









注:文本由U神原创,转载请注明作者和出处。
目录:
0×00、什么是Acunetix Web Vulnarability Scanner ( What is AWVS?)
0×01、AWVS安装过程、主要文件介绍、界面简介、主要操作区域简介(Install AWVS and GUI Description)
0×02、AWVS的菜单栏、工具栏简介(AWVS menu bar & tools bar)
0×03、 开始一次新扫描之扫描类型、扫描参数详解(Scan Settings、Scanning Profiles)
0×04、AWVS的应用程序配置详解(Application Settings)
0×05、AWVS的蜘蛛爬行功能(Site Crawler)
0×06、AWVS的目标探测工具(Target Finder)
0×07、AWVS的子域名探测工具(Subdomain Scanner)
0×08、AWVS的SQL盲注测试工具(Blind SQL Injection)
0×09、AWVS的HTTP请求编辑器(HTTP Editor)
0×10、AWVS的HTTP嗅探工具(HTTP Sniffer)
0×11、AWVS的HTTP模糊测试工具(HTTP Fuzzer)
0×12、AWVS的认证测试工具(Authentication Tester)
0×13、AWVS的WEB WSDL扫描测试工具(Web Services Scanner、Web Services Editor)
0×00、什么是Acunetix Web Vulnarability Scanner
Acunetix Web Vulnerability Scanner(简称AWVS)是一款知名的Web网络漏洞扫描工具,它通过网络爬虫测试你的网站安全,检测流行安全漏洞。它包含有收费和免费两种版本,AWVS官方网站是:http://www.acunetix.com/,目前最新版是V10.5版本,官方下载地址:https://www.acunetix.com/vulnerability-scanner/download/,官方免费下载的是试用14天的版本。这里我们以V10.5破解版来讲解。
功能以及特点:
a)、自动的客户端脚本分析器,允许对 Ajax 和 Web 2.0 应用程序进行安全性测试。
b)、业内最先进且深入的 SQL 注入和跨站脚本测试
c)、高级渗透测试工具,例如 HTTP Editor 和 HTTP Fuzzer
d)、可视化宏记录器帮助您轻松测试 web 表格和受密码保护的区域
e)、支持含有 CAPTHCA 的页面,单个开始指令和 Two Factor(双因素)验证机制
f)、丰富的报告功能,包括 VISA PCI 依从性报告
h)、高速的多线程扫描器轻松检索成千上万个页面
i)、智能爬行程序检测 web 服务器类型和应用程序语言
j)、Acunetix 检索并分析网站,包括 flash 内容、SOAP 和 AJAX
k)、端口扫描 web 服务器并对在服务器上运行的网络服务执行安全检查
l)、可导出网站漏洞文件
0×01、AWVS安装过程、主要文件介绍、界面简介、主要操作区域简介
注:本文提供的破解 方式仅供软件试用,请于链接文字24小时内删除 ,如需使用请购买正版!
1、下载地址:http://pan.baidu.com/s/1i3Br6ol 提取密码:u60f 。其中 2016_02_17_00_webvulnscan105.exe是AWVS v10.5的安装包,而Acunetix_Web_Vulnerability_Scanner_10.x_Consultant_Edition_KeyGen_Hmily 是破解补丁。AWVS安装的方法与安装windows程序安装方法一样,我们这里主要讲解安装的主要点:
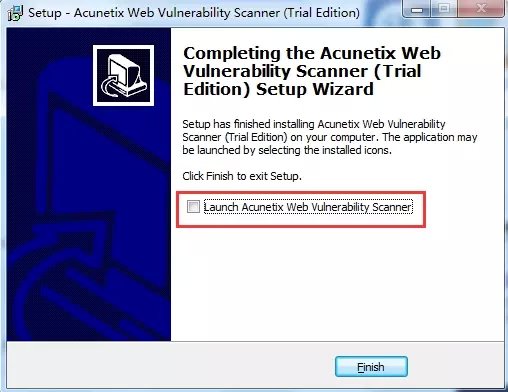
2、安装到最后一步的时候将“Launch Acunetix Web Vulnerbility Scanner”前的勾去掉,安装完成之后将会在桌面生成两个图标:


