







平衡树之Treap
Treap是个啥
Treap,很奇怪的名字.但是如果能拆成Tree+heap,那么就好理解了:既是树(二叉搜索树),又是堆(最大最小随意,本文中使用最小堆).
Treap是非常暴力的一种平衡树实现,它利用一个随机值,在按照二叉搜索树的规则插入元素之后再(如果必要)通过旋转维持堆的性质,提供不确定的变形机会,避免出现树高为
O(n)
的最坏情况.事实上,Treap的期望高度为
O(logn)
.因为暴力,所以其并不能保证绝不会出现最坏的情况,但出现最坏情况的几率极小(甚至远小于电脑被闪电击中的几率?),而且实现简单,因此很好用.
需要注意的是,数据遵守的是查找树的规则,而随机权值遵守的是堆的规则.
前置知识
- 二叉搜索树
- 递归
- 引用
结构定义
由于链式结构看起来太复杂,而且应用引用可以大大的简化代码,我们不定义结构体,而是使用一系列数组.定义如下:
const int MAX=10010; //数据范围来自洛谷上的普通平衡树,连接下面有
int rear=1; //下一个新开节点的下标
int val[MAX]; //节点存储的值
int w[MAX];
int cnt[MAX]; //节点存储的值重复的次数
int size[MAX]; //以节点为根的子树规模(总值数量,包括重复)
int lt[MAX]; //节点的左孩子
int rt[MAX]; //节点的右孩子
//特殊的,我们令lt[0]指向根节点(其实没必要),有效的节点下标不为0很明显,我们在结构中定义了一般的平衡树不必须的数据size.事实上,我们会维护这个数据以进行数据的”排名”的统计和查找特定排名的元素.
在这里,代码实现的功能以及一些细节取决于洛谷上的P3369 【模板】普通平衡树(Treap/SBT).
Treap的各种操作
基本操作
首先,我们需要多次更新节点的size值.我们定义一个函数来简化代码.函数接受一个指向节点的指针作为参数,按照其左右子树(如果存在)的信息更新自身的size值,无返回值.为了提高效率,函数将被定义为内联函数.函数假设传入的指针不指向NULL.
inline void updata(const int& k)
{
size[k]=cnt[k];
if(lt[k]) size[k]+=size[lt[k]];
if(rt[k]) size[k]+=size[rt[k]];
return;
}不难看出,由于没有改变任何树的结构,updata操作不会导致Treap的性质遭到破坏.
为了保持堆的特性同时不影响搜索树的性质,我们再定义一种操作:旋转.旋转分为左旋转和右旋转,具体操作如图:
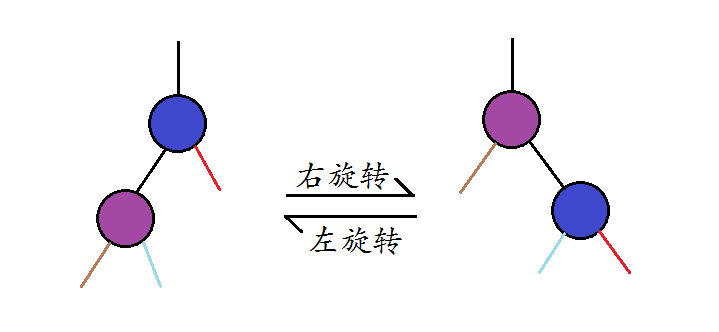
这一对操作是对称的.对照图示,代码不难写出.代码中,我们传入指向上方节点的下标指针的引用来简化代码.函数同样定义为内联函数.在左,右旋转函数中,我们分别假设参数所指向的节点的右,左孩子不为空(事实上,我们会看到,在之后的代码中只有满足这一条件是才会进行旋转).
inline void left_rot(int& k)
{
int t=rt[k];
rt[k]=lt[t];
lt[t]=k;
size[t]=size[k];
updata(k);
k=t;//运用引用的性质直接更新指针
return;
}
inline void right_rot(int& k)
{
int t=lt[k];
lt[k]=rt[t];
rt[t]=k;
size[t]=size[k];
updata(k);
k=t;
return;
}这就是Treap新增的(updata似乎都不算新增的)基本操作.这些将帮助我们再各种操作中保持这棵树的性质.关于旋转不会影响整棵树的性质的证明是显然的,懒,不证明了.
