootY]++;
} else if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
// 此时以 rootY 为根结点的树的高度不变
} else {
// 同理,此时以 rootX 为根结点的树的高度不变
parent[rootY] = rootX;
}
}
JavaScript代码实现:
第六题题解:
使用并查集进行求解,以stones =[[0,0],[0,1],[1,0],[1,2],[2,1],[2,2]]为例
我们定义一个并查集: 记录每一顶点之间的关系,对同行或者同列的顶点进行合并操作
我们选择定义一个parent集合: key为顶点[行索引或者列索引] value为根节点
遍历stones数组: 拿到其中的行索引和列索引,进行合并union操作
因为行和列索引的最大值为10000,为了将行和列的根节点进行区分,避免初始化出现相同的值,我们选择如果parent集合不包含行索引这个key值,则初始化其根节点为本身+10000;如果包含列索引这个key值,则初始化其根节点为其本身;
然后进行两个顶点的合并union操作: 如果根节点不同,则选择进行合并操作
当初始化时,将count计数器加1,当进行合并时,将计数器减1,最后count的值结尾并查集的个数
最后返回的即是顶点的个数– 并查集的个数

java代码实现:
public int removeStones(int[][] stones) {
//获取stone数组的长度
int n = stones.length;
if (n <= 1) return 0;
//创建并查集对象
DisjointedSet ds = new DisjointedSet();
for (int i = 0; i < n; i++) {
int x = stones[i][0] + 10000; //注意:行的最大值<= 10000
int y = stones[i][1];
//进行union(x,y)
ds.union(x,y);
}
return n - ds.getCount();
}
//定义一个并查集
class DisjointedSet {
//定义并查集的个数
int count;
//定义parent集合:
Map<Integer,Integer> parent;
public DisjointedSet() {
this.count = 0;
parent = new HashMap<>();
}
public void union(int x, int y) {
int Root_X = find(x);
int Root_Y = find(y);
if (Root_X == Root_Y) {
return;
}
//此时进行合并操作,我们选择将count的个数减1
parent.put(Root_Y,Root_X);
count--;
}
public int find(int index) {
if (!parent.containsKey(index)) {
//此时parent对当前index进行初始化,我们选择将count个数加1
parent.put(index,index);
count++;
}
if (index != parent.get(index)) {
parent.put(index,find(parent.get(index)));
}
return parent.get(index);
}
public int getCount() {
return count;
}
}
JavaScript代码实现:
第七题题解:
并查集算法进行求解:

java代码:
//定义并查集的parent集合 key:邮箱 value:根节点
Map<String,String> parent = new HashMap<>();
//定义一个集合: 保存当前邮箱的拥有者[key:邮箱 value:姓名]
Map<String,String> hasMap = new HashMap<>();
//定义一个结果集:key为祖先邮箱,value为该祖先邮箱下面的所有的邮箱
Map<String,Set<String>> res = new HashMap<>();
public List<List<String>> accountsMerge(List<List<String>> accounts) {
//定义结果集
List<List<String>> ans = new ArrayList<>();
//获取账户的size
int size = accounts.size();
if (size == 0) return ans;
//第一步: 我们进行parent和hasMap的初始化
for (int i = 0; i < accounts.size(); i++) {
List<String> list = accounts.get(i);
for (int j = 1; j < list.size(); j++) {
//根节点的初始化: 根节点为其本身
parent.put(list.get(i),list.get(i));
//拥有者的初始化
hasMap.put(list.get(i),list.get(0));
}
}
//第二步: 遍历accounts集合: 我们选择将account中子元素的根节点指向parent
for (List<String> account : accounts) {
String parent = account.get(1);
for (int i = 2; i < account.size(); i++) {
//即将account中子元素的根节点指向parent
union(account.get(i),parent);
}
}
//第三步: 此时我们遍历accounts集合: 将属于同一parent根节点的子节点加入到对应的res集合中
for (List<String> account : accounts) {
//获取account中每一个邮箱元素的根节点,然后将<根节点,Set<根节点下面的子元素>>
for (int i = 1; i < account.size(); i++) {
String parent = find(account.get(i));
if (res.containsKey(parent)) {
res.get(parent).add(account.get(i));
}else {
Set set = new HashSet();
set.add(account.get(i));
res.put(parent,set);
}
}
}
//第四步: 我们将res结果集: 姓名,[邮箱进行排序]加入到ans集合中
for (Map.Entry<String, Set<String>> entry : res.entrySet()) {
//定义sub集合:即保存最后ans结果集中的每一个集合元素
List<String> sub = new ArrayList<>();
//我们单独定义一个emails集合: 存储邮箱[因为要按照字母顺序进行排序]
List<String> emails = new ArrayList<>();
//先添加此时res的key键对应的姓名[拥有者]
sub.add(hasMap.get(entry.getKey()));
//再将对应的set集合中的该拥有者下的所有邮箱子元素添加到emails集合中