3、之后我们将破解补丁移动到AWVS的安装目录,打开破解补丁。点击patch之后便可以完成破解,最后关闭破解补丁。

4、破解之后,程序将弹出下面程序,直接点击next下一步


5、最后提示激活成功之后,直接Flish完成安装,提示Successfuly表示成功安装。

6、启动桌面上的Acunetix Web Vulnerability Scanner 10.5,在菜单栏上选择——Help——About可以看到AWVS的版本,以及包括“Program Updates”可检查软件更新,我们这里就不更新。毕竟我们下的是最新版的。

7、主要程序介绍:在程序安装路径“C:\Program Files (x86)\Acunetix\Web Vulnerability Scanner 10” 中主要文件的作用如下:

8、安装界面介绍:启动AWVS可以看到整个程序的界面

①、标题栏
②、菜单栏
③、工具栏
④、主要操作区域
⑤、主界面
⑥、状态区域
9:主要操作区域简介:

0×02、AWVS的菜单栏、工具栏简介(AWVS menus bar & tools bar)
a)、菜单栏
File——New——Web Site Scan :新建一次网站扫描
File——New——Web Site Crawl:新建一次网站爬行
File——New——Web Services Scan:新建一个WSDL扫描
Load Scan Results:加载一个扫描结果
Sava Scan Results:保存一个扫描结果
Exit:退出程序
Tools:参考主要操作区域的tools
Configuration——Application Settings:程序设置
Configuration——Scan Settings:扫描设置
Configuration——Scanning Profiles:侧重扫描的设置
Help——Check for Updates:检查更新
Help——Application Directories——Data Directory:数据目录
Help——Application Directories——User Directory:用户目录
Help——Application Directories——Scheduler Sava Directory:计划任务保存目录
Help——Schedule Wen Interface:打开WEB形式计划任务扫描处
Help——Update License:更新AWVS的许可信息
Help——Acunetix Support——User Mannul(html):用户HTML版手册
Help——Acunetix Support——User Mannul(PDF):用户PDF版手册
Help——Acunetix Support——Acunetix home page:AWVS官网
Help——Acunetix Support——HTTP Status:HTTP状态码简介
b)、工具栏

从左到右分别是(这些都可以在主要操作区域找到,所以不常用):
新建扫描——网站扫描——网站爬行——目标查找——目标探测——子域名扫描——SQL盲注——HTTP编辑——HTTP嗅探——HTTP Fuzzer——认证测试——结果对比——WSDL扫描——WSDL编辑测试——程序设置——扫描设置——侧重扫描设置——计划任务——报告
0×03:一次新的扫描的功能全面概述(Scan Settings:扫描类型、扫描参数)
1、点击菜单栏的 New Scan 新建一次扫描, 网站扫描开始前,需要设定下面选项:
1). Scan type
2). Options
3). Target
4). Login
5). Finsh
1、Scan type:

①:Scan single website:在Website URL处填入需要扫描的网站网址,如果你想要扫描一个单独的应用程序,而不是整个网站,可以在填写网址的地方写入完整路径。wvs支持HTTP/HTTPS网站扫描。
②:Scan using saved crawling results:导入WVS内置 site crawler的爬行到的结果,然后对爬行的结果进行漏洞扫描。
③:Access the scheduler interface:如果被扫描的网站构成了一个列表形式(也就是要扫描多个网站的时候),那么可以使用Acunetix的Scheduler功能完成任务,访问 http://localhost:8183,扫描后的文件存放在“C:\Users\Public\Documents\Acunetix WVS 10\Saves”.
Acunetix的计划任务,主要特性如下:
a). 可用于大量扫描,扫描结果保存在“C:\Users\Public\Documents\Acunetix WVS 10\Saves”。
b). 扫描结束,可以使用邮件通知。
c). 可设定计划时间,什么时候允许扫描,什么时候不允许扫描

2、Options:

Scanning options :侧重扫描的漏洞类型设置
①:Scanning profile:设置侧重扫描的类型,包含16种侧重检测类型,如下:

每种侧重扫描的类型又有包含多种扫描script,如果需要做调整或者修改,请查看 Configuration >> Scanning Profiles

Scanning Profiles中的每个侧重扫描的类型下都包含了非常多的扫描脚本,由于太多我就不一一介绍,随便点击一个,右边就有对该扫描脚本的介绍,随意抽选几个介绍,例如:
ftp_anonymous.script:扫描ftp匿名登录漏洞 PHPInfo.script:扫描是否有phpinfo泄露
Backup_File.script:扫描网站的备份文件 wordpress_8.script:针对 wordpress弱口令测试
你也可以选择扫描的脚本,然后新建自己的扫描策略,如下:

