




 本文介绍了一种基于级联回归卷积神经网络的人脸关键点检测方法,通过多阶段训练提高定位准确性。
本文介绍了一种基于级联回归卷积神经网络的人脸关键点检测方法,通过多阶段训练提高定位准确性。
一:目标
人脸关键点检测是在人脸检测的基础上,对人脸上的特征点例如眼睛、鼻子、嘴巴等进行定位。本例是使用caffe框架实现的结果,效果如下:
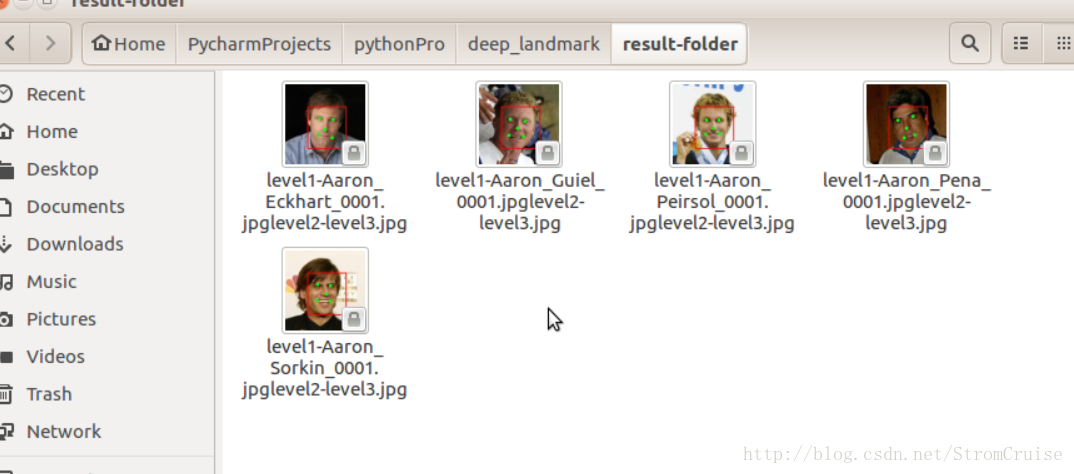
二:数据源的制作
因为lmdb不支持多标签,所以这里使用的是hdf5格式,支持多标签。
卷积神经网络可以用于分类和回归任务,做分类任务时最后一个全连接层的输出维度为类别数,接着Softmax层采用Softmax Loss计算损失函数,而如果做回归任务,最后一个全连接层的输出维度则是要回归的坐标值的个数,采用的是欧几里何损失Euclidean Loss。
训练卷积神经网络来回归特征点坐标。如果只采用一个网络来做回归训练的话,会发现得到的特征点坐标不够准确,采用级联回归CNN的方法,进行分段式特征点定位,可以更快速、准确的定位人脸特征点。如果采用更大的网络,特征点的预测会更加准确,但耗时会增加;为了在速度和性能上找到一个平衡点,使用较小的网络,所以使用级联的思想,先进行粗检测,然后微调特征点。具体思路如下图:
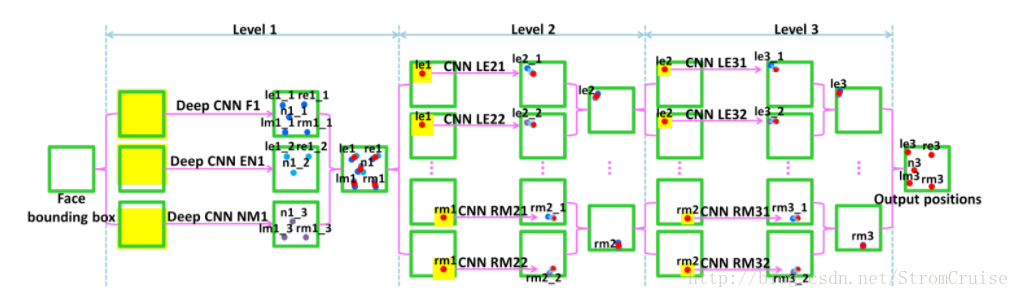
1、 首先在整个人脸图像(红色方框)上训练一个网络来对人脸特征点坐标进行粗回归,实际采用的网络其输入大小为39*39的人脸区域灰度图,预测时可以得到特征点的大概位置,第一层分为三波,分别是对五个点、左右眼和鼻子、鼻子和嘴巴。
2、 设计另一个回归网络,以人脸特征点(取得是level1训练之后得到的特征点)周围的局部区域图像(level2和level3中的黄色区域)作为输入进行训练,实际采用的网络为其输入大小为15*15的特征点局部区域灰度图,以预测到更加准确的特征点位置。这里level3比level2定义的输入区域要小一点。

如上图3所示为的卷积网络结构,level1网络的输入层使用的是39*39的单通道灰色图像,经过四个带池化层的卷积层,最后经过全连接层,输出一个维度为10的结果,代表5个特征点的坐标值,在最后一层是欧几里得损失层,计算的是网络预测的坐标值与真实值(都是相对值)之间的均值误差的积累。网络结构文件见1_F_train.prototxt。
solver超参数文件见1_F_solver.prototxt,选用的是CPU模式(如果有GPU资源,选用GPU即可):
第一层训练完成之后,得到预测结果,这是已经得到预测的特征点位置,但可能不够精确,接下来进入第二、三层训练,得到更加精确的结构。第一层使用的是一个较深一点的网络,估计关键点的位置;第二、三层共享一个较浅一点的网络,实现高精度。
第二层训练,以第一层训练得到的5个特征点为基础,每个特征点做两组数据集,即以第一组数据集特征点为中心,局部框大小为(2*0.18*W,2*0.18*H),其中W和H为人脸框的宽和高,并对此局部框做随机的微小平移使得特征点在局部框中的位置随机,裁剪出一个大小为15*15的局部框图像,第二组数据和第一组数据一样,只是框比例取0.16(第三层的两组数据比例为0.11、0.12,其余和第二层一样)。对每个特征点,针对这两组数据集采用同样的网络,得到两组模型;预测时,采用两组模型预测的均值作为预测结果,提高预测的准确度。第二层网络代码见level2.py
第二层网路配置见2_LE1_solver.prototxt。
第二层超参数配置见2_LE1_solver.prototxt
第三层网络代码见leve3.py
第三层网路配置见3_LE1_train.prototxt
第三层超参数配置见3_LE1_solver.prototxt
执行leve1.py 生成第一阶段需要的hdf5数据源
level1.py
#!/usr/bin/env python2.7
# coding: utf-8
import os
import time
import math
from os.path import join, exists
import cv2
import numpy as np
import h5py
from utils_common import shuffle_in_unison_scary, logger, createDir, processImage
from utils_common import getDataFromTxt
from utils import show_landmark,flip,rotate
TRAIN = '/home/tom/PycharmProjects/pythonPro/deep_landmark/cnn-face-data'
OUTPUT = '/home/tom/PycharmProjects/pythonPro/deep_landmark/dataset1/train'
if not exists(OUTPUT):
os.mkdir(OUTPUT)
assert(exists(TRAIN) and exists(OUTPUT))
def generate_hdf5(ftxt, output, fname, argument=False):
data = getDataFromTxt(ftxt)
F_imgs = []
F_landmarks = []
EN_imgs = []
EN_landmarks = []
NM_imgs = []
NM_landmarks = []
for (imgPath, bbox, landmarkGt) in data:
img = cv2.imread(imgPath, cv2.CV_LOAD_IMAGE_GRAYSCALE)
assert(img is not None)
logger("process %s" % imgPath)
# F
f_bbox = bbox.subBBox(-0.05, 1.05, -0.05, 1.05)
