









目录
内存管理
Flink是由Java语言所开发的,而基于JVM的数据分析引擎都需要面对将大量的数据存到内存当中,JVM存在以下几个问题:
- Java对象存储密度低。因为Java对象需要存储许多其他信息,比如一个boolean对象就占用了16个字节内存,其中包括了对象头占8个字节,boolean占一个字节,对齐填充占了7个。相当于浪费了15个字节。
- Full GC会极大地影响性能,尤其是为了处理更大数据而开了很大内存空间的JVM,GC有可能会达到秒级甚至是分钟级。
- OOM问题影响稳定性。OOM是分布式计算框架经常遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OOM错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
所以,目前越来越多的大数据项目开始自己管理JVM内存了,为的就是获得像C一样的性能以及避免OOM的发生,不过要注意内存的释放问题。Flink为了解决上面的问题,主要是在内存管理、定制的序列化工具、缓存友好的数据结构和算法、堆外内存、JIT编译优化等进行处理。
积极的内存管理
Flink并不是将大量的对象存在堆上,而是将对象都序列化到一个预分配的内存块上,这个内存块叫做MemorySegment(在反压机制那里提到过),代表了一段固定长度的内存(默认是32KB),也是Flink中最小的内存分配单元,并且提供了非常高效的读写方法。你可以把MemorySegment想象成是为Flink定制的java.nio.ByteBuffer。底层可以是一个普通的Java字节数组(byte[]),也可以是一个申请在堆外的ByteBuffer。每条记录都会以序列化的形式存储在一个或多个MemorySegment中。
Flink在TaskManager运行用户代码的JVM进程。TM的堆内存主要被分成了三个部分。

- Network Buffers:一定数量的MemorySegment,主要用于网络传输。在TaskManager启动时分配,通过NetworkEnvironment和NetworkBufferPool进行管理。
- Managed Memory:由MemoryManager管理的一组MemorySegment集合,主要用于Batch模式下的sorting,hashing和cache等。
- Remaining JVM heap:余下的堆内存留给TaskManager的数据结构以及用户代码处理数据时使用。TaskManager自身的数据结构并不会占用太多内存,因而主要都是供用户代码使用,用户代码创建的对象通常生命周期都较短
注意,上面所说的三部分的内存并非都是JVM堆上的内存。对于Network Buffers,这一部分内存就是在堆外(off-heap)进行分配的;对于Memory Manager,这一部分内存可以配置在堆上,也可以配置在堆外。另外还需要注意的一点是,Memory Manager主要是在Batch模式下使用,而在Streaming模式下则是给用户自定义函数使用。
MemorySegment堆内内存与堆外内存的比较
MemorySegment在早期版本当中使用的都是堆内内存,后续由于堆内内存以下几个方面,加入了堆外内存:
- 启动很大堆内存(100s of GBytes heap memory)的JVM需要很长时间,GC停留时间也会很长(秒级甚至是分钟级)。使用堆外内存的话,JVM只需要分配较少的堆内存。
- 堆外内存在写磁盘或者网络传输时可以利用零拷贝技术,I/O和网络传输的效率更高。
- 堆外内存是进程间共享的,也就是说,即使JVM进程崩溃也不会丢失数据。这可以用来故障恢复。Flink暂时还没有利用这个特性。
但是,堆外内存也可能存在一些问题:
- 堆内存可以很方便地进行监控和分析,相较而言堆外内存则更加难以控制;
- Flink有时可能需要短生命周期的MemorySegment,在堆上申请开销会更小;
- 一些操作在堆内存上会更快。
所以,Flink将原来的MemorySegment变成了抽象类,并提供两个具体的子类:HeapMemorySegment和HybridMemorySegment。前者是用于分配堆内存,后者用来分配堆外内存和堆内存的。

