







【python 学习】HTTP协议,urllib请求简单入门详解(入坑谨慎)
python 学习记录
菜鸟程序员一枚,从现在开始记录python学习,并将工作中遇到的问题和程序进行整理输出,方便自己的记忆。
1 、HTTP协议
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是因特网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标准。HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
web服务器
Apache服务器,IIS服务器(Internet Information Services)等。
消息结构
HTTP是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响应协议。
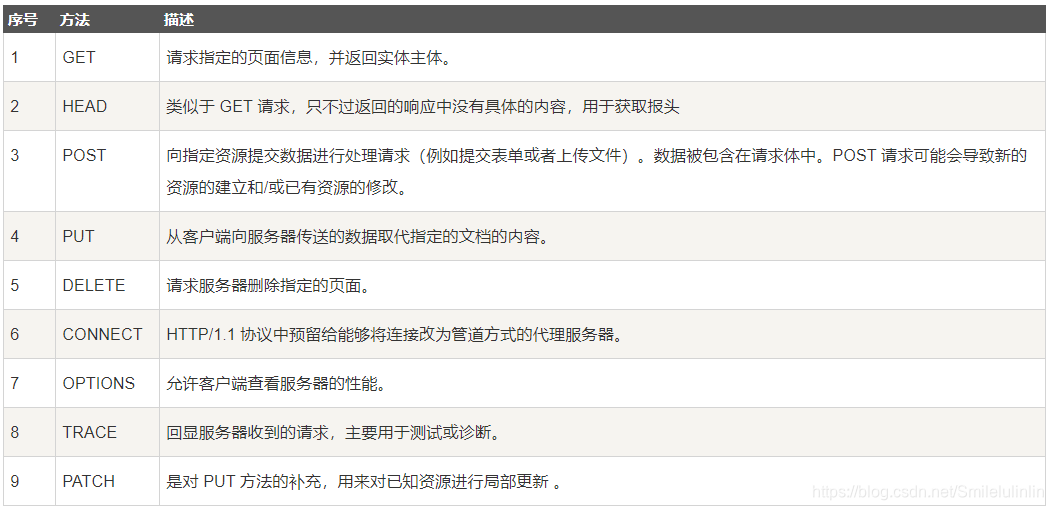
HTTP请求方法
urllib简单使用
urllib是python的内置HTTP请求库,在python2.x以及3.x有所不同。
python2.x 发送HTTP请求的方法
url = 'http://127.0.0.1:8080/service/datalist'
print 'Request URL = ', url
req = urllib2.Request(url=url,data=urllib.urlencode(data)) #可以看出urllib着重构造url请求的结构
res = urllib2.urlopen(req) # 对请求进行处理
status = res.read()
print status
python3.x 发送HTTP请求
随着版本的升级改造,上述的urllib、urllib2合并为urllib,若在3中继续使用urllib2将会报错。
同样的请求将采用下面的请求方式来完成。
url = 'http://121.36.13.81:4601/service/datalist'
print ('Request URL = ', url)
req = urllib.request.urlopen(url=url,data=urllib.parse.urlencode(data).encode('utf-8'))
#res = urllib.urlopen(req)
status = req.read().decode('utf-8')
print(status)
在python3中的urllib将不会有urllib.urlencode命令存在,而是改为了urllib.parse.urlencode。
下面讲详细学习记录python3的urllib的变化。
python3.x 的urllib学习记录
详情参考简书作者大大的整理 ————————》》》》可跳转
urllib库的模块
- 第一个模块 request,它是最基本的 HTTP 请求模块,我们可以用它来模拟发送一请求,就像在浏览器里输入网址然后敲击回车一样,只需要给库方法传入 URL 还有额外的参数,就可以模拟实现这个过程了。
- 第二个 error 模块即异常处理模块,如果出现请求错误,我们可以捕获这些异常,然后进行重试或其他操作保证程序不会意外终止。
- 第三个 parse 模块是一个工具模块,提供了许多 URL 处理方法,比如拆分、解析、合并等等的方法。
- 第四个模块是 robotparser,主要是用来识别网站的 robots.txt 文件,然后判断哪些网站可以爬,哪些网站不可以爬的,其实用的比较少。
———————————————》》》》转载自(https://www.jianshu.com/p/63dad93d7000)
发送请求
- 1、urlopen()
API
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
- 2.Request
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
- 第一个 url 参数是请求 URL,这个是必传参数,其他的都是可选参数。
- 第二个 data 参数如果要传必须传 bytes(字节流)类型的,如果是一个字典,可以先用 urllib.parse 模块里的urlencode() 编码。
- 第三个 headers 参数是一个字典,这个就是 Request Headers 了,你可以在构造 Request 时通过 headers参数直接构造,也可以通过调用 Request 实例的 add_header() 方法来添加, Request Headers最常用的用法就是通过修改 User-Agent 来伪装浏览器,默认的 User-Agent 是Python-urllib,我们可以通过修改它来伪装浏览器。
- 第四个 origin_req_host 参数指的是请求方的 host 名称或者 IP 地址。
- 第五个 unverifiable 参数指的是这个请求是否是无法验证的,默认是False。意思就是说用户没有足够权限来选择接收这个请求的结果。例如我们请求一个 HTML 文档中的图片,但是我们没有自动抓取图像的权限,这时 unverifiable 的值就是 True。
- 第六个 method 参数是一个字符串,它用来指示请求使用的方法,比如GET,POST,PUT等等。
作者:NewForMe
链接:https://www.jianshu.com/p/63dad93d7000
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
from urllib import request, parse
url = 'http://httpbin.org/post'
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)',
'Host': 'httpbin.org'
}
dict = {
'name': 'Germey'
}
data = bytes(parse.urlencode(dict), encoding='utf8')
req = request.Request(url=url, data=data, headers=headers, method='POST')
response = request.urlopen(req)
print(response.read().decode('utf-8'))
req = request.Request(url=url, data=data, method='POST')
req.add_header('User-Agent', 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)')














 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









