







本源码解析基于JDK1.7,参考[HashMap]HashMap,HashTable
概要
- ConcurrentHashMap实现了HashTable的全部方法,且是线程安全的Map
- HashTable的put,get等方法都是同步的,效率较低,ConcurrentHashMap通过对table进行分段加锁,当一部分在修改时,其他部分可以同时的操作,在保证线程安全的情况下提高了效率
- concurrencyLevel用来确定划分段的数目,默认为16,值越大可支持的并发度越高,操作的开销就越大
- key和value都不允许为null
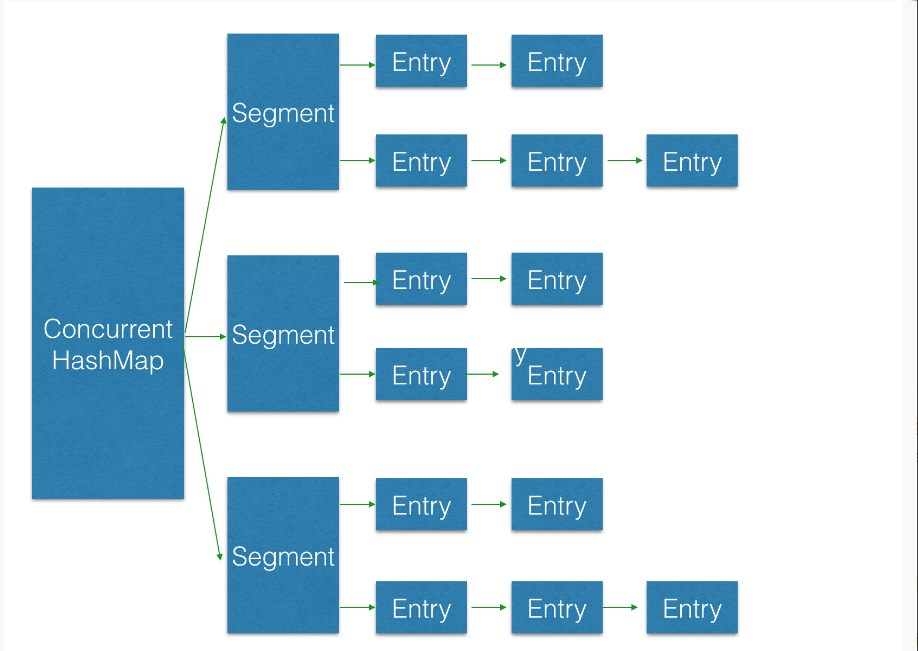
- 基本存储结构
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组,每个segment都保存自己的count,而不是整个HashMap保存一份count,避免了多个segment共享一个变量成为性能瓶颈
Java内存模型
由于 ConcurrentHashMap 是建立在 Java 内存模型基础上的,为了更好的理解 ConcurrentHashMap,让我们首先来了解一下 Java 的内存模型。
Java 语言的内存模型由一些规则组成,这些规则确定线程对内存的访问如何排序以及何时可以确保它们对线程是可见的。下面我们将分别介绍 Java 内存模型的重排序,内存可见性和 happens-before 关系。
重排序
内存模型描述了程序的可能行为。具体的编译器实现可以产生任意它喜欢的代码 – 只要所有执行这些代码产生的结果,能够和内存模型预测的结果保持一致。这为编译器实现者提供了很大的自由,包括操作的重排序。
编译器生成指令的次序,可以不同于源代码所暗示的“显然”版本。重排序后的指令,对于优化执行以及成熟的全局寄存器分配算法的使用,都是大有脾益的,它使得程序在计算性能上有了很大的提升。
重排序类型包括:
- 编译器生成指令的次序,可以不同于源代码所暗示的“显然”版本。
- 处理器可以乱序或者并行的执行指令。
- 缓存会改变写入提交到主内存的变量的次序。
内存可见性
由于现代可共享内存的多处理器架构可能导致一个线程无法马上(甚至永远)看到另一个线程操作产生的结果。所以 Java 内存模型规定了 JVM 的一种最小保证:什么时候写入一个变量对其他线程可见。
在现代可共享内存的多处理器体系结构中每个处理器都有自己的缓存,并周期性的与主内存协调一致。假设线程 A 写入一个变量值 V,随后另一个线程 B 读取变量 V 的值,在下列情况下,线程 B 读取的值可能不是线程 A 写入的最新值:
- 执行线程 A 的处理器把变量 V 缓存到寄存器中。
- 执行线程 A 的处理器把变量 V 缓存到自己的缓存中,但还没有同步刷新到主内存中去。
- 执行线程 B 的处理器的缓存中有变量 V 的旧值。
Happens-before 关系
happens-before 关系保证:如果线程 A 与线程 B 满足 happens-before 关系,则线程 A 执行动作的结果对于线程 B 是可见的。如果两个操作未按 happens-before 排序,JVM 将可以对他们任意重排序。
下面介绍几个与理解 ConcurrentHashMap 有关的 happens-before 关系法则:
1. 程序次序法则:如果在程序中,所有动作 A 出现在动作 B 之前,则线程中的每动作 A 都 happens-before 于该线程中的每一个动作 B。
2. 监视器锁法则:对一个监视器的解锁 happens-before 于每个后续对同一监视器的加锁。
3. Volatile 变量法则:对 Volatile 域的写入操作 happens-before 于每个后续对同一 Volatile 的读操作。
4. 传递性:如果 A happens-before 于 B,且 B happens-before C,则 A happens-before C。
Reentlock与内置锁
ReentrantLock和synchronized不同在于
- 后者在因为资源等待时刻,线程如果被唤醒就是打断(中止),但是在前者中,等待的线程可以在等待一段时间之后继续进行其他的工作。无需一直等待。
- ReentrantLock在使用的时候是直接构造一个ReentrantLock对象,而不是使用的对象的内部锁。所以在最终需要在finally块中保证释放锁,而synchronized同步锁则是由JVM自动释放的。典型的应用如下:(记得必须释放锁)
Lock lock= new ReentrantLock();
lock.lock();
try{
//update object state
}catch{
//catch the exception
}finally{
lock.unlock();
}- 效率更高,且可以设计公平性。公平性是指在等待队列中,等待时间更长的线程更有可能得到锁(资源),synchronized本身是不公平的,考虑优先级的。在java.util.concurrent.locks包中ReentLock可以设计公平性,但是公平性的锁机制效率很低。
Unsafe 机制
- 这里Unsafe的主要作用是提供原子操作
- Unsafe机制可以让你突破Java语法的限制,做许多非法的操作(突破限制创建实例,使用直接获取内存的方式实现浅克隆,创建超大数组)等,他会带来许多内存安全方面的问题,非特殊情况慎用
sun.misc.Unsafe UNSAFE该类存在与sun包中,并不随源码一起发布,参考链接
private static final sun.misc.Unsafe UNSAFE;
private static final long SBASE;
private static final int SSHIFT;
private static final long TBASE;
private static final int TSHIFT;
private static final long HASHSEED_OFFSET;
private static final long SEGSHIFT_OFFSET;
private static final long SEGMASK_OFFSET;
private static final long SEGMENTS_OFFSET;
static {
int ss, ts;
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class tc = HashEntry[].class;
Class sc = Segment[].class;
TBASE = UNSAFE.arrayBaseOffset(tc);
SBASE = UNSAFE.arrayBaseOffset(sc);
ts = UNSAFE.arrayIndexScale(tc);
ss = UNSAFE.arrayIndexScale(sc);
HASHSEED_OFFSET = UNSAFE.objectFieldOffset(