f_face = img[int(round(f_bbox.top)):int(round(f_bbox.bottom+1)),int(round(f_bbox.left)):int(round(f_bbox.right+1))]
## data argument
if argument and np.random.rand() > -1:
### flip
face_flipped, landmark_flipped = flip(f_face, landmarkGt)
face_flipped = cv2.resize(face_flipped, (39, 39))
F_imgs.append(face_flipped.reshape((1, 39, 39)))
F_landmarks.append(landmark_flipped.reshape(10))
### rotation
"""
if np.random.rand() > 0.5:
face_rotated_by_alpha, landmark_rotated = rotate(img, f_bbox, \
bbox.reprojectLandmark(landmarkGt), 5)
landmark_rotated = bbox.projectLandmark(landmark_rotated)
face_rotated_by_alpha = cv2.resize(face_rotated_by_alpha, (39, 39))
F_imgs.append(face_rotated_by_alpha.reshape((1, 39, 39)))
F_landmarks.append(landmark_rotated.reshape(10))
### flip with rotation
face_flipped, landmark_flipped = flip(face_rotated_by_alpha, landmark_rotated)
face_flipped = cv2.resize(face_flipped, (39, 39))
F_imgs.append(face_flipped.reshape((1, 39, 39)))
F_landmarks.append(landmark_flipped.reshape(10))
### rotation
if np.random.rand() > 0.5:
face_rotated_by_alpha, landmark_rotated = rotate(img, f_bbox, \
bbox.reprojectLandmark(landmarkGt), -5)
landmark_rotated = bbox.projectLandmark(landmark_rotated)
face_rotated_by_alpha = cv2.resize(face_rotated_by_alpha, (39, 39))
F_imgs.append(face_rotated_by_alpha.reshape((1, 39, 39)))
F_landmarks.append(landmark_rotated.reshape(10))
### flip with rotation
face_flipped, landmark_flipped = flip(face_rotated_by_alpha, landmark_rotated)
face_flipped = cv2.resize(face_flipped, (39, 39))
F_imgs.append(face_flipped.reshape((1, 39, 39)))
F_landmarks.append(landmark_flipped.reshape(10))
"""
f_face = cv2.resize(f_face, (39, 39))
en_face = f_face[:31, :]
nm_face = f_face[8:, :]
f_face = f_face.reshape((1, 39, 39))
f_landmark = landmarkGt.reshape((10))
F_imgs.append(f_face)
F_landmarks.append(f_landmark)
# EN
# en_bbox = bbox.subBBox(-0.05, 1.05, -0.04, 0.84)
# en_face = img[en_bbox.top:en_bbox.bottom+1,en_bbox.left:en_bbox.right+1]
## data argument
if argument and np.random.rand() > 0.5:
### flip
face_flipped, landmark_flipped = flip(en_face, landmarkGt)
face_flipped = cv2.resize(face_flipped, (31, 39)).reshape((1, 31, 39))
landmark_flipped = landmark_flipped[:3, :].reshape((6))
EN_imgs.append(face_flipped)
EN_landmarks.append(landmark_flipped)
en_face = cv2.resize(en_face, (31, 39)).reshape((1, 31, 39))
en_landmark = landmarkGt[:3, :].reshape((6))
EN_imgs.append(en_face)
EN_landmarks.append(en_landmark)
