









我们一般用xmlfeed模版爬虫去处理RSS订阅信息。RSS是一种信息聚合技术,可以让信息的发布和共享更为高效和便捷。RSS是基于XML标准的。
用xmlfeed爬取新浪博客的订阅信息。
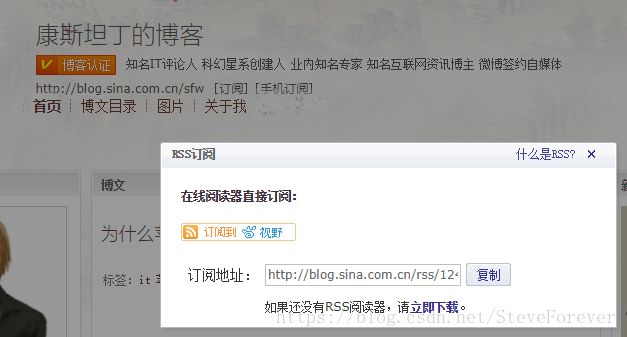
任意选择一个新浪博客,点击订阅出现一个订阅地址:http://blog.sina.com.cn/rss/1246151574.xml
文件是.xml结尾,这就是我们要爬取的xml标准的RSS订阅信息。
一、创建项目并且以xmlfeed模版创建爬虫文件。
#在需要创建项目的目录下,打开命令行,依次运行下面命令
python -m scrapy startproject xmlpjt
cd xmlpjt
python -m scrapy genspider -t xmlfeed steve sina.com.cn二.打开项目,编写文件
1、编写items.py
# -*- coding: utf-8 -*-
import scrapy
class XmlpjtItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
author = scrapy.Field()
2、编写爬虫文件steve.py
# -*- coding: utf-8 -*-
from scrapy.spiders import XMLFeedSpider
from xmlpjt.items import XmlpjtItem
class SteveSpider(XMLFeedSpider):
name = 'steve'
allowed_domains = ['sina.com.cn']
start_urls = ['http://blog.sina.com.cn/rss/1246151574.xml']
iterator = 'iternodes' # you can change this; see the docs
itertag = 'rss' # change it accordingly
def parse_node(self, response, selector):
item = XmlpjtItem()
item["title"] = selector.xpath("/rss/channel/item/title/text()").extract()
item["link"] = selector.xpath("/rss/channel/item/link/text()").extract()
item["author"] = selector.xpath("/rss/channel/item/author/text()").extract()
for i in range(len(item["title"])):
print("第"+str(i+1)+"篇文章")
print("标题是:")
print(item["title"][i])
print("链接为:")
print(item["link"][i])
print("作者是:")
print(item["author"][i])
print("---------------------------------------")
return item
注释:(1)iterator属性:设置使用的迭代器,默认为“iternodes”(一个基于正则表达式的高性能迭代器),除此之外还有“html”和“xml”迭代器;
(2)itertag:设置开始迭代的节点;
(3)parse_node方法:在节点与所提供的标签名相符合时被调用,在其中定义信息提取和处理的操作;
(4)namespaces属性:以列表形式存在,主要定义在文档中会被蜘蛛处理的可用命令空间;
(5)adapt_response(response)方法:在spider分析响应前被调用;
(6)process_results(response, results)方法:在spider返回结果时被调用,主要对结果在返回前进行最后的处理。
3、运行爬虫
#运行爬虫命令
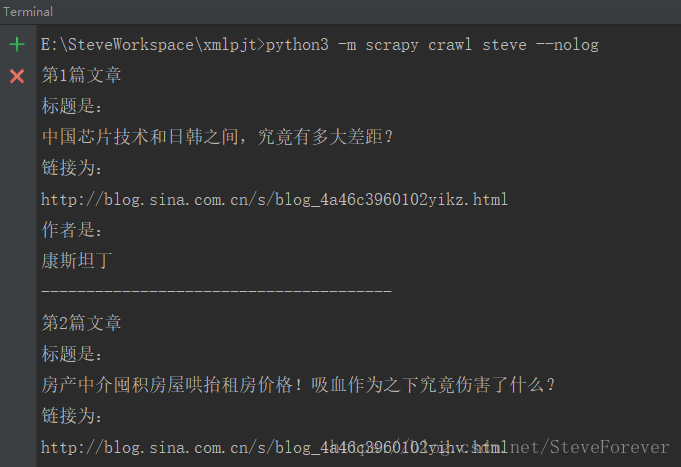
python -m scrapy crawl steve --nolog运行结果:

















 240
240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