序列化方法
Flink采用类似DBMS的sort和join算法,直接操作二进制数据,从而使序列化/反序列化带来的开销达到最小。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。这样处理的好处是:
- 减少GC压力。显而易见,因为所有常驻型数据都以二进制的形式存在Flink的MemorySegment中,一直呆在老年代不会被GC回收。其他的数据对象基本上是由用户代码生成的短生命周期对象,这部分对象可以被Minor GC快速回收。只要用户不去创建大量类似缓存的常驻型对象,那么老年代的大小是不会变的,Major GC也就永远不会发生。从而有效地降低了垃圾回收的压力。另外,这里的内存块还可以是堆外内存,可以使得JVM内存更小,从而加速垃圾回收。
- 避免了OOM。所有的运行时数据结构和算法只能通过内存池申请内存,保证了其使用的内存大小是固定的,不会因为运行时数据结构和算法而发生OOM。在内存吃紧的情况下,算法(sort/join等)会高效地将一大批内存块写到磁盘,之后再读回来(相当于spark的落盘)。
- 节省内存空间。Java对象在存储上很多额外的消耗,如果只存储实际数据的二进制内容,就可以避免这部分消耗。
- 高效的二进制操作 & 缓存友好的计算。二进制数据以定义好的格式存储,可以高效地比较与操作。另外,该二进制形式可以把相关的值,以及hash值,键值和指针等相邻地放进内存中,使得数据结构可以高速缓存更友好,可以从L1/L2/L3缓存获得性能的提升。
Flink序列化数据类型
现在 Java 生态圈中已经有许多序列化框架,比如说 Java serialization, Kryo, Apache Avro 等等。但是 Flink 依然是选择了自己定制的序列化框架,那么到底有什么意义呢?若 Flink 选择自己定制的序列化框架,对类型信息了解越多,可以在早期完成类型检查,更好的选取序列化方式,进行数据布局,节省数据的存储空间,直接操作二进制数据。
Flink的数据类型如图所示,可以分为基础类型(Basic)、数组(Arrays)、复合类型(Composite)、辅助类型(Auxiliary)、泛型和其它类型(Generic)。Flink 支持任意的 Java 或是 Scala 类型。不需要像 Hadoop 一样去实现一个特定的接口(org.apache.hadoop.io.Writable),Flink 能够自动识别数据类型。并且每一个具体的类型都对应了一个具体的TypeInformation实现类。
TypeInformation 是 Flink 类型系统的核心类。对于用户自定义的 Function 来说,Flink 需要一个类型信息来作为该函数的输入输出类型,即 TypeInfomation。该类型信息类作为一个工具来生成对应类型的序列化器 TypeSerializer,并用于执行语义检查。
每一个具体的数据类型都对应一个 TypeInformation 的具体实现,每一个 TypeInformation 都会为对应的具体数据类型提供一个专属的序列化器。通过 Flink 的序列化过程图可以看到TypeInformation 会提供一个 createSerialize() 方法,通过这个方法就可以得到该类型进行数据序列化操作与反序化操作的对象 TypeSerializer。
Flink排序算法底层原理
在分布式计算框架中,排序是重中之重。做为流批一体化的处理框架Flink,在流式处理的时候不需要进行排序操作(毕竟数据是一条一条过来的,没必要排序…),所以sort Buffer会被用来做为useBuffer。而在批处理中,由于Flink的处理二进制数据,其中数据大小不一致导致如果直接进行排序,移动会相对复杂,不能直接进行两两交换。
所以我们会把sort Buffer分为两块不同的MemorySegment,采用指针的思想,一块区域存放所有对象的完整二进制数据,另一个区域存放指向数据的指针以及定长的key,换句话说就是这块区域用来存(key+point)。如果数据对象是变长类型,则会取其前缀序列化。
划分为两块区域的好处在于,第一,存放指针的那块区域属于定长块,每个对象都是固定长度,所以排序进行交换时更加高效方便,问题在于数据之间进行比较的时候需要根据指针进行发序列化比较,这样很影响效率。所以存储指针的同时还存储了key,也可以理解为数据的前缀部分,直接上图可能清楚点。第二,分开存储是对于缓存友好的,因为key是可以连续存储在内存中,大大提高了缓存的命中率。
总结起来就:
- 通过Key和Full data分离存储的方式尽量将被操作的数据最小化,提高Cache命中的概率,从而提高CPU的吞吐量。
- 移动数据时,只需移动Key+Pointer,而无须移动数据本身,大大减少了内存拷贝的数据量。
- TypeComparator直接基于二进制数据进行操作,节省了反序列化的时间。
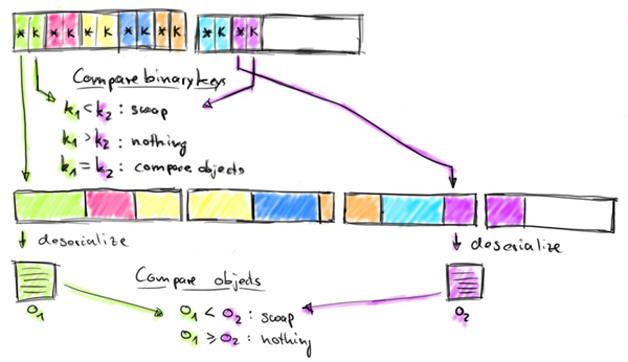
根据上图,举个简单的例子,描述一下排序的大概流程与方法。
假设将100,101,200,1100,2000,23,14进行排序,key设定为前两位数字+数字的位数,那么进行排序的时候则是按照先比较key中的数字位数,两位数排前面,四位数排后面,如果位数相同,那么就比较前缀的大小,10比20小,以此类推。最后都比较不了的情况下,才会根据指针去反序列化得到原始数据,进行比较。
因为有了key的存在,所以很容易命中缓存,有效的减少了大量的反序列化操作,并且L1/L2/L3缓存得到了性能的提升。并且定长的原因,交换逻辑位置也是更方便,可以进行两两交换。
参考
【海牛大数据】大数据2021最新java版Flink教程-青牛老师倾力打造_哔哩哔哩_bilibili















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









