







项目来源:Kaggle: H&M Personalized Fashion Recommendations
基本描述:通过顾客的历史交易记录预测顾客在未来七天内会购买哪些服装产品
项目特点:
1.数据量大:三千万条交易记录,十万种不同商品,137万位顾客
2.预测难度大:需要仅从历史数据出发对个人未来的消费行为进行预测
数据结构:
交易记录:
customer_id(顾客编码) t_dat(交易时间) article_id(商品编码) price(价格) sales_channel_id
一串哈希值,如000058a12d5b43e67d2... 2018-09-20 663713001 0.05 不重要
00007d2de8... 2020-09-22 541518023 0.01
transdata: 31788324行,4列
顾客信息:
customer_id FN(不重要) Active(是否活跃) club_member_status(是不是会员) fashion_news_frequency(时尚新闻频率) age(年龄)
postal_code
一串哈希值,如000058a12d5b43e67d2… Nan/1.0 NaN/1.0 ACTIVE/PRE-CREATE/LEFT CLUB/NaN Monthly/None/NONE/Regularly/NaN 18-100,平均36.8 不重要
customers: 1371980行,6列
商品信息:
article_id(商品编号) prod_name(商品名) section_name(分类名) detail_desc(详细描述)
108775015 Strap top Womens Everyday Basics Jersey top with narrow shoulder straps.
articles: 105542行,24列
articles中描述了商品的:
名称编号(108775)、名称(Strap top),种类名编号(253)、种类名(Vest top),图案编号、图案(solid/strip…),颜色编号、颜色、颜色深度编号、颜色深度
颜色类编号、颜色类(Black),业务部门编号、业务部门(Jersey Basic),索引编号(B)、索引名(Lingeries/Tights)、索引族编号(1)、索引族名(Ladieswear),分类编号(16)、分类名(Womens Everyday Basics),衣着类编号(1017)、衣着类名(Under-, Nightwear)、detail_desc详细描述
对于大部分article_id, 还有一张jpg图片,是这件商品的照片。
这个项目给出前104周的数据,要求预测第105周的顾客消费行为。对137万个顾客中的每个,从十万个商品中选出12个,将12个预测结果按可能性大小从大到小排序作为结果提交。
第一阶段,尝试普通机器学习方法(KNN,KMeans),把相似的商品和相似的顾客聚集起来。对相似的顾客,推荐给他们跟相似的人买的商品。然而,该方法不足以应对问题的复杂性,效果差。
第二阶段,采用DIEN(Deep Interest Evolution Network),结合BERT模型进行语义分析。DIEN的原理是捕捉用户的注意力转移,比如一个顾客某段时间热衷于电子产品,但后来又热衷于健身,DIEN就可以捕捉这一变化。该方法下我们的得分是0.009(第一名0.037)。
DIEN的问题是:
数据量过大:由于保留了2年的序列数据,分析序列数据需要大量计算,准备训练数据就需要24小时。