插入数据
这是二叉搜索树的基本操作.在Treap中,它的前半部分操作和搜索树是几乎一样的,只是增加了为w(随机权重)赋值.因此这部分操作直接给出代码,简单注释.事实上,Treap仅在原来的基础上添加了两句话,意义是相同的:如果插入节点的随机权值破坏了结构,用适当的旋转修正之.
void insert_val(int v,int& t=lt[0]) //同样使用引用,用默认值简化调用代码
{
if(t==0)//到了叶子节点
{
val[rear]=v;
w[rear]=rand();//调用随机函数提供随机权重
cnt[rear]=1;//只有一个
size[rear]=1;
lt[rear]=rt[rear]=0;
t=rear++;//修改指针,移动边界
return;
}
size[t]++;//无论何种情况,当前节点的size一定会加1
if(val[t]==v)//这个值已经存在了
{
cnt[t]++;
return;
}
if(val[t]>v){
insert_val(v,lt[t]);
if(w[lt[t]]<w[t]) right_rot(t);//出现不当的结构,旋转修复
}else{
insert_val(v,rt[t]);
if(w[rt[t]]<w[t]) left_rot(t);//同上,注意旋转方向
}
return;
}不难看出,插入操作可以在
O(h)
的时间内完成,其中
h
是这棵树的高度.而之前已经提到过,Treap的期望高度是
删除数据
在Treap上删除数据首先可以分为两种情况,该数据重复多次或是只出现了一次.对于第一种情况,我们只需要更新size的值并对目标节点k执行cnt[k]--即可,是相当简单的.而另一种情况又可以分为三种情况:
- 当前节点没有任何子节点
- 当前节点只有一个子节点
- 当前节点有两个子节点
对于第一种情况,只需要利用引用直接修改其父节点的指针,直接删除当前节点就可以了;
对于第二种情况,直接用那个子节点替换当前节点即可;
对于第三种情况,稍稍有些棘手,我们有两种方式处理这种情况.
第一种方法是直接使用当前节点的前驱节点或是后继节点取代当前节点,这种方法的正确性很显然,效率也很优,但我们这里不会使用这种方法,因为这种方法会导致代码变得复杂而且会增加较多的常数(我承认是我太蒻导致的).
前驱:比当前节点的值小的最大节点
后继:比当前节点的值大的最小节点
另一种方法是按照保持Treap结构要求的方式不断旋转当前节点,递归的删除当前节点,直到某次旋转后满足以上的其他情况,此时即可直接删除.这种方法的正确性同样显然,因此我同样不打算加以证明.在这里我们使用这种方式删除节点.
在删除过程中,我们同样需要维护节点的size值.但是我们不能在向下的过程中就草率的修改途径节点的size值,因为我们没有得到被删除的值一定存在的保证.因此,我们定义删除函数的返回值为bool型,在成功删除后返回true,否则返回false,这样就可以在返回时完成对size的维护.
按照以上的讨论,我们可以写出这样的代码.
bool del_val(int v,int t=lt[0])
{
if(t==0) return false;//删除的值不存在
if(val[t]==v)//当前节点要删除
{
if(cnt[t]>1)
{
cnt[t]--;//重复了超过一次
size[t]--;
return true;
}
if(!lt[t] || !rt[t]) t=lt[t]+rt[t];//有至少一个子节点为空,直接用另一个取代当前节点
else{
if(w[lt[t]]>w[rt[t]]){
left_rot(t);//适当的旋转
del_val(v,lt[t]);//递归删除
}else{
right_rot(t);
del_val(v,rt[t]);
}
updata(t);//不要忘记更新当前节点的数据
return true;
}
bool tmp;//保存返回值
if(val[t]>v) tmp=del_val(v,lt[t]);//递归的进行删除
else tmp=del_val(v,rt[t]);
if(tmp) size[t]--;//如果需要,进行更新
return tmp;
}由于在递归调用过程中当前节点指针总是向下移动的,因此最多会进行 O(h) 次递归调用,删除元素的时间复杂度也就是 O(h)=O(logn) .