选择自己需要的策略,可以单击保存按钮保存一份策略,单击X按钮删除一个策略

Scan Setting:扫描配置
②:可定制扫描器扫描选项,AWVS在默认情况下只有“default”默认扫描参数配置策略,点击旁边的Customize则可以自定义:

与界面主操作区域对应:如下
(注意要点:如果在新建向导中设置Scan setting只会影响本次扫描的扫描参数设置,如果在主界面中的Scan Setting设置则是全局配置)

此处可以设置各种扫描参数配置,包括点击白色处“![]() ”是新建配置,单击X则是删除配置。
”是新建配置,单击X则是删除配置。
a)、Scan options 扫描配置

①:禁用蜘蛛爬行出发现的问题,AWVS在漏洞测试之前会使用蜘蛛功能对网站先进行测试,此处是禁用蜘蛛爬行发现的问题,如:错误的链接。一般这样的错误都是风险很低的警告信息。
②:scanning mode 是指扫描的模式分为三种如下:
Heuristic:标准的扫描模式,扫描线程和深度一致
Quick:快速扫描模式
Extensive:扩展性扫描,完整扫描模式
它们三种模式的扫描线程、深度如下:

③:目录爬行的递归深度,默认为5级,使用0则关闭
不要发出超过500个相同类型的警告,使用0则关闭
④:开启目标端口扫描功能,但该扫描速度较慢,建议使用NMAP端口扫描
⑤:收集不常见的HTTP请求状态,例如HTTP 500状态码
⑥:在扫描过程中如果服务器停止响应尝试25次之后中止扫描
⑦:在扫描过程中,是否使用网站设定的cookie
⑧:网站中链接到其它主机的文件,而这些网站与主站的关系相近,例如:www.baidu.com 链接中包含test.baidu.com,你可以在这里添加允许与主站关系很大的域名来进行扫描,可以使用通配符形式。这样扫描的时候将扫描这些主机的漏洞。
b)、Headers and Cookies 头部与Cookie

(a)、Test cookies for all files (by default it will only check files with parameters)
访问所有文件,都使用cookie测试(默认情况下,只有带参数的文件才使用cookie进行检测)。
(b)、Manipulate the HTTP headers listed below
操控HTTP头部信息,可按照自己的要求定制HTTP头。
(c)、Add Header
添加一个HTTP头部,在新增的“enter header name here”单击此处可以输入你的头部名称。
(d)、Remove Selected
移除你选中的HTTP头部
c)、Parameter Exclusion 扫描参数排除
有些参数不影响用户会话的操作,你可以排除这些参数被放在这个名单中,扫描器将不会去扫描测试这些参数,注意:名称应该为正则表达式

(a)、添加一个参数排除:
包含URL(*代表任何URL)、名字(要过滤的参数,一般以正则表达式表示)、type(请求方式,包含Any任何类型、GET、POST类型、COOKIE类型)
(b)、移除选中的排除
d)、GHDB 利用Google hacking数据库检测
Google hacking数据库设置,包含了1467条数据在数据库中

AWVS在扫描的过程中利用google hacking技术在google搜索引擎上对目标网站进行信息搜集。下面的语法是对网站的信息搜索的google语法。
(a)、Short description: 简要描述信息:(参考:http://baike.baidu.com/view/336231.htm )

(b)、Query String :Google上查询的字符
(c)、 Filter GHDB:GHDB过滤搜索 (Short description:简要描述 Query String 查询字符串 Full description:所有描述)
(d)、check visible:检测明显的 unchek visible:不检测明显的 check only visible:检测仅明显的
③: Crawling options 爬行设置:
针对特定的扫描场景,自定义爬虫的行为,这些选项将定义爬虫的行为:

