






Apache Iceberg 是一种开源的表格格式,专为在数据湖中存储大规模分析数据而设计。它与多种大数据生态系统组件高度兼容,相较于传统的 Hive 表格格式,Iceberg 在设计上提供了更高的性能和更好的可扩展性。它支持 ACID 事务、Schema 演化、数据版本化、隐式分区和跨引擎兼容性等功能,使其特别适合处理数据密集型的大数据分析任务。
然而,Iceberg 的使用也伴随着一些挑战,如较高的上手难度、后台维护需求、性能优化和治理策略等。这些挑战可能增加系统的复杂性并带来性能上的考验,因此用户需要根据自身的业务需求和场景进行仔细的权衡和调整。
在本篇文章中,我们将详细介绍 Iceberg 的架构和特性,深入探讨其优势与面临的挑战。最后,我们将分享几个StarRocks + Iceberg 的解决方案,希望通过用户的真实场景,帮助大家更好地使用 StarRocks 构建湖仓分析新范式。
新时代下 Hive 面临的挑战
Hive 尽管在大数据生态系统中被广泛采用,但它仍旧存在一些设计上的局限性,从而导致在处理大型数据集时存在一些限制:
-
数据更新代价大,实时场景缺失 :Hive 缺少行级更新能力,更新分区内单行数据通常需要重写整个分区,效率低下。
-
ACID 事务缺失,并发场景问题多 :直到 3.0 版本前,Hive 都未能支持 ACID 事务,导致无法处理数据集的并发修改,容易产生数据冲突或不一致。
-
写入缺失原子性 :多分区的 overwrite 操作可能部分成功,导致数据不一致和脏数据问题。
-
Schema 变更开销大 :Schema 变化时(如增删列)通常需重建并重新导入整个表。
-
分区模式变更限制 :Hive 不支持对已有分区 schema 的变更,改变分区策略需要新建表并迁移数据。
-
文件级别元数据缺失 :Hive 表格式仅定义分区级数据组织,不包含具体文件信息,查询这些信息必须通过 file system 去 list 这些目录,代价比较大。
-
不支持推导分区列 :partition column 需要额外定义,不能自动从 data column 推导,增加了数据管理和查询的复杂性。
-
统计信息更新延迟 :统计信息的延迟更新可能导致查询优化器产生次优执行计划,影响查询效率。
-
与 云存储 的 兼容性 差 :使用如 Amazon S3 这样的对象存储服务时,由于 S3 对于列出具有相同前缀的文件有限制,Hive 的分区机制可能遇到性能限制。
Apache Iceberg:新一代数据湖表格式