entry.getValue().forEach(val->{
emails.add(val);
});
//对emails集合进行排序处理
Collections.sort(emails);
//将emails集合加入到sub子集中
sub.addAll(emails);
//最后加入到ans结果集中
ans.add(sub);
}
//返回结果集
return ans;
}
//查找对应节点x的根节点的方法
private String find(String x) {
if (x != parent.get(x)) {
parent.put(x,find(parent.get(x)));
}
return parent.get(x);
}
//合并节点x和节点y的方法
private void union(String x, String y) {
String Root_X = find(x);
String Root_Y = find(y);
if (Root_X.equals(Root_Y)) {
return;
}
parent.put(Root_X,Root_Y);
}
JavaScript代码:
第八题题解:
Kruskal算法(外加并查集)进行求解:

java代码实现:
//使用并查集进行求解
public int minCostConnectPoints(int[][] points) {
//获取point矩阵的长度
int n = points.length;
if (n <= 1) return 0;
//定义结果集
int ans = 0;
//定义一个list集合: 存储的值为(Edges)
List<Edge> list = new ArrayList<>();
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
//记录两个顶点之间的dis[曼哈顿距离,两个顶点之间的坐标x和y]
list.add(new Edge(hfm(points,i,j),i,j));
}
}
//对list进行排序: 按照Edges类的dis距离进行排序
Collections.sort(list, new Comparator<Edge>() {
public int compare(Edge edge1, Edge edge2) {
return edge1.dis - edge2.dis;
}
});
//定义并查集
DisjointedSet disjointedSet = new DisjointedSet(n);
int k = 1;
//此时list集合中已经按照曼哈顿距离进行排序处理,我们遍历该list集合,进行x顶点和y顶点的合并操作
//如果返回true: 表示可以连通 如果返回true表示不能连通
for (Edges edges : list) {
int x = edges.x;
int y = edges.y;
if (disjointedSet.union(x,y)) {
//能够连通
ans += edges.dis;
k++;
if (k == n) break;
}
}
return ans;
}
//计算曼哈顿距离的方法
private int hfm(int[][] points, int i, int j) {
return Math.abs(points[i][0] - points[j][0]) + Math.abs(points[i][1] - points[j][1]);
}
//定义一个并查集类
class DisjointedSet {
int[] parent;
public DisjointedSet(int n) {
this.parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
public int find(int x) {
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
return parent[x];
}
public boolean union(int x, int y) {
int Root_X = find(x);
int Root_Y = find(y);
if (Root_X == Root_Y) {
return false;
}
parent[Root_X] = Root_Y;
return true;
}
}
//定义一个Edge类
class Edge {
public int dis;
public int x;
public int y;
public Edge(int dis, int x, int y) {
this.dis = dis;
this.x = x;
this.y = y;
}
}
JavaScript代码实现:
Prim算法进行求解:
其中此题使用Prim算法,小公主梦霞同学的javaScript代码能够通过,本人的java惨败最后一例,这里也贴出代码:
java代码:
public int minCostConnectPoints(int[][] points) {
//获取point矩阵的长度
int n = points.length;
if (n <= 1) return 0;
int ans = 0;
int[] pointArr = new int[n];
boolean[] isVisited = new boolean[n];
isVisited[0] = true;
for (int k = 1; k < n; k++) { //k:表示边的条数
int minDis = Integer.MAX_VALUE;
int index = 0;
for(int i = 0; i < k; i++) {//访问过的顶点
for(int j = 0; j < n; j++) {//还未访问的顶点
if(!isVisited[j]) {
int dis = hfm(points,pointArr[i],j);
if(dis < minDis) {
minDis = dis;
index = j;
}
}
}
}
ans += minDis;
isVisited[index] = true;
pointArr[k] = index;
}
return ans;
}
private int hfm(int[][] points, int i, int j) {
return Math.abs(points[i][0] - points[j][0]) + Math.abs(points[i][1] - points[j][1]);
}
JavaScript代码:
4. 并查集闯关题
闯关题1: 最小体力消耗路径问题
你准备参加一场远足活动。给你一个二维 rows x columns 的地图 heights ,其中 heights[row][col] 表示格子 (row, col) 的高度。一开始你在最左上角的格子 (0, 0) ,且你希望去最右下角的格子 (rows-1, columns-1) (注意下标从 0 开始编号)。你每次可以往 上,下,左,右 四个方向之一移动,你想要找到耗费 体力 最小的一条路径。
一条路径耗费的 体力值 是路径上相邻格子之间 高度差绝对值 的 最大值 决定的。
请你返回从左上角走到右下角的最小 体力消耗值 。
示例 1:
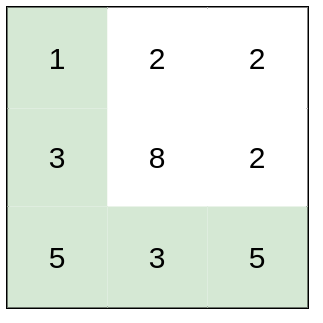