至此,我们已经完成了Treap中最复杂的一部分:Treap结构和性质的维护.之后实现的所有操作都是不会修改任何值的.
求某数的排名
首先,对排名加以定义如下:
数k的排名是:当前存在的比k小的数的数量+1.
例如:在动态集合(是不是动态集合似乎在这里没关系诶) {1,5,2,3,8,6,4,9,5,5} 中, 5 的排名是5.
我们注意到,在一棵以k所在节点为根的子树中,k的排名就是这个节点的左孩子的size值加上1(视左孩子为空的情况为左孩子的size值为1).因此, 我们可以从树根向下递归的进行求解.任意时刻的情况可以分为三种(设当前节点为k):
当前节点的值就是要进行排名的值
对于这种情况,直接返回size[lt[k]]+1就好了.注意处理lt[k]==0的情况.当前节点的值大于要排名的节点
这种情况下直接求要排名的值在当前节点的左子树中的排名就可以了.当前节点的值小于要排名的值
这种情况比前两种稍微复杂一点.在这种情况下,当前节点的左子树中的所有值以及当前结点本身都是小于要排名的值的.因此结果应该是当前节点的左子树大小加上当前节点的值重复出现的次数再加上要排名的值在当前节点右子树中的排名.
这几种情况都不难处理,因此排名的代码非常简单:
int rank_val(int v,int k=lt[0])//由于不会修改,不再使用引用
{
if(k==0) return -1;//查询的值不存在(然而并没有写相应的处理这个错误的代码)
if(val[k]==v)
{
if(lt[k]) return size[lt[k]]+1;//umm并没有很好的利用哨兵节点
return 1;
}
if(val[k]>v) return rank_val(v,lt[k]);
if(lt[k]) return size[lt[k]]+cnt[k]+rank_val(v,rt[k]);
return cnt[k]+rank_val(v,rt[k]);
}同样,一次操作中最多由树根进行到叶子节点,每层只会执行
查询排名为某值的数
这个操作实质上和上一个操作的思路是几乎相同的,因此这里不再重复思路,直接上代码.
int kth_val(int rank,int k=lt[0])
{
if(k==0) return -1;
if(lt[k])
{
if(rank<=size[lt[k]]) return kth_val(rank,lt[k]);//排名不超过左子树大小的数一定就是左子树中这个排名的数
rank-=size[lt[k]];//除去左子树中的数,现在要找的是当前节点和其右子树中的排名为rank的数
}
if(rank<=cnt[k]) return val[k];
rank-=cnt[k];//再除去当前节点的数
return kth_val(rank,rt[k]);
}同理,时间复杂度为 O(logn) .
查询某个数的前驱
设所查询的某个数为v.
我们采用一个非常直观的思路:一路查询到v并继续查询其左子树直到叶子节点,维护其中路径上遇到的小于v的最大值,那就是我们所要查询的v的前驱.查询过程和在普通二叉搜索树中查找某个特定值几乎一样,只是增加了对最大值的维护.代码如下:
int pre_val(int v,int k=lt[0])
{
if(k==0) return 0x7fffffff+1;//到达叶子节点,返回极小值以消除影响(通过自然溢出)
int ans=0x7fffffff+1;
if(val[k]<v)//当前值可能是v的前驱
{
ans=max(ans,val[k]);
return max(ans,pre_val(v,rt[k]);//递归调用并返回找到的最大的值(向右子树找更大的值)
}
return pre_val(v,lt[k]);//递归调用,向左子树找更小的值
}查询某个数的后继
和上一个操作的思路完全一样.将max变为min,将l和r以及小于号还有极值反转,就获得了查询后继的代码:
int nex_val(int v,int k=lt[0])
{
if(k==0) return 0x7fffffff;
int ans=0x7fffffff;
if(val[k]>v)
{
ans=min(ans,val[k]);
return min(ans,nex_val(v,lt[k]);//递归调用并返回找到的最大的值(向右子树找更大的值)
}
return nex_val(v,rt[k]);//递归调用,向左子树找更小的值
}同理,不难得出,求前驱和后继的操作的时间复杂度都是 O(logn) .