尽管 Hive 作为早期的数据仓库解决方案发挥了重要作用,但它的性能和灵活性存在一些固有限制,这些限制在实际应用中对数据处理和分析工作构成了挑战。随着数据湖三剑客 Iceberg、Hudi、Delta Lake 为代表的新一代数据湖表格式问世,用户开始从这些限制中解放出来,数据湖的应用也迎来了新一轮的快速发展。
据数据湖领域的权威专家预测,尽管目前 Delta Lake 在市场占有率方面领先,但在未来三年内,Apache Iceberg 有望逐渐超越,成为占据最大市场份额的数据湖格式。这一预测不仅基于 Iceberg 技术上的优势,也反映了业界对其发展潜力的普遍认可。值得注意的是,Snowflake 最近发布的新版本中采用了 Iceberg 的表格式来存储和管理一部分源数据,这进一步证实了 Iceberg 在数据湖领域日益增强的影响力和强劲的发展势头。
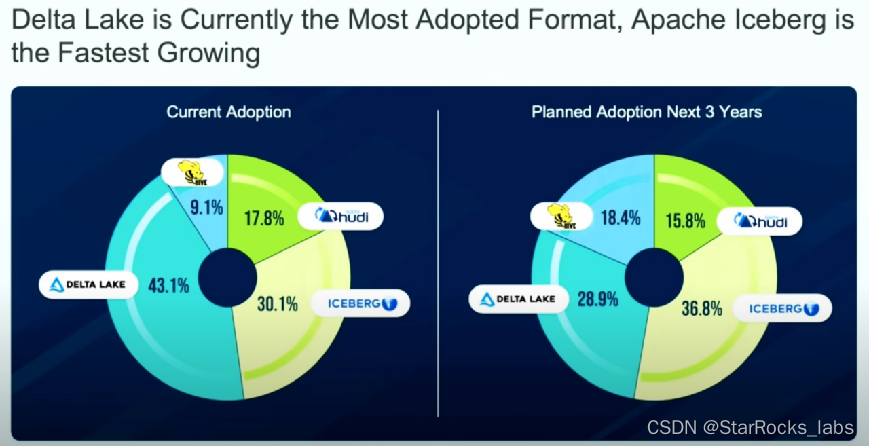
The Latest Data Trends and Predictions for 2024 by Dremio
https://www.youtube.com/watch?v=bULVEsss7y
Iceberg 架构
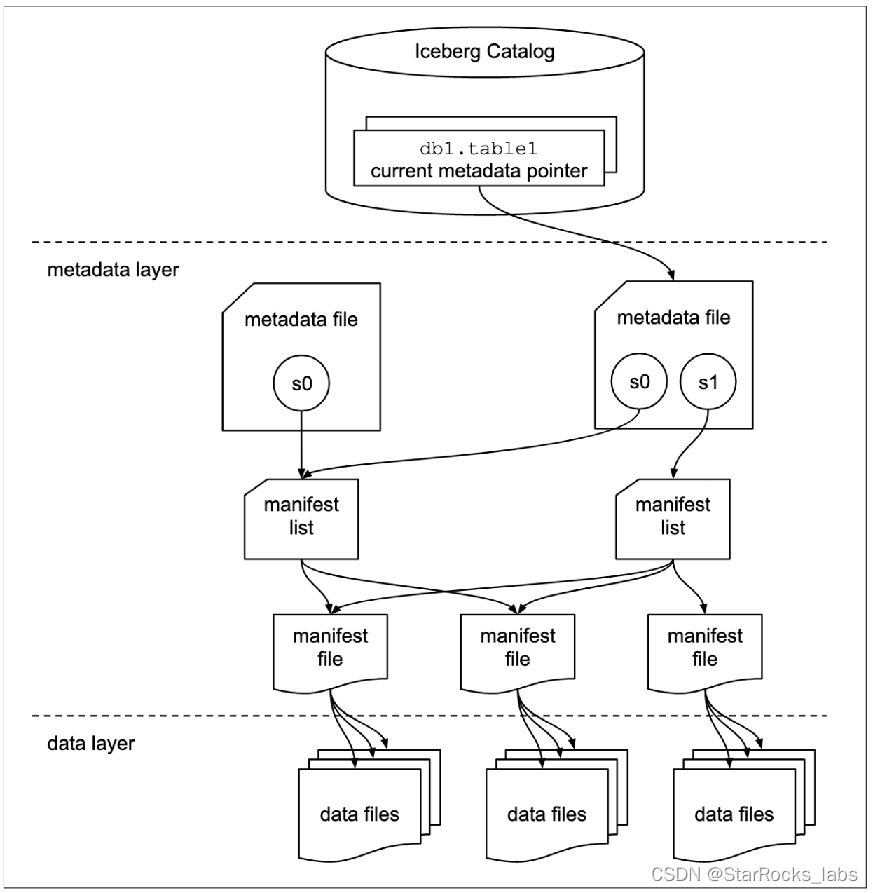
Apache Iceberg 的架构设计分为三个主要层次:
-
数据层(Data Layer) :这一层次包含了实际的数据文件,如 Parquet 和 ORC 格式的文件,它们是存储数据的物理载体。
-
元数据层(Metadata Layer) :Iceberg 的元数据层是多级的,负责存储表的结构和数据文件的索引信息。
-
Catalog 层 :这一层存储了指向元数据文件位置的指针,是元数据的索引。Iceberg 提供了多种 Catalog 实现,例如:
-
HadoopCatalog :直接使用 Hadoop 文件系统目录来管理表信息。
-
HiveCatalog :将表的元数据存储在 Hive Metastore 中,便于与现有的 Hive 生态系统集成。 用户还可以利用 Iceberg 的 API 开发自定义的 Catalog 实现,以便将元数据存储在其他所需位置。
Iceberg 特性
Hidden Partition(隐藏分区)
-
Iceberg 允许用户根据时间戳的不同粒度(如年、月、日或小时)组织数据分区。
-
支持隐藏分区,分区信息对用户透明。
-
使用语法如
CREATE TABLE catalog.MyTable (..., ts TIMESTAMP) PARTITIONED BY days(ts)可实现基于天的时间戳分区,新写入的数据自动归入相应分区。