输入:heights = [[1,2,2],[3,8,2],[5,3,5]]
输出:2
解释:路径 [1,3,5,3,5] 连续格子的差值绝对值最大为 2 。
这条路径比路径 [1,2,2,2,5] 更优,因为另一条路径差值最大值为 3 。
示例 2:
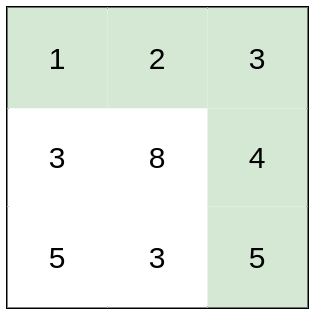
输入:heights = [[1,2,3],[3,8,4],[5,3,5]]
输出:1
解释:路径 [1,2,3,4,5] 的相邻格子差值绝对值最大为 1 ,比路径 [1,3,5,3,5] 更优。
示例 3:
输入:heights = [[1,2,1,1,1],[1,2,1,2,1],[1,2,1,2,1],[1,2,1,2,1],[1,1,1,2,1]]
输出:0
解释:上图所示路径不需要消耗任何体力。
提示:
rows == heights.lengthcolumns == heights[i].length1 <= rows, columns <= 1001 <= heights[i][j] <= 106
题解 :
该题我们采取并查集的思路所示:
-
并查集求解思路分析:
因为题目要求我们求从起始位置(0,0)到右下角位置(row – 1, col - 1)的最小消耗值:
故我们利用图的概念: 定义一个边类(Edge) : 其中包含起始节点,结束节点以及起始节点到结束节点的体力消耗值
那么对于row col 的矩阵来说,一共存在row col 个顶点,则存在row *col +1条边:
我们分别记录每条边的信息,并将其存储在一个集合中
接着我们按照dis的大小进行排序(升序,从小到大进行排序)
然后遍历这个Edge的集合:
(1)首先选择将两个顶点进行联合(合并操作)
(2)然后判断此时起始位置顶点和目标顶点是否已经连接(根节点相同)
- 如果根节点相同: 说明此时第一个顶点0和最后要到达的顶点已经连通,根节点相同,则minValue为当前排序以后当前边的dis的值,我们直接break,然后返回minValue的值即可.
- 如果根节点不相同:则继续进行遍历
java代码实现:
并查集类DisjointedSet:
class DisjointedSet {
//并查集的个数
int count;
//根节点数组
int[] parent;
public DisjointedSet(int n) {
this.count = count;
this.parent = new int[n];
for(int i = 0 ; i < n; i++) {
parent[i] = i;
}
}
//查找根节点的方法: 递归查找
int find(int x) {
if(x != parent[x]) {
parent[x] = find(parent[x]);
}
return parent[x];
}
//进行两个节点联合的方法 : 当两个节点已经属于一个并查集,则返回false,否则进行合并,返回true
boolean union(int x, int y) {
int Root_X = find(x);
int Root_Y = find(y);
if(Root_X == Root_Y) {
return false;
}
//否则进行合并
parent[Root_X] = Root_Y;
return true;
}
//判断两个节点是否已经连接[属于一个并查集]
boolean isConnected(int x, int y) {
int Root_X = find(x);
int Root_Y = find(y);
return Root_X == Root_Y;
}
}
边(Edge)类:
class Edge{
int from_vertex; //起始顶点
int to_vertex;//目标顶点
int dis;//消耗的体力
public Edge(int from_vertex, int to_vertex, int dis) {
this.from_vertex = from_vertex;
this.to_vertex = to_vertex;
this.dis = dis;
}
}
算法:
class Solution {
//使用并查集进行求解
public int minimumEffortPath(int[][] heights) {
if (heights == null || heights.length == 0) return 0;
if(heights.length == 1 && heights[0].length == 1) return 0;
//定义一个Edge类的集合
List<Edge> list = new ArrayList<>();
int row = heights.length;
int col = heights[0].length;
//我们将row * col + 1条边信息记录到list中去
for(int i = 0; i < row; i++) {
for(int j = 0; j < col; j++) {
//为了防止重复,我们依次记录当前顶点和左侧顶点以及上侧顶点之间的边的信息
int vertex = i * col + j; //获取当前顶点的序号
if(i > 0) {
//说明存在上侧的顶点
list.add(new Edge(vertex - col, vertex, Math.abs(heights[i][j] - heights[i - 1][j])));
}
if(j > 0) {
//说明存在左侧的顶点
list.add(new Edge(vertex - 1,vertex,Math.abs(heights[i][j] - heights[i][j - 1])));
}
}
}
//然后我们选择将list按照dis的大小进行升序排序
Collections.sort(list,new Comparator<Edge>() {
public int compare(Edge edge1, Edge edge2) {
return edge1.dis - edge2.dis;
}
});
//定义并查集: 总共有row * col 个顶点
DisjointedSet set = new DisjointedSet(row * col);
//定义结果集
int minValue = 0;
for(Edge edge : list) {
int x = edge.from_vertex;
int y = edge.to_vertex;
set.union(x,y);
if(set.isConnected(0,row * col - 1)) {
//说明此时第一个顶点已经和目标顶点连通,故此时已经到达目的地
minValue = edge.dis;
break;
}
}
//最后返回结果集
return minValue;
}
}
闯关题2: 水位上升的游泳池中游泳
在一个 N x N 的坐标方格 grid 中,每一个方格的值 grid[i][j] 表示在位置 (i,j) 的平台高度。
现在开始下雨了。当时间为 t 时,此时雨水导致水池中任意位置的水位为 t 。你可以从一个平台游向四周相邻的任意一个平台,但是前提是此时水位必须同时淹没这两个平台。假定你可以瞬间移动无限距离,也就是默认在方格内部游动是不耗时的。当然,在你游泳的时候你必须待在坐标方格里面。
你从坐标方格的左上平台 (0,0) 出发。最少耗时多久你才能到达坐标方格的右下平台 (N-1, N-1)?