# NM
# nm_bbox = bbox.subBBox(-0.05, 1.05, 0.18, 1.05)
# nm_face = img[nm_bbox.top:nm_bbox.bottom+1,nm_bbox.left:nm_bbox.right+1]
## data argument
if argument and np.random.rand() > 0.5:
### flip
face_flipped, landmark_flipped = flip(nm_face, landmarkGt)
face_flipped = cv2.resize(face_flipped, (31, 39)).reshape((1, 31, 39))
landmark_flipped = landmark_flipped[2:, :].reshape((6))
NM_imgs.append(face_flipped)
NM_landmarks.append(landmark_flipped)
nm_face = cv2.resize(nm_face, (31, 39)).reshape((1, 31, 39))
nm_landmark = landmarkGt[2:, :].reshape((6))
NM_imgs.append(nm_face)
NM_landmarks.append(nm_landmark)
#imgs, landmarks = process_images(ftxt, output)
F_imgs, F_landmarks = np.asarray(F_imgs), np.asarray(F_landmarks)
EN_imgs, EN_landmarks = np.asarray(EN_imgs), np.asarray(EN_landmarks)
NM_imgs, NM_landmarks = np.asarray(NM_imgs),np.asarray(NM_landmarks)
F_imgs = processImage(F_imgs)
shuffle_in_unison_scary(F_imgs, F_landmarks)
EN_imgs = processImage(EN_imgs)
shuffle_in_unison_scary(EN_imgs, EN_landmarks)
NM_imgs = processImage(NM_imgs)
shuffle_in_unison_scary(NM_imgs, NM_landmarks)
# full face
base = join(OUTPUT, '1_F')
createDir(base)
output = join(base, fname)
logger("generate %s" % output)
with h5py.File(output, 'w') as h5:
h5['data'] = F_imgs.astype(np.float32)
h5['landmark'] = F_landmarks.astype(np.float32)
# eye and nose
base = join(OUTPUT, '1_EN')
createDir(base)
output = join(base, fname)
logger("generate %s" % output)
with h5py.File(output, 'w') as h5:
h5['data'] = EN_imgs.astype(np.float32)
h5['landmark'] = EN_landmarks.astype(np.float32)
# nose and mouth
base = join(OUTPUT, '1_NM')
createDir(base)
output = join(base, fname)
logger("generate %s" % output)
with h5py.File(output, 'w') as h5:
h5['data'] = NM_imgs.astype(np.float32)
h5['landmark'] = NM_landmarks.astype(np.float32)
if __name__ == '__main__':
# train data
h5_path = '/home/tom/PycharmProjects/pythonPro/deep_landmark/dataset1/'
train_txt = join(TRAIN, 'trainImageList.txt')
generate_hdf5(train_txt, OUTPUT, 'train.h5', argument=True)
test_txt = join(TRAIN, 'testImageList.txt')
generate_hdf5(test_txt, OUTPUT, 'test.h5')
with open(join(OUTPUT, '1_F/train.txt'), 'w') as fd:
fd.write(h5_path+'train/1_F/train.h5')
with open(join(OUTPUT, '1_EN/train.txt'), 'w') as fd:
fd.write(h5_path+'train/1_EN/train.h5')
with open(join(OUTPUT, '1_NM/train.txt'), 'w') as fd:
fd.write(h5_path+'train/1_NM/train.h5')
with open(join(OUTPUT, '1_F/test.txt'), 'w') as fd:
fd.write(h5_path+'train/1_F/test.h5')
with open(join(OUTPUT, '1_EN/test.txt'), 'w') as fd:
fd.write(h5_path+'train/1_EN/test.h5')
with open(join(OUTPUT, '1_NM/test.txt'), 'w') as fd:
fd.write(h5_path+'train/1_NM/test.h5')