Schema Evolution(Schema 演化)
-
Iceberg 提供灵活的 Schema 演化功能,支持添加、删除、重命名和更新等 DDL 操作。
-
Schema 变更只更新元数据,无需重写或移动数据文件。每次变更都记录在元数据中,保证历史 Schema 可追踪和查询。
-
使用唯一的 column id 跟踪表中的每一列,保证对文件的读写操作的正确性。
Partition Evolution(分区演化)
-
修改分区策略时,现有数据文件保持原有分区策略,新数据应用新策略。
-
元数据记录所有历史分区 Schema 信息。
-
如数据涉及不同分区策略,Iceberg 可生成不同执行计划处理数据。
MVCC(多版本并发控制)
-
采用 MVCC 机制,确保数据写入不干扰读取操作,每次读取访问最新数据快照。
-
delete 和 overwrite 操作修改 Manifest 文件中 Parquet 文件状态,不直接删除数据文件。
Consistency(数据一致性)
-
支持并发数据写入,使用乐观锁机制处理写入冲突。
-
写入操作基于同一数据快照,如果没有冲突,两个操作都可成功;如果有冲突,只有一个操作成功。
Row-level update: COW & MOR
-
COW(Copy on Write):V1 表格式支持,数据更新时复制原始数据,在副本上应用更改。
-
MOR(Merge on Read):V2 表格式支持,引入位置删除文件和等值删除文件,实现逻辑删除,数据读取时反映最新状态。
-
位置删除记录需要删除的数据行的位置信息,适合数据不频繁变更的场景。
-
等值删除保存要删除数据的值,读取时通过比较执行删除。
-
Iceberg 数据查询的性能挑战
我们可以看出 Iceberg 提供了强大的功能和灵活性,但同时也要求用户投入相应的技术努力来实现最佳的系统管理和性能。
在使用 Apache Iceberg 进行数据查询时,面临的一个主要挑战是高延迟问题。由于 Iceberg 能够记录文件级别的详细信息,扫描整个表以进行数据查询可能需要较长的时间。尤其是在使用如 Amazon S3 这样的对象存储服务时,尽管已经实现了输入文件的缓存机制,但解析操作依然耗时。
解析操作的耗时主要由于 Iceberg 的清单文件(manifest files)通常被高比例压缩。例如,一个典型的 8MB 大小的清单文件,在解压后可能占用高达 300MB 的内存空间。使用 C++ 进行读取时,即使在最佳情况下,解析时间也可能达到 1秒左右。
