







目录
Advice for Applying Machine Learning
Evaluating a Learning Algorithm
Model Selection and Train/Validation/Test Sets
Regularization and Bias/Variance
Deciding What to do Next Revisited
Machine Learning System Design
Error Metrics for Skewed Classes
Trading Off Precision and Recall
Advice for Applying Machine Learning
Evaluating a Learning Algorithm
Evaluating a Hypothesis
如果一个ML system表现得比较差,常见的优化方法有:
- 获得更多的训练集数据
- 使用少一点的features
- 增加新的的features
- 根据现有的features做多项式组合
- 增大或减少bias项的λ
但是我们如何知道哪些方法对现在的system是生效的,哪些是无效的呢?这需要根据具体的情况进行分析。
Model Selection and Train/Validation/Test Sets
在实际问题中不会像Kaggle那样提供test数据集,往往是有一个整的data samples,然后我们对数据进行划分,来训练、选择和评估模型。
如果我们只划分为两个集合,训练集和测试集,然后选训练集中误差最小的,我们可能并不能公平正确的对模型进行评价,因为我们挑选的可能是对训练集过拟合的预测模型。这里引入了validation集,一般来说数据划分的比例为:
-
Training set: 60%
-
Cross validation set: 20%
-
Test set: 20%
三个集合的作用分别为:
-
training set:对不同的多项式设计,得到不同的预测权重θ
-
cross validation set:根据1中的θ对cv集处理,计算误差后得到使误差最小最佳的多项式维度d
-
test set:把它们看做新得到的之前未知的数据,对2中得到的具体θ进行评价
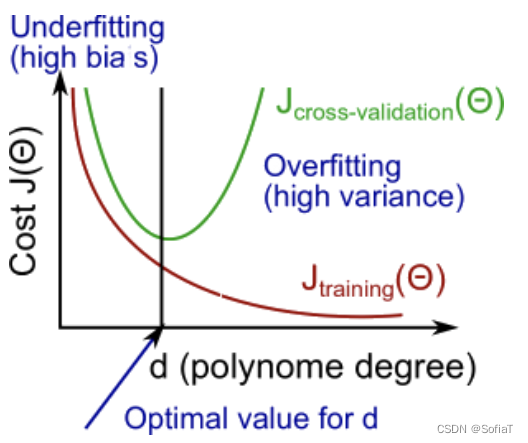
Bias vs. Variance
Diagnosing Bias vs. Variance
High bias(underfitting):具体表现为数据量小时train的cost低,cv的值高,当数据达到一定规模时,二者接近相等
High variance(overfitting):具体表现为train的cost function值低,cv的高,当数据达到一定规模时,二者仍有明显差距
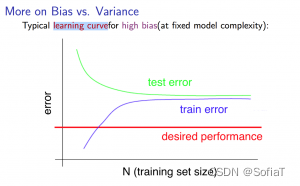

而我们训练模型的目的,就是找到一个合适的模型复杂程度,把误差降到可接受范围
Regularization and Bias/Variance
合适的正则化有助于解决过拟合or欠拟合问题。如何选择lambda?
- 创建一个列表λ∈{0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24}
- 建立一组模型,包含多个不同的维度或变量的组合
- 对所有的模型遍历λ,并计算损失函数Θ
- 用cv对得到的Θ进行测试(注意此时损失函数中的λ=0,这里是做评价而非梯度下降minimize)
- 选择cv上表现最佳的Θ并将其应用于测试集
- 看问题是否有好的泛化解决
Deciding What to do Next Revisited
fixes high variance:
- 更多训练集
- 更少的features
- 增大λ
fixes high bias:
- 增加features
- 新增features的多项式组合
- 减少λ
对于神经网络有:
- 参数少容易欠拟合,但是计算消耗小
- 参数多的容易过拟合,但是计算成本高。可以正则化来减弱过拟合
- 使用单个隐藏层作为启动,然后用cv验证不同隐藏层的效果,选择性能最佳的
Machine Learning System Design
Building a Spam Classifier
Prioritizing What to Work On
给定一个数据集,我们可以为每封电子邮件构建一个向量作为x。 此向量中的每个条目代表一个单词。 该向量通常包含 10,000 到 50,000 个条目,是通过在数据集中查找最常用的单词而收集的。 那么怎么提高准确性呢?
- 收集大量数据
- 开发复杂的功能(例如:使用邮件标题数据)
- 算法以不同方式处理输入(识别垃圾邮件中的拼写错误)
很难说哪个选项最有帮助。
Error Analysis
解决机器学习问题的推荐方法是:
- 从一个简单的算法开始,快速实施它,并在cv data上尽早对其进行测试。
- 绘制学习曲线以确定更多数据、更多特征等是否有帮助。
- 手动检查cv data中label预测出错的数据,并尝试找出大多数错误发生的趋势,找到可以用来取分它们和一般数据的features
Handling Skewed Data
Error Metrics for Skewed Classes
在supervised learning中,如果某个label占的比例超过正常值(例如,假设cancer检测中99%的samples是良性,只有1%是恶性),模型可能倾向于恒定判断结果y为某label,因为这确实能让误差值变得很小。像这样的数据就是skewed data。