# Doneutils.py
# coding: utf-8
"""
functions
"""
import os
import cv2
import numpy as np
def show_landmark(face, landmark):
"""
view face with landmark for visualization
"""
face_copied = face.copy().astype(np.uint8)
for (x, y) in landmark:
xx = int(face.shape[0]*x)
yy = int(face.shape[1]*y)
cv2.circle(face_copied, (xx, yy), 2, (0,0,0), -1)
cv2.imshow("face_rot", face_copied)
cv2.waitKey(0)
def rotate(img, bbox, landmark, alpha):
"""
given a face with bbox and landmark, rotate with alpha
and return rotated face with bbox, landmark (absolute position)
"""
center = ((bbox.left+bbox.right)/2, (bbox.top+bbox.bottom)/2)
rot_mat = cv2.getRotationMatrix2D(center, alpha, 1)
img_rotated_by_alpha = cv2.warpAffine(img, rot_mat, img.shape)
landmark_ = np.asarray([(rot_mat[0][0]*x+rot_mat[0][1]*y+rot_mat[0][2],
rot_mat[1][0]*x+rot_mat[1][1]*y+rot_mat[1][2]) for (x, y) in landmark])
face = img_rotated_by_alpha[bbox.top:bbox.bottom+1,bbox.left:bbox.right+1]
return (face, landmark_)
def flip(face, landmark):
"""
flip the face and
exchange the eyes and mouths point
face_flipped_by_x = output array of the same size and type as src
landmark_ = changed landmark point
"""
face_flipped_by_x = cv2.flip(face, 1)
landmark_ = np.asarray([(1-x, y) for (x, y) in landmark])
landmark_[[0, 1]] = landmark_[[1, 0]]
landmark_[[3, 4]] = landmark_[[4, 3]]
return (face_flipped_by_x, landmark_)
def randomShift(landmarkGt, shift):
"""
Random Shift one time
"""
diff = np.random.rand(5, 2)
diff = (2*diff - 1) * shift
landmarkP = landmarkGt + diff
return landmarkP
def randomShiftWithArgument(landmarkGt, shift):
"""
Random Shift more
"""
N = 2
landmarkPs = np.zeros((N, 5, 2))
for i in range(N):
landmarkPs[i] = randomShift(landmarkGt, shift)
return landmarkPsutils_common.py
# coding: utf-8
import os
from os.path import join, exists
import time
import cv2
import numpy as np
from cnns import getCNNs
def logger(msg):
"""
log message
"""
now = time.ctime()
print("[%s] %s" % (now, msg))
def createDir(p):
if not os.path.exists(p):
os.mkdir(p)
def shuffle_in_unison_scary(a, b):
rng_state = np.random.get_state()
np.random.shuffle(a)
np.random.set_state(rng_state)
np.random.shuffle(b)
def drawLandmark(img, bbox, landmark):
cv2.rectangle(img, (bbox.left, bbox.top), (bbox.right, bbox.bottom), (0,0,255), 2)
for x, y in landmark:
cv2.circle(img, (int(x), int(y)), 2, (0,255,0), -1)
return img
def getDataFromTxt(txt, with_landmark=True):
"""
Generate data from txt file
return [(img_path, bbox, landmark)]
bbox: [left, right, top, bottom]
landmark: [(x1, y1), (x2, y2), ...]