公开案例表明,在元数据较大(big metadata)场景下,使用 Iceberg 进行数据规划(planner)可能需要长达 50 分钟,而花费十几分钟完成查询是常见的情况。此外,清单文件的内存占用问题不容忽视,尤其是在处理大型数据集时。
在消费清单文件的过程中,尽管 Iceberg 采用了多线程流控制机制,但如果单个查询进行了优化,如实施了特定的缓存策略,可能会降低消费速率,从而对查询性能产生负面影响。如果 Iceberg 处理任务的并发较高,这种影响可能被放大,很容易产生 GC 停顿时间比实际任务执行时间更长。
总的来说,尽管 Iceberg 提供了强大的数据湖功能,但在数据导入和查询性能方面,用户需要采取适当的优化措施,以应对高延迟和资源占用的挑战。
StarRocks,最适合 Iceberg 的查询加速神器
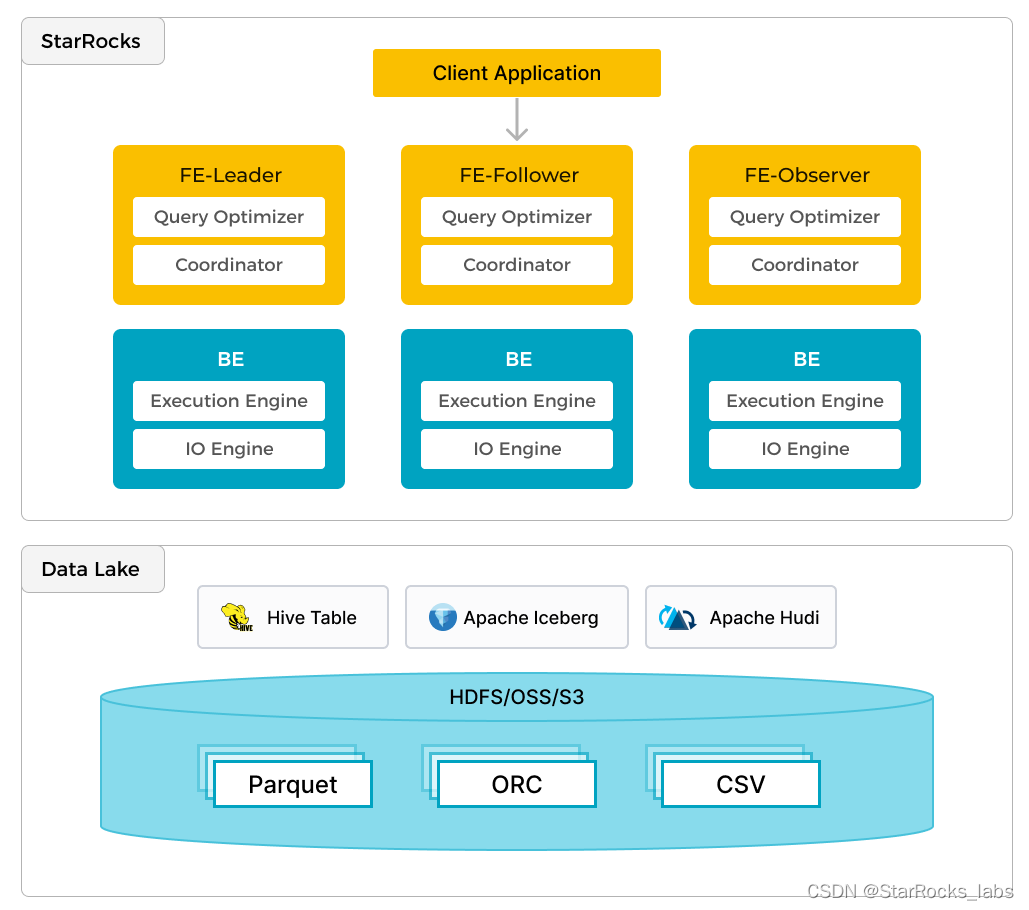
StarRocks 不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据。用户可以通过 StarRocks 提供的 External Catalog,轻松查询存储在 Iceberg 上的数据,无需进行数据迁移。目前,StarRocks已经支持了读取Iceberg v1、v2(包含position delete和equality delete)表,同时也支持向Iceberg表中写入数据。
我们知道一条查询依赖元数据的获取与解析、执行计划的生成与高效的执行。针对查询 Iceberg 的场景,StarRocks不仅可以利用到 StarRocks 原生的向量化引擎、CBO 优化器等能力,StarRocks 也对湖上查询做了很多额外优化。
元数据的获取与解析
对于外部托管的数据,StarRocks 需要从外部拉取元数据并进行解析。这里面有两个性能瓶颈点:拉取(远端文件I/O)和解析(decompress+decode)。
针对元数据拉取,StarRocks 的元数据缓存可以避免重复拉取,造成不必要的 I/O 浪费。
然而如上文所说,在元数据本身就是大数据量的情况下,性能瓶颈已经不在远端 I/O 上,而在解析上了。因为Iceberg Manifest 文件是 Avro 这类行存格式,且解析 Avro 严重依赖 Iceberg Master 节点的 CPU,导致在文件较多的时候造成 Master 节点压力激增,从而大幅度增加 Plan 耗时。而一个 Manifest 文件里可能包含几万个 data file,却只有几个 file 被查询涉及,解析的“性价比”就更低了。一个直观的想法是,能否使用 StarRocks 原生的 MPP 架构来加速这个过程呢?
