







一、背景
在稳定性保证中,重要的一个环节就是故障管理体系建设,故障管理体系的四大核心功能——故障发现、故障触达、故障定位和故障恢复,其中故障发现作为故障管理的第一步至关重要,包含了指标预测、异常检测和故障预测等方面,主要目标是能及时、准确地发现故障。今天主要针对故障发现环节中的异常检测介绍AI异常检测算法在指标检测上的应用。
传统基于阈值的异常检测方法的缺点:
-
比较依赖个人经验,需要了解指标的历史趋势。
-
配置比较复杂,有时对周期波动型的时序数据还要针对不同的时间段配置不同的阈值。
-
随着业务的变更要不断调整阈值,随着时间推移、业务的变更,观测指标趋势也可能发生改变,要对阈值做相应的调整。
受大促或异常值影响比较大,像有些阈值配置同比或者环比,如果上一时刻或者历史同时刻有数据有异常,会影响该时刻的检测判断。
对比固定阈值的检测,AI检测算法在突增、突降等异常检测场景中可以很好地解决上述问题。下面会针对AI检测算法在可观测性产品中的应用做相关的介绍。
二、异常检测算法
AI异常检测算法之前,通常需要对历史数据做预处理,包括异常值的剔除,缺失值的填充等。
异常值剔除
这时可能大家会有疑惑,做异常检测为什么还要剔除异常值,这里的异常值是指作为参照的历史数据中的极值,剔除极值可以减少极值影响,去除异常值有助于提高异常检测算法的准确性。
箱型图
箱型图不需要考虑数据集的分布情况,它是通过将数据分成四分位来衡量统计分散度和数据可变性,是一种简单有效的异常点剔除算法。

-
下四分位数:25%分位点对应的值(Q1)
-
中位数:50%分位点对应的值(Q2)
-
上四分位数:75%分位点对应的值(Q3)
-
上须:Q3+1.5(Q3-Q1)
-
下须:Q1-1.5(Q3-Q1)
如上图所示,大于上须的值或者小于下须的值我们认为是异常值。
考虑3sigma跟箱型图算法的特点,箱型图可能更加具普适性,因为它不用考虑数据集的分布情况,在实际应用中我们也是采用的箱型图算法来剔除异常点。剔除异常值后需要对缺失值进行填充,确保数据的连续性,防止后续检测算法在处理时报错,通常缺失值填充的方法有:
-
前后填充法,使用前一个值填充或者后一个正常值填充。
-
均值、中位数填充法。
-
插值法,插值法有线性插值和多项式插值。线性插值就是通过线性回归预测缺失位置的值,多项式插值使用多项式回归预测缺失位置值。
下面是我们采用箱型图剔除异常点并采用多项式插值的效果:
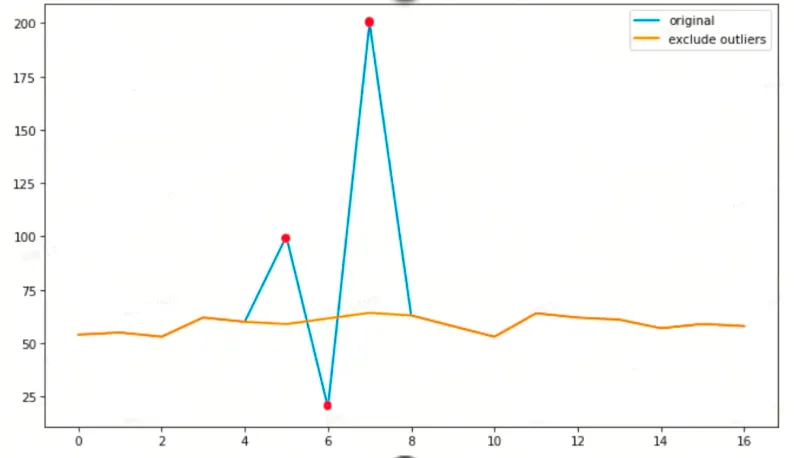
蓝色的线是原始的观测值,红色的点是检测出的异常点,黄色的线是通过插值法填充后的结果。数据预处理后,利用预处理后的结果进行异常点检测。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