效果一般:在实际生活中用户的兴趣变化往往具有较大的随机性。
经过测试,客户在许久之前的购买行为实际上和他未来的购买行为没有太大的相关性,在之后的研究中,我们舍弃序列数据,换取更快的训练速度。
在第一阶段中,我们是通过分析商品与商品之间的相似性,或者是客户和客户之间的相似性,来进行预测,在使用KNN、KMeans操作后,发现效果差。
在第三阶段中,我们转而运用协同过滤(CF,Collaborative Filtering)的方式,通过分析客户对商品的选择性购买来确定商品之间的相似性。在本项目中,使用点击共现的方式实现协同过滤的思想,分析在指定时间段中哪些商品经常被一个人同时购买。
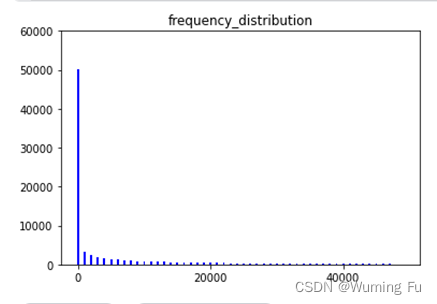
经过数据分析后,顾客的购买行为具有长尾分布的特征。有一些商品是经常被经常被购买的,而其他许多商品往往常年几乎无人问津。故而,我们希望关注用户选择的协同过滤方法将会超越仅仅考虑商品、用户之间相似性的聚类方法。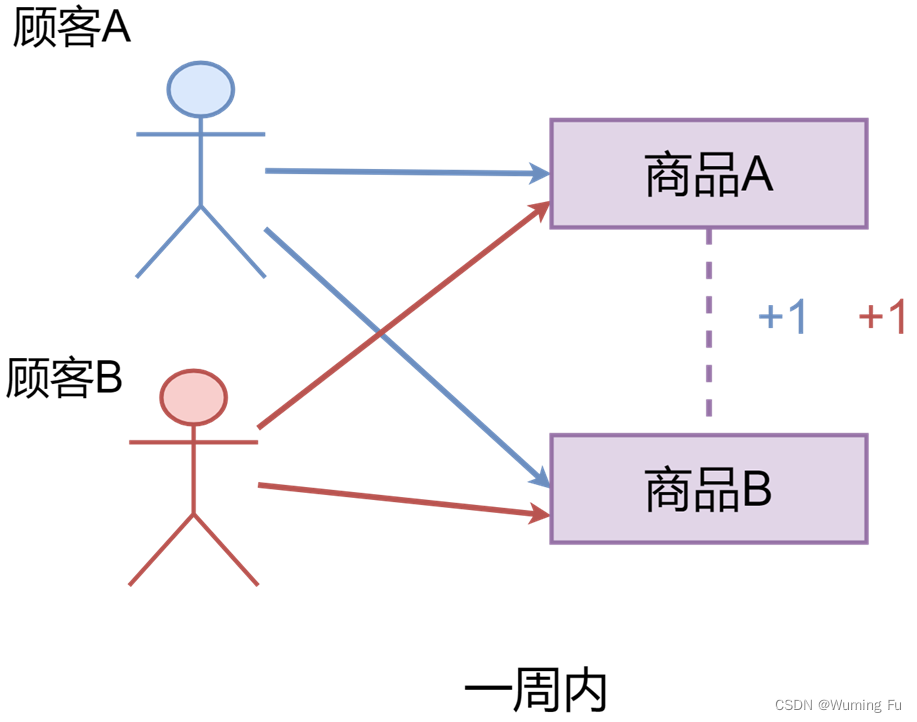
点击共现
所谓点击共现,就是在一周内,如果顾客A同时购买了商品A和商品B,那么商品A和商品B之间的联系权重就+1。如果顾客B也同时购买了商品A和商品B,那么商品A和商品B之间的联系权重就再加1。
对于每个商品,找出与之关联度最强的5个商品。当客户最近购买了某件商品时,我们将预测他马上会购买与该商品有强关联度的商品。
利用前104周的数据进行训练,试图预测第105周的结果。为了训练的高效性与时效性,只从95-104周的数据做召回。要为第96周的购买行为进行预测,需要通过第95周的数据进行预测。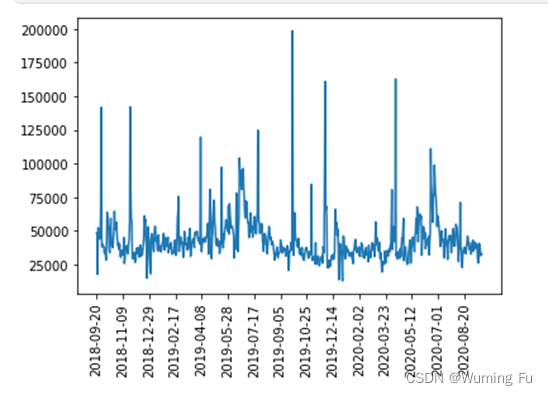
顾客消费的聚集性
不论是做预测还是点击共现,我们都强调分析”一周内“的数据。因为从上图可见,顾客的消费在时间上分布并不均匀。比如有些超级高的尖尖,很可能是在黑色星期五大采购。圣诞节时流行的服饰,几周后会迅速失去热度。故而,我们强调数据的时效性。
点击共现:效果
上图可见,当顾客购买褐色裤子,模型可以预测出她很可能会再买一件配套的大衣。而如果顾客购买了发圈这种小东西,那她也倾向于再购买像小袜子之类的小玩意。
由于舍弃了序列数据,我们不再使用DIEN模型,而是用DIN(Deep Interest Network)模型。普通推荐模型是把特征拿过来做一个SUM Pooling然后过ReLU层。而DIN在此基础上引入注意力机制。总之普通的推荐模型在判断一个人会不会买“女装大衣”时对ta买过“袜子”和“女裤”的信息一视同仁。而DIN会更加关注“女裤”的信息。
Private Score Public Score
DIEN 0.009 0.009
CF*1 0.006 0.007
CF*5+DIN 0.017 0.017
最终结果
CF即Collarative Filetering,协同过滤。最终用CF五个商品+DIN模型的方法,得分0.017(第一名0.037)。
最后做一个总结:
机器学习效果不佳->采用更复杂的深度学习模型
普通聚类不适合->采用协同过滤方法
提供的数据(特征表格、描述语句、商品图片)量大而杂:优先处理关键信息(用户的选择偏好)
经过实验后舍弃序列数据,选用DIN模型,聚焦关键信息,节约算力。
根据购买行为具有时效聚集性的特点,在模型中重视时效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