完整模板代码
将上面的操作整合起来,写好主函数(话说这个模板题的主函数好复杂,操作太多了),就得到了能够AC这道模板题的代码.
#include<cstdio>
#include<cstdlib>
#include<ctime>
#include<algorithm>
using namespace std;
const int MAX=100010;
int rear=1;
int val[MAX]; //存储的值
int cnt[MAX]; //重复次数
int size[MAX]; //子树大小
int w[MAX]; //随机权重
//使用lt[0]指向根
int lt[MAX]; //左子树指针
int rt[MAX]; //右子树指针
inline void updata(int k) //更新子树大小
{
size[k]=cnt[k];
if(lt[k]!=0) size[k]+=size[lt[k]];
if(rt[k]!=0) size[k]+=size[rt[k]];
return;
}
inline void left_rot(int &k) //左旋转
{
int t=rt[k];
rt[k]=lt[t];
lt[t]=k;
size[t]=size[k];
updata(k);
k=t;
return;
}
inline void right_rot(int &k) //右旋转
{
int t=lt[k];
lt[k]=rt[t];
rt[t]=k;
size[t]=size[k];
updata(k);
k=t;
return;
}
void insert_val(int v,int& t=lt[0]) //插入
{
if(t==0) //树中无值为val的节点,需要创建
{
val[rear]=v;
cnt[rear]=1;
size[rear]=1;
w[rear]=rand();
lt[rear]=0;
rt[rear]=0;
t=rear++; //利用引用直接修改父节点的相应指针精简代码
return;
}
size[t]++; //无论如何进行,t的size一定增加1
if(val[t]==v){cnt[t]++;return;} //值为val的点被找到了,直接累加出现次数
if(val[t]>v){
insert_val(v,lt[t]);
if(w[lt[t]]<w[t]) right_rot(t); //如果必要进行旋转
}else{
insert_val(v,rt[t]);
if(w[rt[t]]<w[t]) left_rot(t); //如果必要进行旋转
}
return;
}
bool del_val(int v,int& t=lt[0])
{
if(t==0) return false; //val并不存在
if(val[t]==v) //找到了,要删除了
{
if(cnt[t]>1){cnt[t]--;size[t]--;return true;} //如果还存在val直接返回
if(!lt[t] || !rt[t]) t=lt[t]+rt[t]; //如果有一个子节点为空,直接用另一个取代当前节点
else{
if(w[lt[t]]>w[rt[t]]){
right_rot(t);
del_val(v,rt[t]);
}else{
left_rot(t);
del_val(v,lt[t]);
}
updata(t);
}
return true;
}else{
bool tmp;
if(v>val[t]) tmp=del_val(v,rt[t]);
else tmp=del_val(v,lt[t]);
if(tmp) size[t]--;
return tmp;
}
}
int rank_val(int v,int k=lt[0])
{
if(k==0) return -1; //不存在
if(val[k]==v)
{
if(lt[k]!=0) return size[lt[k]]+1;
return 1;
}
if(val[k]>v) return rank_val(v,lt[k]);
if(lt[k]!=0) return size[lt[k]]+cnt[k]+rank_val(v,rt[k]);
return cnt[k]+rank_val(v,rt[k]);
}
int kth_val(int rank,int k=lt[0])
{
if(k==0) return -1;
if(lt[k]!=0)
{
if(size[lt[k]]>=rank) return kth_val(rank,lt[k]);
rank-=size[lt[k]];
}
if(rank<=cnt[k]) return val[k];
rank-=cnt[k];
return kth_val(rank,rt[k]);
}
int pre_val(int v,int k=lt[0])
{
if(k==0) return 0x7fffffff+1;
int ans=0x7fffffff+1;
if(val[k]<v)
{
ans=max(ans,val[k]);
return max(ans,pre_val(v,rt[k]));
}
return pre_val(v,lt[k]);
}
int nex_val(int v,int k=lt[0])
{
if(k==0) return 0x7fffffff;
int ans=0x7fffffff;
if(val[k]>v)
{
ans=min(ans,val[k]);
return min(ans,nex_val(v,lt[k]));
}
return nex_val(v,rt[k]);
}
int main()
{
srand(time(0));//不要忘了设置随机种子!