"""
dirname = os.path.dirname(txt)
with open(txt, 'r') as fd:
lines = fd.readlines()
result = []
for line in lines:
line = line.strip()
components = line.split(' ')
img_path = os.path.join(dirname, components[0].replace('\\', '/')) # file path
# bounding box, (left, right, top, bottom)
bbox = (components[1], components[2], components[3], components[4])
bbox = [int(_) for _ in bbox]
# landmark
if not with_landmark:
result.append((img_path, BBox(bbox)))
continue
landmark = np.zeros((5, 2))
for index in range(0, 5):
rv = (float(components[5+2*index]), float(components[5+2*index+1]))
landmark[index] = rv
for index, one in enumerate(landmark):
rv = ((one[0]-bbox[0])/(bbox[1]-bbox[0]), (one[1]-bbox[2])/(bbox[3]-bbox[2]))
landmark[index] = rv
result.append((img_path, BBox(bbox), landmark))
return result
def getPatch(img, bbox, point, padding):
"""
Get a patch iamge around the given point in bbox with padding
point: relative_point in [0, 1] in bbox
"""
point_x = bbox.x + point[0] * bbox.w
point_y = bbox.y + point[1] * bbox.h
patch_left = point_x - bbox.w * padding
patch_right = point_x + bbox.w * padding
patch_top = point_y - bbox.h * padding
patch_bottom = point_y + bbox.h * padding
patch = img[int(round(patch_top)): int(round(patch_bottom+1)), int(round(patch_left)): int(round(patch_right+1))]
patch_bbox = BBox([patch_left, patch_right, patch_top, patch_bottom])
return patch, patch_bbox
def processImage(imgs):
"""
process images before feeding to CNNs
imgs: N x 1 x W x H
"""
imgs = imgs.astype(np.float32)
for i, img in enumerate(imgs):
m = img.mean()
s = img.std()
imgs[i] = (img - m) / s
return imgs
def dataArgument(data):
"""
dataArguments
data:
imgs: N x 1 x W x H
bbox: N x BBox
landmarks: N x 10
"""
pass
class BBox(object):
"""
Bounding Box of face
"""
def __init__(self, bbox):
self.left = bbox[0]
self.right = bbox[1]
self.top = bbox[2]
self.bottom = bbox[3]
self.x = bbox[0]
self.y = bbox[2]
self.w = bbox[1] - bbox[0]
self.h = bbox[3] - bbox[2]
def expand(self, scale=0.05):
bbox = [self.left, self.right, self.top, self.bottom]
bbox[0] -= int(self.w * scale)
bbox[1] += int(self.w * scale)
bbox[2] -= int(self.h * scale)
bbox[3] += int(self.h * scale)
return BBox(bbox)
def project(self, point):
x = (point[0]-self.x) / self.w
y = (point[1]-self.y) / self.h
return np.asarray([x, y])
def reproject(self, point):
x = self.x + self.w*point[0]
y = self.y + self.h*point[1]
return np.asarray([x, y])
def reprojectLandmark(self, landmark):
p = np.zeros((len(landmark), 2))
for i in range(len(landmark)):
p[i] = self.reproject(landmark[i])
return p
def projectLandmark(self, landmark):
p = np.zeros((len(landmark), 2))
for i in range(len(landmark)):
p[i] = self.project(landmark[i])
return p
def subBBox(self, leftR, rightR, topR, bottomR):
leftDelta = self.w * leftR
rightDelta = self.w * rightR
topDelta = self.h * topR
bottomDelta = self.h * bottomR
left = self.left + leftDelta
right = self.left + rightDelta
top = self.top + topDelta
bottom = self.top + bottomDelta
return BBox([left, right, top, bottom])

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