由此,StarRocks 3.3 版本开始支持了 Iceberg 的分布式 Job Plan,即元数据文件通过 StarRocks 的分布式框架来进行并行读取,并且在每个节点完成 Manifest 的读取与过滤,并统一返回给 FE 来执行后续的流程。这一流程是无状态的,整个流程不仅对用户没有感知,对内的处理流程也更加轻量级,没有任何持久化的维护工作。
此时,另一个直观的想法是,既然解析消耗如此大,那是否可以缓存解析后的 Manifest 呢?由此,从 3.3 版本开始,StarRocks 也支持了反序列化的 Manifest Cache。当有查询命中历史文件时,StarRocks 会直接去从反序列化的Manifest 中获取信息,降低了解析的开销。
这一架构的升级,不仅突破了 Iceberg SDK 的限制,还充分利用到了 StarRocks 的分布式框架与 pipeline 执行引擎,可以在高并发、元数据量大(big metadata)、表文件数量大的情况下突破 Iceberg 的原生限制,提升查询性能,降低对 Iceberg 数据治理与优化的负担。
高效执行计划的生成
CBO 生成一个好的查询规划需要有大量的信息辅助,从而能够针对各类情况(如数据倾斜、关联表的数据情况不同等)生成代价最小的方案。
由此,StarRocks 3.2 版本开始支持了收集外部表(包括 Hive 与 Iceberg)的统计信息,3.3 版本开始支持了直方图统计信息,并且增加了对复杂类型 Struct 子列的统计信息收集。这些信息能够为 StarRocks 生成更高效的执行计划提供重要输入。
针对各类非原生文件格式的优化
数据湖上采用的往往都是主流的开放格式,如 Parquet、ORC、Textfile 等。StarRocks 针对这几类格式进行了持续且细致的优化。一方面尽可能利用外部格式原生的信息优势、降低数据扫描量;另一方面优化策略,尽可能降低远端 I/O 开销。具体优化例如尽可能利用 Parquet、ORC 的 footer 与字典信息加速查询、动态自适应的 I/O 合并等,我们会在后面的文章中详尽解释。
虽然主流的开放格式因其更好的性能与更广泛的兼容性被用户广泛选择,但数据湖场景中经常还是会有一些其他格式的历史文件需要被访问,StarRocks 也通过扩展更通用的 connector 框架来逐步支持,目前已经支持了Avro、SequenceFile 以及 RCFile 的读取。
抹平内外表差异的黑科技
湖仓架构不仅保证了 Single Source of Truth,在架构上更加经济、易扩展。然而湖上查询始终是访问远端存储上的开放格式。相比于查询 StarRocks 内表,一方面 I/O 开销较大,另一方面无法应用 StarRocks 的原生数据格式优化。为了给湖上用户提供如同数仓一般的查询体验,StarRocks 开发了两大杀器:
Data Cache
Data Cache 是一种将热数据缓存至本地的技术。它由查询触发,将查询涉及到的远端数据切分为 block 级别的数据块并拉到本地缓存。如下一次其他查询也命中同样的数据 block,则可以直接从本地读取,无需访问远端存储,降低 I/O 开销。Data Cache 采用内存和磁盘两级缓存,且不会引入数据一致性问题,对终端查询用户没有感知。在全部命中 Cache 的情况下,StarRocks 可以提供类似内表的查询体验。
Data Cache 在很大程度上缓解了远程 I/O 开销,尤其在远端存储(如 HDFS)较为抖动的时候,Data Cache 可以缓解外部环境对查询性能的影响,提供更加稳定的查询表现。