示例 1:
输入: [[0,2],[1,3]]
输出: 3
解释:
时间为0时,你位于坐标方格的位置为 (0, 0)。
此时你不能游向任意方向,因为四个相邻方向平台的高度都大于当前时间为 0 时的水位。
等时间到达 3 时,你才可以游向平台 (1, 1). 因为此时的水位是 3,坐标方格中的平台没有比水位 3 更高的,所以你可以游向坐标方格中的任意位置
示例2:
输入: [[0,1,2,3,4],[24,23,22,21,5],[12,13,14,15,16],[11,17,18,19,20],[10,9,8,7,6]]
输出: 16
解释:
0 1 2 3 4
24 23 22 21 5
12 13 14 15 16
11 17 18 19 20
10 9 8 7 6
最终的路线用加粗进行了标记。
我们必须等到时间为 16,此时才能保证平台 (0, 0) 和 (4, 4) 是连通的
提示:
2 <= N <= 50.grid[i][j]是[0, ..., N*N - 1]的排列。
题解:
这道题目的思路和上面的题目的思路完全一致,不同之处就在于Edge的dis属性变成了求两者水位的最大高度
//使用并查集进行求解:和1631. 最小体力消耗路径的解题思路几乎完全一致
public int swimInWater(int[][] grid) {
//定义一个Edge类的集合
List<Edge> list = new ArrayList<>();
int row = grid.length;
int col = grid[0].length;
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
//为了防止重复:我们依次记录该顶点和左边顶点以及上面顶点的dis
int vertex = i * col + j;//获取当前顶点的顶点序号[注意:这里是i * 列 + j,而不是i * 行 + j!!!!!!!]
if (i > 0) {
//则记录当前顶点和上面顶点的dis[两个水位的最大值]
list.add(new Edge(vertex - col,vertex,Math.max(grid[i][j],grid[i - 1][j])));
}
if (j > 0) {
//则记录当前顶点和左边顶点的dis[两个水位的最大值]
list.add(new Edge(vertex - 1,vertex,Math.max(grid[i][j],grid[i][j - 1])));
}
}
}
//然后将list按照dis进行排序处理
Collections.sort(list, new Comparator<Edge>() {
public int compare(Edge edge1, Edge edge2) {
return edge1.dis - edge2.dis;
}
});
//我们定义并查集: 顶点的个数等于row * col
DisjointedSet disjointedSet = new DisjointedSet(row * col);
//定义结果集
int minTime = 0;
for (Edge edge : list) {
int x = edge.from_vertex;
int y = edge.to_vertex;
disjointedSet.union(x,y);
//单独定义一个isConnected方法
if (disjointedSet.isConnected(0,row * col - 1)) {
//说明此时第一个顶点0和最后要到达的顶点已经连通,根节点相同,则minValue为当前排序以后边的dis的值
minTime = edge.dis;
break; //此时找到答案,直接停止查找
}
}
return minTime;
}
//定义并查集
class DisjointedSet {
int count;
int[] parent;
public DisjointedSet(int n) {
this.count = n;
this.parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
//查找根节点的方法
int find(int x) {
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
return parent[x];
}
//进行联合的方法
boolean union(int x, int y) {
int Root_X = find(x);
int Root_Y = find(y);
if (Root_X == Root_Y) {
return false;
}
parent[Root_X] = Root_Y;
return true;
}
//只判断两者是否连接
boolean isConnected(int x, int y) {
int Root_X = find(x);
int Root_Y = find(y);
return Root_X == Root_Y;
}
}
//定义两顶点的边类
class Edge {
int from_vertex; //开始的顶点
int to_vertex; //结束的顶点
int dis;
public Edge(int from_vertex, int to_vertex, int dis) {
this.from_vertex = from_vertex;
this.to_vertex = to_vertex;
this.dis = dis;
}
}
闯关题3 : 情侣牵手问题
N 对情侣坐在连续排列的 2N 个座位上,想要牵到对方的手。 计算最少交换座位的次数,以便每对情侣可以并肩坐在一起。 一次交换可选择任意两人,让他们站起来交换座位。
人和座位用 0 到 2N-1 的整数表示,情侣们按顺序编号,第一对是 (0, 1),第二对是 (2, 3),以此类推,最后一对是 (2N-2, 2N-1)。
这些情侣的初始座位 row[i] 是由最初始坐在第 i 个座位上的人决定的。