这里引入一种正确预测占比的方式作为评估,定义如下:
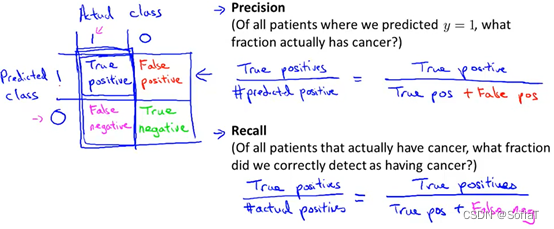
可以分为 true positive、false positive、true negative、false negative。positive/negative为预测值,true/false为实际值与预测值是否相等。
Precision = True pos / (True pos + False pos)
Recall = True pos / (True pos + False neg)
Trading Off Precision and Recall
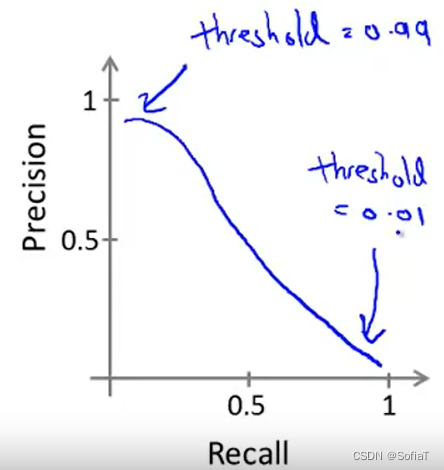
之前的logistic regression中,默认概率以0.5为分界点来标志0/1,但在遇到skewed data时,可以根据实际需要来定义threshhold

![]()
可以看到,cancer问题中,想要尽可能精准的判断出恶性癌,就需要threshold越大。反之想要避免漏判,threshold越小。
可以用F1作为自动判最优的指标来调节threshold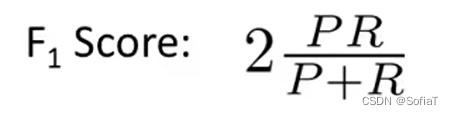
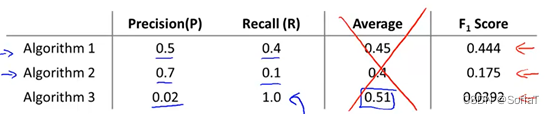
Using Large Data Sets
Data For Machine Learning
在生产环境下,使用哪种算法带来的准确率提升差异不大,而数据量差异带来的准确率提升很大:
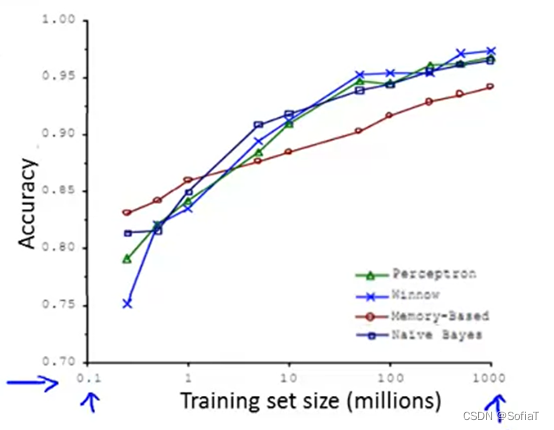
原因在于,当模型的features非常多时,此时是low bias的,能够使训练集的cost function值偏小。而在拥有很多training data时,使train和test的cost function不断接近,于是test的cost func值也偏小。拥有多features和大data set的模型往往会表现的很好,是low bias同时又low variance的。

一般来说,可以先人工分析一下,当前的features如果手工判定,能否得到一个较好的预测结果,以此为根据看features是否充足。然后再尽可能多的扩充data set。
ex-5
这次的实验比较简单,给的data X初始只有一个features,y也是一维。总结一下从可视化到拟合。
实验过程
1. 数据load后可视化,画出X和y的图像
2. 选择一个简单的模型做预测
3. 让数据量从小到大变化,画出train和cv的Learning Curve,看当前模型有哪些问题
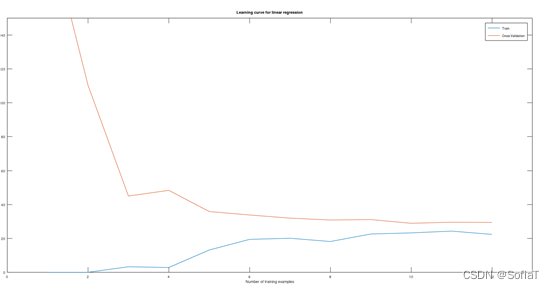 如图,明显为high bias
如图,明显为high bias
4. 做了映射,把当前数据X组合了多个多项式,再正则化
5. 4中新数据集再加上bias项,重新预测,bias的lambda取数组,看结果选表现最好的
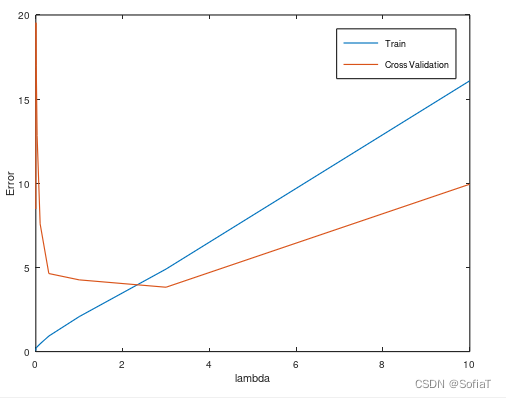
疑问
1. 之后在kaggle上训练时,如何把具有大量features的高维数据做可视化并分析?
2. 好像ex5给的有个画图函数有问题(tbc)















 1578
1578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









