






索引:帮助MySQL高效获取数据的有序的数据结构。
假设我们有一张表table,包含Clo1和Clo2两个字段
| 内存地址 | Clo1 | Clo2 |
|---|---|---|
| 0x07 | 1 | 36 |
| 0x5A | 2 | 20 |
| 0x7A | 3 | 80 |
| 0xF3 | 4 | 8 |
| 0x77 | 5 | 28 |
| 0xD1 | 6 | 66 |
| 0x89 | 7 | 88 |
在没有索引情况下的执行下面SQL
select * from table where Clo2 = 66;过程如下:
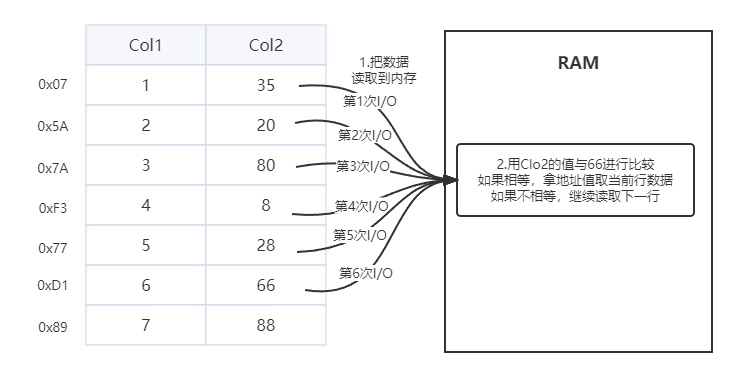
在没有

 MySQL索引数据结构二叉树、红黑树、B-Tree、B+Tree、Hash
MySQL索引数据结构二叉树、红黑树、B-Tree、B+Tree、Hash
索引:帮助MySQL高效获取数据的有序的数据结构。
假设我们有一张表table,包含Clo1和Clo2两个字段
| 内存地址 | Clo1 | Clo2 |
|---|---|---|
| 0x07 | 1 | 36 |
| 0x5A | 2 | 20 |
| 0x7A | 3 | 80 |
| 0xF3 | 4 | 8 |
| 0x77 | 5 | 28 |
| 0xD1 | 6 | 66 |
| 0x89 | 7 | 88 |
在没有索引情况下的执行下面SQL
select * from table where Clo2 = 66;过程如下:
在没有
 818
1093
818
1093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
