示例 1:
输入: row = [0, 2, 1, 3]
输出: 1
解释: 我们只需要交换row[1]和row[2]的位置即可。
示例 2:
输入: row = [3, 2, 0, 1]
输出: 0
解释: 无需交换座位,所有的情侣都已经可以手牵手了。
说明:
len(row)是偶数且数值在[4, 60]范围内。- 可以保证
row是序列0...len(row)-1的一个全排列。
题解:使用并查集进行问题的求解
首先我们来观察下面的例子:

那么此时我们说总共有n个人,即存在n / 2对情侣,我们假设N = n / 2
那么假设这N对情侣中,逻辑上连在一起的情侣(包括坐错的和坐对位置的情况)分别存在N1,N2…Nm对,那么其中Ni对(1<= i <= m),我们需要交换的最少次数为Ni - 1次;
则此时有:
(N1 - 1) + (N2 - 1) + (N3 - 1) + (Ni - 1) + … + (Nm - 1) = N - m
故总共至少交换的次数 = 所有的情侣的对数(n / 2) - 并查集中连通分量的个数
**并查集类(DisjointedSet) **
class DisjointedSet {
int count; //并查集的个数
//定义一个数组parent[]: 用于记录该节点的父节点,使得所有相关的节点位于同一个连通图中
int[] parent;
//定义一个数组rank[]: 主要用于优化,在合并两个父节点的时候,通过rank的大小判断谁是父节点,谁是子节点
int[] rank;
//构造方法
public DisjointedSet(int n) {
this.count = n;
this.parent = new int[n];
this.rank = new int[n];
//我们选择将初始化的parent[]数组和rank数组的值设置为索引i本身
for (int i = 0; i < n; i++) {
this.parent[i] = i;
this.rank[i] = i;
}
}
//合并两个节点的方法
public boolean union(int x, int y) {
//找出x节点和y节点的根节点
int rootX = find(x);
int rootY = find(y);
//如果x的根节点和y的根节点相同:则说明已经合并了,直接返回即可
if (rootX == rootY) {
return false;
}
//此时表示x的根节点和y的根节点是不同的:我们需要利用rank[]数组进行优化
if (rank[rootX] == rank[rootY]) {
parent[rootX] = rootY;
// 此时以rootY为根结点的树的高度仅加了 1
rank[rootY]++;
} else if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
// 此时以 rootY 为根结点的树的高度不变
} else {
// 同理,此时以 rootX 为根结点的树的高度不变
parent[rootY] = rootX;
}
--count; //合并一次.count--
return true;
}
//查找当前x节点的父节点的方法
public int find(int x) {
//如果当前节点x的根节点不是其本身:
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
//如果当前节点x的根节点是其本身,则说明该点是独立的,我们直接返回x,即x的根节点parent[x]
return parent[x];
}
//判断两个节点的父节点是否一致的方法
public boolean isConnected(int x , int y) {
int Root_X = find(x);
int Root_Y = find(y);
return Root_X == Root_Y;
}
}
算法代码:
class Solution {
/*
* 使用并查集进行求解:
* 最少交换次数 = 目前没有牵手成功的情侣的对数 - 1
* 最少交换次数 = 交换后的情侣的对数[并查集的个数] - 交换前的并查集的个数
* */
public int minSwapsCouples(int[] row) {
int n = row.length; //获取row数组的数组长度
DisjointedSet disjointedSet = new DisjointedSet(n / 2);
for (int i = 0; i < n; i += 2) {
//依次判断两个索引(0,1),(2,3)...位置是否为情侣,不是情侣,进行合并
if (!disjointedSet.isConnected(row[i] / 2,row[i + 1] / 2)) {
disjointedSet.union(row[i] / 2,row[i + 1] / 2);
}
}
//最后返回n / 2(总共存在n / 2对情侣) - 并查集的个数
return n / 2 - disjointedSet.count;
}
}
闯关题4 : 相似字符串组
如果交换字符串 X 中的两个不同位置的字母,使得它和字符串 Y 相等,那么称 X 和 Y 两个字符串相似。如果这两个字符串本身是相等的,那它们也是相似的。
例如,"tars" 和 "rats" 是相似的 (交换 0 与 2 的位置); "rats" 和 "arts" 也是相似的,但是 "star" 不与 "tars","rats",或 "arts" 相似。
总之,它们通过相似性形成了两个关联组:{"tars", "rats", "arts"} 和 {"star"}。注意,"tars" 和 "arts" 是在同一组中,即使它们并不相似。形式上,对每个组而言,要确定一个单词在组中,只需要这个词和该组中至少一个单词相似。
给你一个字符串列表 strs。列表中的每个字符串都是 strs 中其它所有字符串的一个字母异位词。请问 strs 中有多少个相似字符串组?
