







ES高可用及集群管理
Elasticsearch 是一个分布式、高扩展、高实时、RESTful 风格的搜索与数据分析引擎。
- 服务可用性:允许有节点停止服务
- 数据可用性:部分节点丢失,不会丢失数据
- 水平扩展
- 集群容错
一、分片
1、什么是分片及其作用
节点:一个运行中的ES实例成为一个节点;
集群:由一个或者多个拥有相同cluster.name配置的节点组成;
分片:分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。
一个索引可以存储超出单个节点硬件限制的大量数据,会出现索引数据量大,响应慢等问题;ES把一个索引划分成了多份,每个分片都是功能完善且独立的索引,这些分片分配到集群中的各个节点上。
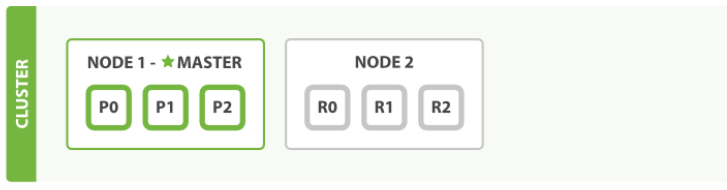
分片分为主分片和副本分片,对文档的新建、索引、删除等写操作,必须在主分片上完成之后才能被复制到相关的副本分片; 副本分片是主分片的一个副本,防止硬件故障导致数据丢失;提供读请求;当主分片异常,副本分片可以升级成主分片提供服务;高可用的一个保障;
主分片和副本分片不会在同一个节点上,防止单点故障。如果其中一个节点宕机,任然可以从剩余节点中获取到一个索引的完整数据
//创建索引的时候指定分片数
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
主分片数定义好后不能修改:shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。
数据写入流程:

2、分片负载均衡
Shard会被均衡的分配到每个节点上,且主分片和副本分片不会在同一个节点上。
master节点根据现在各个数据节点上的主分片分布情况来安排哪些节点来接收新的索引的主分片,根据各个数据节点上的总分片的分布情况来安排哪些节点来接收新的索引的副本分片。本着集群各数据节点总体均衡的策略来安排节点。
水平扩容:新增机器,会自动集群发现加入集群,同时自动分片负载均衡,进行分片迁移
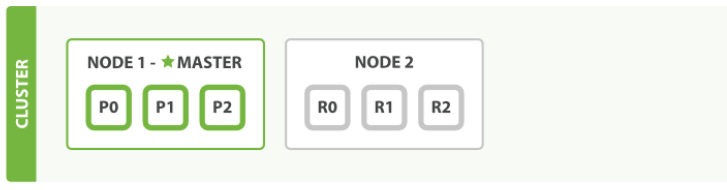
添加第三个节点,为了分散负载对分片进行重新分配

(1)如果需要修改主分片数该怎么做
通过reindex
就是创建一个新的索引,将原来索引的数据迁移到新的索引里面去,以达到修改的目的。
-
创建一个新的索引,设置副本数为0(使用零副本进行索引,然后在提取完成时启用副本,则恢复过程本质上是逐字节的网络传输。 这比复制索引过程更有效。)
-
增加refresh间隔,再导入期间何以设置为-1来禁用刷新。
PUT /my_index/_settings { "refresh_interval": -1 } -
数据迁移
POST _reindex?slices=auto&wait_for_completion=false { "source": { "index": "old_index", "size":
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1931
1931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