int n,opt,v;
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
scanf("%d%d",&opt,&v);
switch(opt)
{
case 1:
insert_val(v);
break;
case 2:
del_val(v);
break;
case 3:
printf("%d\n",rank_val(v));
break;
case 4:
printf("%d\n",kth_val(v));
break;
case 5:
printf("%d\n",pre_val(v));
break;
case 6:
printf("%d\n",nex_val(v));
break;
default:
break;
}
}
return 0;
}对完整代码的(胡乱)分析
复杂度
对于包含n个节点的Treap,其各种操作的时间复杂度在期望意义上都可以在不超过 O(logn) 的时间内完成.这一点由随机化保证,因此存在出现效率不佳的情况的可能,但其概率极小.而且很容易得到,即使在数个深度较小的节点处出现了只有一侧子树的情况,其对整体的性能影响也是很小的.因此,即使Treap只是一个平衡树的 “暴力”实现,也可以对其性能有坚定的信心.
进一步优化
虽然上面的代码保证了Treap的正确性和一定的运行效率,我们还能做的更好.主要有以下几方面可以进行优化.
替换随机函数
确实,C++提供的rand()函数比较方便,但它略大的常数也成为了影响效率的因素(虽然不很明显).因此,可以考虑手写随机函数加以替代.比如这样(原理自行百度,很容易就能找到):
int seed=1583;//随机种子的初始值也可以随意
inline int rand(){
return seed = (int)((((seed ^ 998224373) + 19330819ll) * 19870803ll) % 1000000007);
//其实这句中return seed=后面的表达式是可以随便写的,但会影响生成随机数的质量
}构造内存池
可以注意到,即使有些节点被删除了,占用的空间也不会被释放:插入新节点时仍会开辟新的空间.这就造成了所谓的内存泄漏.在上面提到的题目中这个问题并不会影响什么,但是作为一个目的是稳定高效的数据结构,同时作为一个好习惯,应该高度关注内存泄漏.因此,可以再实现一个内存池来解决这个问题(不要问我为什么不用链式结构.感觉太丑了).
这个问题中的内存池只需要利用栈或队列之类的数据结构保存被删除释放的空间信息(下标),并在请求时返回相应的值即可.比如这样:
struct mem//想不好名字可还行
{
private:
queue<int> q;
int rear;//就是之前代码中的rear
public:
mem()
{
rear=1;//初始化
}
void free(int t)//释放内存
{
q.push(t);
return;
}
int allocate(void)//分配内存
{
if(!q.empty())//优先分配之前释放的内存
{
int tmp=q.front();
q.pop();
return tmp;
}
rear++;
return rear;
}
};之后在之前代码中创建新节点的地方改用mem.allocate()(虽然不可能,还是假设这就是对象名)获取内存,在适当的地方添加mem.free()释放内存.
修改为迭代形式
当树很高时(然而一般你已经先超时了),递归可能带来栈溢出.而且即使不会,在多数计算机上运行时,递归的效率也一般低于迭代.因此,将递归改为用while循环完成的迭代形式在某些情况下是不错的主意(但是不推荐在不必要时进行,因为这样会导致代码量提升).
封装为结构体
在单一的程序中其实没什么必要(尤其是只是为了AC上面的题的话),但是封装进结构体可以让其更直观的作为一种数据结构出现,同时也是当需要操作多个Treap时的最佳选择.
后记
虽然是非常暴力的随机化思想,但是无可否认,这样完成的Treap的效率确实很高,而且也很难被卡:甚至作者自己都不知道自己的Treap会干些什么.在一般情况下,为了实现上面题目中的操作,Treap应该会是我的首选吧.
如果哪里出现了什么错误,请路过的大犇不吝赐教,多谢了.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