示例 1:
输入:strs = ["tars","rats","arts","star"]
输出:2
示例 2:
输入:strs = ["omv","ovm"]
输出:1
提示:
1 <= strs.length <= 3001 <= strs[i].length <= 300strs[i]只包含小写字母。strs中的所有单词都具有相同的长度,且是彼此的字母异位词。
备注:
字母异位词(anagram),一种把某个字符串的字母的位置(顺序)加以改换所形成的新词。
题解:
我们选择使用并查集进行求解该问题:
首先我们编写判断两个字符串是否能够通过至多两次交换得到另一个字符串方法,即判断两个字符串是否相似的:
//判断两个字符串是否相似的方法:你的方法也正确,这里进行优化一下
public boolean judge(String left, String right, int len) {
//比较两个字符串元素是否只存在一位数不同
int cnt = 0;
for (int i = 0; i < len; i++) {
if (left.charAt(i) != right.charAt(i)) {
cnt++;
if (cnt > 2) { //说明两个字符串不止一处位置不同
return false;
}
}
}
return true;
}
然后整体的并查集思路如下:
我们定义一个parent(父节点)map集合类: key为该顶点,value为该顶点的根节点
首先初始化parent数组 : 每个字符串的顶点是其本身
定义一个count属性 : 即并查集的个数,也就是相似字符串数组的个数,初始化为字符串数组的长度
我们遍历整个字符串数组(两层for循环):
分别拿到两个字符串left_word和right_word:
- 获取其根节点字符串left_parent和right_parent,比较其是否相等
- 如果相等,说明,已经进行合并,直接进行下一轮的判断
- 如果不相等,我们先判断两者是否为相似字符串,如果是,则进行合并操作
最后返回并查集的个数count,即为合并的相似字符串数组的组数
代码实现:
class Solution {
//定义一个parent的map集合
Map<String,String> parent = new HashMap<>();
int count;
public int numSimilarGroups(String[] strs) {
int n = strs.length;
count = n;
int len = strs[0].length(); //获取每一个字符串元素的统一长度
//初始化parent集合
for (int i = 0; i < n; i++) {
if (parent.containsKey(strs[i])) {
count--;
continue;
}
parent.put(strs[i],strs[i]);
}
//我们通过两层for循环进行每两个字符串元素的判断是否相似
//(1) 如果根节点相同:表示已经进行合并操作,直接跳过
//(2) 如果两者的根节点不同,并且两者是相似字符串,则我们选择进行合并操作,将并查集的个数count的值减1
//(3) 最后返回并查集的个数count
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) {
String left_parent = parent.get(strs[i]); //左字符串的根节点
String right_parent = parent.get(strs[j]); //右字符串的根节点
String left_word = strs[i];
String right_word = strs[j];
if (left_parent.equals(right_parent)) {
//如果两个字符串的根节点相同,则说明已经合并,直接continue进行下一轮的判断
continue;
}
if (judge(left_word,right_word,len)) {
//说明两个字符串是相似字符串,我们选择将i和j顶点进行联合
union(left_word,right_word);
}
}
}
return count; //最后并查集的个数即为合并的相似字符串的组数
}
//判断两个字符串是否为相似字符串的方法
public boolean judge(String left, String right, int len) {
//比较两个字符串元素是否只存在一位数不同
int cnt = 0;
for (int i = 0; i < len; i++) {
if (left.charAt(i) != right.charAt(i)) {
cnt++;
if (cnt > 2) { //说明两个字符串不止一处位置不同
return false;
}
}
}
return true;
}
//查找根节点的方法
public String find(String x) {
if (x != parent.get(x)) {
parent.put(x,find(parent.get(x)));
}
return parent.get(x);
}
//联合两个节点的方法
public boolean union(String x, String y) {
String Root_X = find(x);
String Root_Y = find(y);
if (Root_X == Root_Y) {
return false;
}
//合并一次,并查集个数减1
count--;
parent.put(Root_X,Root_Y);
return true;
}
}
闯关题5 : 由斜杠划分区域
在由 1 x 1 方格组成的 N x N 网格 grid 中,每个 1 x 1 方块由 /、\ 或空格构成。这些字符会将方块划分为一些共边的区域。
(请注意,反斜杠字符是转义的,因此 \ 用 "\\" 表示。)。
返回区域的数目。
示例 1:
输入:
[
" /",
"/ "
]
输出:2
解释:2x2 网格如下:
示例 2:
输入:
[
" /",
" "
]
输出:1
解释:2x2 网格如下:
示例 3:
输入:
[
"\\/",
"/\\"
]
输出:4
解释:(回想一下,因为 \ 字符是转义的,所以 "\\/" 表示 \/,而 "/\\" 表示 /\。)
2x2 网格如下:
示例 4:
输入:
[
"/\\",
"\\/"
]
输出:5
解释:(回想一下,因为 \ 字符是转义的,所以 "/\\" 表示 /\,而 "\\/" 表示 \/。)
2x2 网格如下:
示例 5:
输入:
[
"//",
"/ "
]
输出:3
解释:2x2 网格如下:
