







高度匿名、稳定安全、让数据采集变得更高效,使得HTTP代理在数据采集中发挥着至关重要的作用。
通过分散请求,HTTP代理避免了我们在做数据采集工作时,对单一IP的频率限制,同时提高了并发请求的能力,为我们获取更广泛而精准的数据提供了便利。
某书在当代产品营销运营中扮演着至关重要的角色。它为品牌提供了一个直接与用户互动的场所,通过内容创作、用户生成内容(UGC)、影响者营销等策略,建立了紧密的社区联系,提高了用户忠诚度。同时也成为市场调研和趋势分析的有力工具。
通过观察用户行为和喜好,获取时尚趋势和市场动态的重要信息提高品牌认知度,如何运用这些数据来对我们品牌营销策略做出调整、进而扩大市场成为了至关重要的一点。
那,废话不多说,我们直接进入正题,一起来看看,如何利用快代理来采集某书的数据。
首先,你需要确保安装了 requests 库:
pip install requests如果你安装好了,那我们直接快进到多线程数据采集:
import requests
from concurrent.futures import ThreadPoolExecutor
def fetch_data(url, proxy):
try:
response = requests.get(url, proxies=proxy, timeout=5)
# 检查响应状态码
if response.status_code == 200:
print(f"Successfully fetched data from {url}")
return response.text
else:
print(f"Request to {url} failed with status code: {response.status_code}")
return None
except requests.RequestException as e:
print(f"Request to {url} failed: {e}")
return None
def main():
# 代理IP地址和端口号
proxy = {
'http': 'http://your_proxy_ip:your_proxy_port',
'https': 'http://your_proxy_ip:your_proxy_port',
}
# 要访问的URL列表
urls = ['http://https://www.xiaohongshu.com/explore]
# 使用 ThreadPoolExecutor 创建线程池
with ThreadPoolExecutor(max_workers=5) as executor:
# 将任务提交给线程池
futures = [executor.submit(fetch_data, url, proxy) for url in urls]
# 等待所有任务完成
for future in futures:
data = future.result()
# 处理获取到的数据,例如保存到文件或进行其他处理
if __name__ == "__main__":
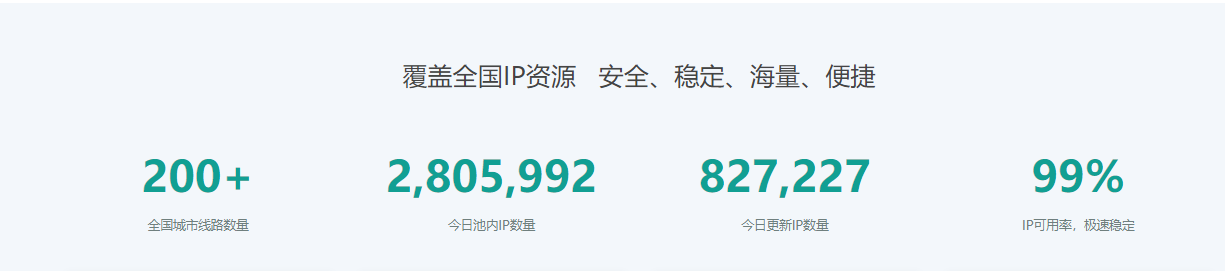
main()值得一提的是,快代理的节点和HTTP代理池子的可用率略微逊色我之前使用的另外一家HTTP代理服务提供商,来看:
这是快代理:

这是青果网络:
可能有的人觉得平平无奇,问题是加上这个呢?

业务成功率高于竞品30%这点,他们家居然能当作宣传用语来说。此前没用他们家之前我也嗤之以鼻,但是用完以后,直接就王境泽定律了。

而且他们家真的把质美价优这点贯彻始终。
没啥好再多夸的,有需要的可以去测试。
接着说回我们的数据采集。
前面我们使用HTTP代理采集了某书,那接下来要做啥子?
我们数据采集后,主要涉及数据的处理、存储以及分析,具体的流程可以根据你的需求和项目的性质来设计。
通常情况下,我们先进行数据清洗,对原始数据进行去重、去异常值或者其他错误数据,以确保我们数据的准确性。清洗后的数据我们可以利用数据分析工具来分析,Pandas、Tableau、BI可视化看板,具体也是根据我们习惯用啥,需求是啥来定,这里不展开叙述了,大家自行实操就好了。
ps:
1.清洗后的数据记得存储,MySQL、PostgreSQL、MongoDB、CSV、JSON大家自己看自己需求。
2.整个过程需要我们建立监控机制,监测我们数据采集的情况,及时发现解决问题。

















 2362
2362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