start HTTP Sniffer for manual crawling at the end of process:蜘蛛爬行过程结束后启动HTTP嗅探,以发行更多链接。
Get first URL only:只扫描首页,不抓取任何链接。
Do not fetch anyting above start folder:不扫描上级目录,例如:新建扫描为http://www.baidu.com/cms/,将不会扫描cms上级目录的链接。
Fetch files below base folder:扫描子目录。
Fetch directory indexes even if not linked:获取目录索引,即使没有关联性的。
Retrieve and process robots.txt, sitemap.xml. :抓取并分析robots.txt、sitemap.xml中出现的目录、URL。
lgnore CASE differences in paths:忽略目录的大小写敏感
fetch default index files (index.php,default.asp):尝试获取每个目录下的默认索引文件,例如扫描http://qq.com,如果爬行到test目录则尝试获取test目录下是否有索引文件,例如:http://qq.c/test/index.php 。
try to prevent infinite derectory recursion:防止抓取到死循环的无限目录。如:http://qq.com/admin/admin/admin/admin/admin
crawl should request only linked files: 爬行应请求只有关联性的文件。
ignore parameters on file extensions like .js .css…etc:忽略文件扩展名类似为js css的参数。
disable auto custom 404 detection(application will use only user defined reles):禁用自动定制404检测(应用程序将使用用户定义的规则)。
consider www.domain.com and domain.com as the same host:如果启用该项那么AWVS会认为www域名和顶级域名是同一主机。
enable input limitaion heuristics:如果启用该选项,并在同一目录下的文件被检测20多个相同的输入方案,抓取工具只会抓取前20个相同的输入方案。
optimize inputs for known applications: 对已知应用程序输入的优化。
maximum num ber of variations:变化的最大数目,例如:http://www.baidu.com/index.php?id=1,这里设置ID的最大值为50。link depth limitation:链接深度限制,例如从A站点抓取发现了一个链接,又从该链接上发现另一个链接,以此类推最大深度默认为100。
structure depth limitation:子目录的最大深度的限制,默认最大15级目录。
maximun number of files in a derectory:在一个目录下AWVS爬取文件数量的最大值。
maximum number of path schemes:判断路径任务的最大任务数。
crawler file limit:爬虫爬行文件的数量限制。
④:file extension filters: 文件扩展名过滤

AWVS将读取该配置,尝试扫描哪些后缀的文件,例如排除掉的后缀文件,AWVS在工作的时候将不扫描被排除的后缀文件,因为扫描它们毫无意义。
a)、包含的扩展名,AWVS将会扫描的后缀扩展文件
b)、 排除的扩展名,AWVS将不扫描的后缀扩展文件
⑤: Directory and file filters:目录和文件过滤
定义一个目录列表被排除在爬行和扫描过程通配符允许您筛选一系列文件:如/dir1/* 或者/dir1/a *。表示将不扫描/dir1/下的文件,/dir1/a*表示的是不扫描dir1下以a开头的文件的漏洞。

a)、过滤的URL
b)、是否为正则表达式
⑥:URL Rewrite:URL重定向设置
一些网站使用URL重写,这里你可以定义一个列表的URL重定向不同网站帮助爬虫浏览这些网站。

⑦:HTTP Options
定义在爬行和扫描过程的HTTP头选项

(a)、用户当前的agent
(b)、定义不同浏览器的agent
(c)、检查最大的并发连接数
(d)、HTTP的请求超时时间
(e)、AWVS对两个请求之间延迟的毫秒,某些WAF对访问请求时间太快会进行拦截
(f)、HTTP请求的文件字节大小限制,默认5120kb
(h)、自定义HTTP 头部,例如自定义IP报头或者其它的HTTP头,如下:

⑧:Lan Settings
配置代理服务器来扫描网站漏洞

a)、http代理服务器
b)、Socks代理服务器
⑨:DeepScan
深度扫描,深度扫描技术,嵌入WebKit提供使用JavaScript基础技术如AJAX / HTML5和SPA 网站全面支持

a)、启用深度扫描
b)、扫描从外部引入的脚本中存在的漏洞,例如scr=http://www.qq.com/xx.jsp
c)、Session 超时的秒数
⑩:Custom Cookie
自定义Cookie,例如你在网站的登录之后获取Cookie,将Cookie添加到这来就可以实现预登陆状态下的扫描

a)、添加、移除自定义的cookie ,包含要添加的URL,使用*表示所有的URL,以及对应的Cookie值。
b)、扫描时锁定自定义的cookie
⑾:Input Fileds
此处主要设置提交表单时的字段对应的默认值,例如在HTML表单提交中出现age的字段,则会自动填写值为20。字段中:*web*中的是含有通配符的表示形式,例如1web2这样的就是满足*web*,而字段的值则有多种变量如下:
${alpharand}:a-z的随机字符串
${numrand}:0-9随机数字
${alphanumrand}:上两个的组合(随机字符串+随机数字)