提示:
1 <= grid.length == grid[0].length <= 30grid[i][j]是'/'、'\'、或' '。
题解:
此时依旧选择使用并查集进行问题的求解:
class Solution {
public int regionsBySlashes(String[] grid) {
//获取grid的长度: 则构建(N + 1) * (N + 1)个顶点
int N = grid.length;
int vertexCount = (N + 1) * (N + 1);
//定义一个并查集
DisjointedSet disjointedSet = new DisjointedSet(vertexCount);
//首先将外围的顶点的根节点进行联合
int M = N + 1;
for (int i = 0; i < vertexCount; i++) {
if (i / M == 0 || i / M == M - 1 || i % M == 0 || i % M == M - 1) {
disjointedSet.parent[i] = 0;
}
}
//然后访问每一个小网格,根据斜杠的不同进行不同的顶点的查找
//如果根节点相同:说明形成了环,此时将区域的个数加1
//如果根节点不同:则进行合并操作
int cnt = 1; //定义计数器cnt:记录划分区域的个数,初始化为1: 整个区域
for (int i = 0; i < N; i++) {
char[] array = grid[i].toCharArray();
for (int j = 0; j < array.length; j++) {
//其中根据(i,j) 可得对应的顶点坐标为(row + 1) * i + j
if (array[j] == '/') {
int x = M * i + j + 1;
int y = M * i + j + M;
if (!disjointedSet.union(x,y)) {
cnt++;
}
}
if (array[j] == '\\') {
int x = M * i + j;
int y = M * i + j + M + 1;
if (!disjointedSet.union(x,y)) {
cnt++;
}
}
}
}
//最后返回cnt的值
return cnt;
}
}
//定义并查集类
class DisjointedSet {
int[] parent;
public DisjointedSet(int n) {
parent = new int[n + 1];
for (int i = 0; i < parent.length; i++) {
parent[i] = i;
}
}
public int find(int x) {
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
return parent[x];
}
public boolean union(int x, int y) {
int Root_X = find(x);
int Root_Y = find(y);
//表示根节点相同
if (Root_X == Root_Y) {
return false;
}
//根节点不同
parent[Root_X] = Root_Y;
return true;
}
闯关题6 : 连通网络的次数
用以太网线缆将 n 台计算机连接成一个网络,计算机的编号从 0 到 n-1。线缆用 connections 表示,其中 connections[i] = [a, b] 连接了计算机 a 和 b。
网络中的任何一台计算机都可以通过网络直接或者间接访问同一个网络中其他任意一台计算机。
给你这个计算机网络的初始布线 connections,你可以拔开任意两台直连计算机之间的线缆,并用它连接一对未直连的计算机。请你计算并返回使所有计算机都连通所需的最少操作次数。如果不可能,则返回 -1 。
示例 1:
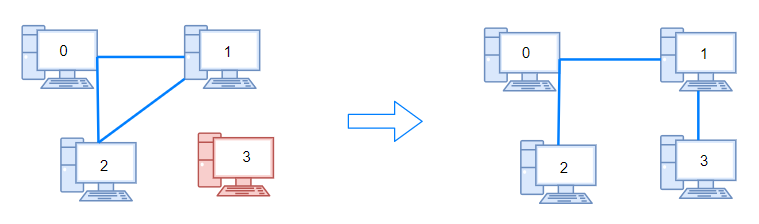
输入:n = 4, connections = [[0,1],[0,2],[1,2]]
输出:1
解释:拔下计算机 1 和 2 之间的线缆,并将它插到计算机 1 和 3 上。
示例 2:
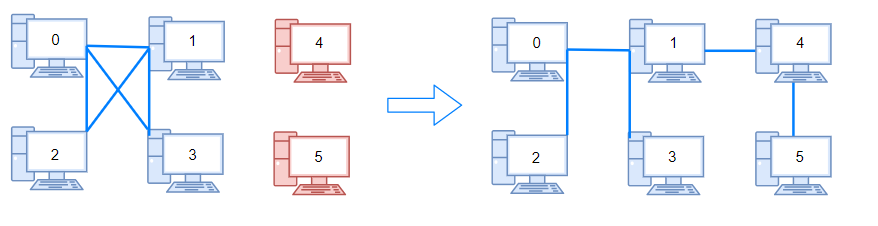
输入:n = 6, connections = [[0,1],[0,2],[0,3],[1,2],[1,3]]
输出:2
示例 3:
输入:n = 6, connections = [[0,1],[0,2],[0,3],[1,2]]
输出:-1
解释:线缆数量不足。
示例 4:
输入:n = 5, connections = [[0,1],[0,2],[3,4],[2,3]]
输出:0
提示:
1 <= n <= 10^51 <= connections.length <= min(n*(n-1)/2, 10^5)connections[i].length == 20 <= connections[i][0], connections[i][1] < nconnections[i][0] != connections[i][1]- 没有重复的连接。
- 两台计算机不会通过多条线缆连接。
题解:
- 首先我们说对于n台计算机,至少需要n - 1条以太网线,才能将所有的计算机连接起来
- 如果此时connections.length >= n - 1,我们选择使用并查集算法进行求解,最后的结果集即为并查集的个数 - 1
代码实现:
class Solution {
public int makeConnected(int n, int[][] connections) {
//不满足基本条件,直接返回-1
if (connections.length < n - 1) {
return -1;
}
//创建并查集类
DisjointedSet disjointedSet = new DisjointedSet(n);
for (int[] connection : connections) {
disjointedSet.union(connection[0],connection[1]);
}
return disjointedSet.count - 1;
}
}
class DisjointedSet {
int count; //并查集的个数
int[] parent;
public DisjointedSet(int n) {
this.count = n;
this.parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
//查找根节点的方法