智能物化视图
在计算逻辑较为复杂、性能以及并发要求更高的场景下,StarRocks 的物化视图可以给用户更好的性能保障。
物化视图可以通过预先定义查询的方式,定期将外部数据加工并刷入 StarRocks 内部中,无需用户管理导入pipeline;进入 StarRocks 的物化视图和内表一样,可以享受 StarRocks 内部格式的加速手段,如 Colocate Join、各类 index 等;在查询时,物化视图支持智能的查询改写,这意味着用户无需更改查询,StarRocks 会智能路由至已经物化好的结果上,享受原地性能提升。
目前,基于 Iceberg 的物化视图除了丰富的改写能力以外,已经可以做到感知分区变更,从而进行分区级别的增量刷新,降低刷新开销。
- 更好的生态融合方式
StarRocks 不仅支持了读取Iceberg v1、v2(pos-delete以及eq-delete)格式的表,同时还支持回写Iceberg。从而无论是数据会湖统一,还是对湖上数据进行轻量级的加工,都可以轻松地借助StarRocks完成。
-
数据落湖:在一些对实效性要求较高的场景,实时数据可以先进入StarRocks完成数据的落地与更新,对外提供秒级的数据可见性。一定时间后,可以写回iceberg进行数据资产的统一管理,完成single source of truth。
-
数据加工:配合StarRocks算子落盘与各类资源隔离功能,可以通过StarRocks对iceberg数据进行轻量级加工与回刷。
不仅如此,腾讯游戏的同学也基于 Iceberg 回写的能力在研发降冷功能,能够提供更加透明无感知的降冷以及查询体验。会在未来的版本中发布与介绍。
StarRocks + Iceberg 用户最佳实践
腾讯微信基于 StarRocks + Iceberg 的湖仓一体实践
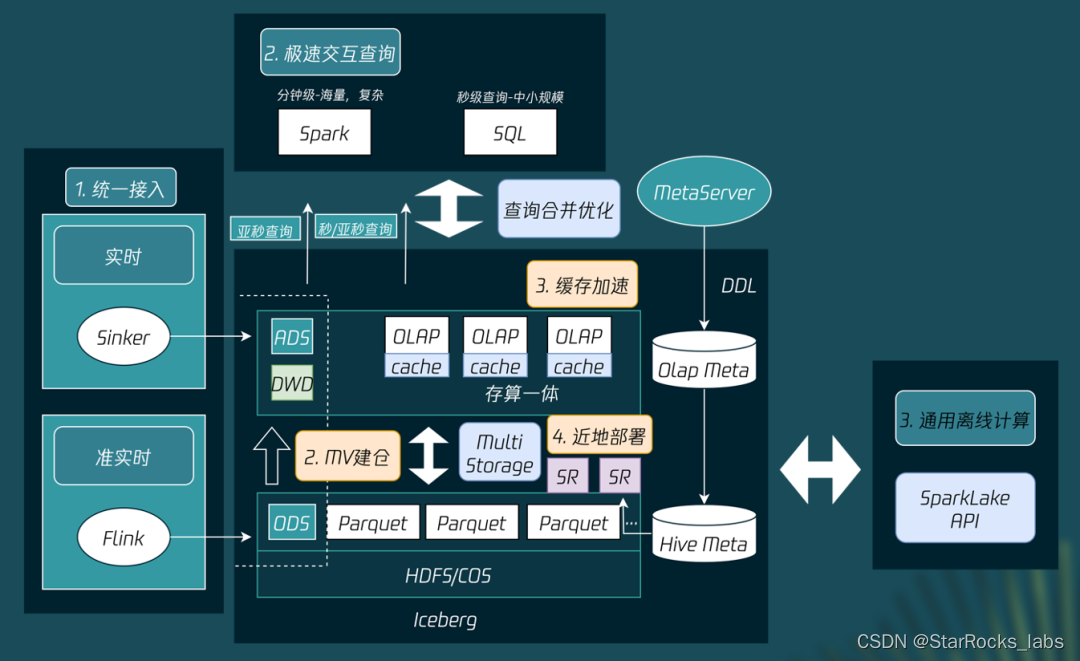
背景与挑战:
微信数据分析面临的挑战包含了海量数据的处理、要求极速的查询响应(TP90 在5秒内),以及需要实现计算和存储的统一
湖仓一体架构探索
湖上建仓
-
从 Presto + Hive 演变为 StarRocks + Iceberg,实现了查询效率和数据时效性的显著提升:
-
数据时效性从小时/天级提升至分钟级。
-
查询效率从分钟级提升至秒级/分钟级。
-
80%的大查询通过 StarRocks 秒级返回,剩余的超大查询通过 Spark 处理。
-
-
未来计划使用 StarRocks 的外表物化视图功能 ,以简化运维和提高效率。
仓湖融合
-
结合数仓和数据湖,通过跨源融合联邦查询的方式实现存储的一体化,无需 ETL 即可直接分析数据湖中的数据。
-
数据实时接入数仓,冷存数据转移到数据湖,通过 Meta Server 实现仓湖元数据的统一管理。
-
结合冷热数据读取和通用离线计算的支持,提升了数据查询响应速度和实时性。
应用成效
-
湖仓一体架构已在微信的多个业务场景中实施,如视频号直播、微信键盘等,集群规模达数百台机器,数据接入量近千亿。
-
在直播业务场景中,数据开发任务数减半,存储成本降低65%以上,离线任务产出时间缩短两小时。
更多交流,联系我们:
https://wx.focussend.com/weComLink/mobileQrCodeLink/33412/8da64


















 158
158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