(a)、从URL中 解析表单的字段,例如输入http://login.taobao.com 将从这里读取表单的字段,值如果有默认则填写默认,没有则需要自己添加,例如对wooyun.org自动提取表单的字段,预设值则需要自己设置,这样方便在扫描的时候AWVS自动填写预设的值去提交表单进行漏洞测试

(b)、添加、移除、前后顺序设置自定义的表单字段,包含:名字、值、长度
⑿ : AcuSensor
传感器技术 ,从这个节点,您可以启用或禁用acusensor和它的功能和设置密码。

(a)、启动AcuSensor技术
(b)、为AcuSensor设置密码
(c)、请求文件列表
(d)、开启服务器警告
(e)、在一个特定的URL上测试AcuSensor
⒀:Port Scanner
配置端口扫描程序的、socket、超时和端口设置

(a)、用户扫描端口的线程数
(b)、连接超时的毫秒时间设置
(c)、添加、移除扫描的端口,这里已经列举了常用的端口,AWVS将会扫描这里的端口。
⒂:Custom 404
自定义404页面,为了扫描中防止误报,应当自定义404页面

自定404页面的方式:

①:自定义404的URL
②:404页面的关键字匹配
③:匹配的关键字出现的位置
Location header:出现在HTTP头部
Result body:出现在HTTP的正文处
Result headers:出现在HTTP的头部+正文处
④:测试404页面是否存在Pattern中输入的,如果成功表示404页面中存在该关键字
⑤:是否为正则表达式
当然你可以单击向下展开的按钮,可以测试网站的404页面包括头部、浏览形式的查看,然后你可以选择404的关键字,通过点击“Generate pattern from selection”来生成404的关键字或者表达式,并且会自动设置出现的位置。

Adjust advanced scan setting:
在扫描向导中显示高级扫描设置,如下面的Advanced就是高级选项

Advanced:

进入高级之后分别是:
①:在爬行结果之后选择我们需要扫描哪些文件
②:自定义从哪里开始扫描,导入txt文件,例如扫描http://www.baidu.com,不想从根路径开始扫,而从二级目录http://www.baidu.com/test/,将其保存到txt文件中之后将从test二级目录开始扫描
③:爬行的时候使用外部测试工具,蜘蛛爬行的过程中将运行您设置的命令,以及超时时间设置
④:设置包含一个火狐扩展插件Selenium IDE生成的HTML文件,蜘蛛爬行的过程中将会根据它来进行爬行。
Target:

(a)、扫描目标的根路径
(b)、服务的banner
(c)、目标URL
(d)、目标操作系统
(e)、目标的Web容器
(f)、目标的程序语言
Login:

①:使用预先设置的登录序列,可以直接加载lsr文件,也可以点击白色处开始按照步骤新建一个登录序列(具体步骤参考后面的演示)
②:填写用户名密码,尝试自动登录.在某些情况下,可以自动识别网站的验证。
Finish:

①:使用AcuSensor传感技术的设置
②:爬行与扫描中是否区分大小写
③:将这次的设置保存为一个策略,以便下次直接使用策略
开始扫描:

①:

依次为:

#1、Generater report from this scan :
使用Configuration Settings可定制报告的某些信息,例如logo等.

转换为不同的格式报告:

②:扫描结果显示,包含存在漏洞的名字、链接、参数等,Site Structrus是网站爬行出的结构状态、Cookie是爬行的Cookie信息。

③:详情信息显示,需要点击左边的扫描结果才会展示详情信息。如下图就是左侧显示的SQL注入和参数,右边是SQL注入的详情。

如果不点击则是扫描的高低危漏洞统计,如下图就是威胁等级:Level 3,漏洞总结果是17个,High(红色):高危漏洞2个,Medium(橙色):中危漏洞8个,Low(蓝色):低危漏洞5个,Informational(绿色):提示信息2个。

④ :显示三个信息。
Taget Information:包含目标站点 1、是否应答、2、WebServer的banner、3、操作系统、4、Web容器、5、程序语言

Statistics:对扫描的各种信息统计,包含1、扫描的总时间、2、HTTP请求数量、3、平均扫描时间、4、扫描重复次数

Progress:扫描进度信息的提示,包含1、是否扫描完成,100.00%表示已完成,2、端口扫描是否完成 3、蜘蛛爬行是否完成(文件数量、目录数量、变量数量)、4、脚本信息 5、内部模块

⑤ 显示应用程序运行、测试的日志、错误日志。


















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