public int find(int x) {
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
return parent[x];
}
//合并两个节点的方法
public boolean union(int x, int y) {
int Root_X = find(x);
int Root_Y = find(y);
//表示根节点相同
if (Root_X == Root_Y) {
return false;
}
//根节点不同
parent[Root_X] = Root_Y;
count--;
return true;
}
}
闯关题7 : 保证图可完全遍历
Alice 和 Bob 共有一个无向图,其中包含 n 个节点和 3 种类型的边:
- 类型 1:只能由 Alice 遍历。
- 类型 2:只能由 Bob 遍历。
- 类型 3:Alice 和 Bob 都可以遍历。
给你一个数组 edges ,其中 edges[i] = [typei, ui, vi] 表示节点 ui 和 vi 之间存在类型为 typei 的双向边。请你在保证图仍能够被 Alice和 Bob 完全遍历的前提下,找出可以删除的最大边数。如果从任何节点开始,Alice 和 Bob 都可以到达所有其他节点,则认为图是可以完全遍历的。
返回可以删除的最大边数,如果 Alice 和 Bob 无法完全遍历图,则返回 -1 。
示例 1:
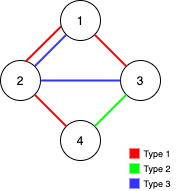
输入:n = 4, edges = [[3,1,2],[3,2,3],[1,1,3],[1,2,4],[1,1,2],[2,3,4]]
输出:2
解释:如果删除 [1,1,2] 和 [1,1,3] 这两条边,Alice 和 Bob 仍然可以完全遍历这个图。再删除任何其他的边都无法保证图可以完全遍历。所以可以删除的最大边数是 2 。
示例 2:
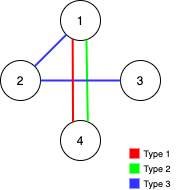
输入:n = 4, edges = [[3,1,2],[3,2,3],[1,1,4],[2,1,4]]
输出:0
解释:注意,删除任何一条边都会使 Alice 和 Bob 无法完全遍历这个图。
示例 3:
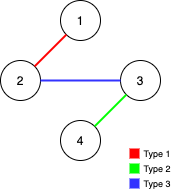
输入:n = 4, edges = [[3,2,3],[1,1,2],[2,3,4]]
输出:-1
解释:在当前图中,Alice 无法从其他节点到达节点 4 。类似地,Bob 也不能达到节点 1 。因此,图无法完全遍历。
提示:
1 <= n <= 10^51 <= edges.length <= min(10^5, 3 * n * (n-1) / 2)edges[i].length == 31 <= edges[i][0] <= 31 <= edges[i][1] < edges[i][2] <= n- 所有元组
(typei, ui, vi)互不相同
题解:
代码实现:
class Solution {
public int maxNumEdgesToRemove(int n, int[][] edges) {
//然后分别创建关于Alice和Bob的并查集
//因为edges中的顶点是从1开始的,而我们的并查集初始化的顶点要从1开始的,使得顶点的值和初始化的根节点的值保持一致
DisjointedSet Alice = new DisjointedSet(n);
DisjointedSet Bob = new DisjointedSet(n);
//我们优先处理公共边:加edge[i][0] == 3的边
int ans = 0; //定义结果集: 即删除的边的个数
for (int[] edge : edges) {
if (edge[0] == 3) {
if (!Alice.union(edge[1],edge[2])) {
//表示该公共边的两个顶点已经连通: 我们选择将ans结果集减1
ans++;
}else {
//如果上面两个顶点没有连通,则在Alice的并查集中进行合并操作,同时在Bob的并差集中也要进行合并操作
Bob.union(edge[1],edge[2]);
}
}
}
//然后分别处理Alice的单独边和Bob的单独边
for (int[] edge : edges) {
if (edge[0] == 1) {
//表示为Alice的独占边
if (!Alice.union(edge[1],edge[2])) {
ans++;
}
}
if (edge[0] == 2) {
//表示为Bob的独占边
if (!Bob.union(edge[1],edge[2])) {
ans++;
}
}
}
//此时ans结果集即为删除的边的个数
//注意:如果此时Alice和Bob的并查集的个数没有到达1,则表示两者没有遍历整个图
if (Alice.getCount() != 1 || Bob.getCount() != 1) {
return -1; //表示 Alice 和 Bob 无法完全遍历图,则返回 -1
}
//否则我们能够遍历整个图,返回ans结果集
return ans;
}
}
//定义并查集模板
class DisjointedSet {
private int count; //表示并查集的个数
private int[] parent;
public DisjointedSet(int n) {
this.count = n;
this.parent = new int[n + 1];
for (int i = 1; i <= n; i++) {
parent[i] = i;
}
}
public int find(int x) {
if (x != parent[x]) {
parent[x] = find(parent[x]);
}
return parent[x];
}
public boolean union(int x, int y) {
int Root_X = find(x);
int Root_Y = find(y);
if (Root_X == Root_Y) {
return false;
}
parent[Root_X] = Root_Y;
//此时进行合并操作,count减1
count--;
return true;
}
//获取并查集的个数
public int getCount() {
return this.count;
}
}
















 7449
7449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