ConcurrentHashMap.class.getDeclaredField("hashSeed"));
SEGSHIFT_OFFSET = UNSAFE.objectFieldOffset(
ConcurrentHashMap.class.getDeclaredField("segmentShift"));
SEGMASK_OFFSET = UNSAFE.objectFieldOffset(
ConcurrentHashMap.class.getDeclaredField("segmentMask"));
SEGMENTS_OFFSET = UNSAFE.objectFieldOffset(
ConcurrentHashMap.class.getDeclaredField("segments"));
} catch (Exception e) {
throw new Error(e);
}
if ((ss & (ss-1)) != 0 || (ts & (ts-1)) != 0)
throw new Error("data type scale not a power of two");
SSHIFT = 31 - Integer.numberOfLeadingZeros(ss);
TSHIFT = 31 - Integer.numberOfLeadingZeros(ts);
} 类的头部
- 该类由AbstractMap扩展而来,AbstractMap实现了一些方法
- 与其他Map相比,可序列化,但是没有实现Clonable
- ConcurrentMap除了包含Map接口的方法外,增加了putIfAbsent,remove,replace方法
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
public interface ConcurrentMap<K, V> extends Map<K, V> {
V putIfAbsent(K key, V value);
boolean remove(Object key, Object value);
boolean replace(K key, V oldValue, V newValue);
V replace(K key, V value);
}
public interface Map<K,V> {
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
V put(K key, V value);
V remove(Object key);
void putAll(Map<? extends K, ? extends V> m);
void clear();
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
boolean equals(Object o);
int hashCode();
}
boolean equals(Object o);
int hashCode();
} 常数项
- 与HashMap类似,Capacity表示table数组总大小,LoadFactor时间空间效率平衡参数,默认值与HashMap相同
- ConcurrencyLevel,并发系数,即segment个数,系数越大分段越多,开销越大,换取更大的并发度
- RETRIES_BEFORE_LOCK在size,containsValue方法获取锁时的重试次数,
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
static final int RETRIES_BEFORE_LOCK = 2; 重要成员
- hashSeed 进一步打乱key的hash值,减少hash碰撞
- segmentMask key的hash值的高位与segmentMask来确定segment号,算法:hash左移segmentShift位于segmentMask按位与得到segment号
- KeySet等为Map的视图,即提供对map不同的操作方式
private transient final int hashSeed = randomHashSeed(this);
final int segmentMask;
final int segmentShift;
final Segment<K,V>[] segments;
transient Set<K> keySet;
transient Set<Map.Entry<K,V>> entrySet;
transient Collection<V> values; 基本节点
- Entry 实现比HashMap中简单,没有key,value的get set方法,以及equals,hashCode等方法
- 其hash与key声明为了final,value和next域声明为volatile
- 添加了方法setNext,两个静态变量 NUSAFE,nextOffset,用来处理next域
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
final void setNext(HashEntry<K,V> n) {
UNSAFE.putOrderedObject(this, nextOffset, n);
}
// Unsafe mechanics
static final sun.misc.Unsafe UNSAFE;
static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = HashEntry.class;
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
} 构造函数
- 通过参数进行构造
- 首先ssize确定比segmentLevel大的首个2的幂次,代表了segment的总个数,同时记录ssize移位次数sshift
- ssize-1得到segmentMask,由于ssize为2的幂次,按位与即取余操作
- segmentShift代表hash值需要左移的位数,由32-sshift得到
- 每个segment的大小是不小于 initialCapacity/ssize的最小的2的幂次,即每个segment内Entry数是2的幂次
- 初始化时只创建了一个segment,懒加载可以提交初始化效率
- 通过其他map来进行构造
首先由原map确定initialCapacity,其他使用默认值进行默认初始化,然后将原map元素逐个插入
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
// segment构造函数
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY),
DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
putAll(m);
}
public void putAll(Map<? extends K, ? extends V> m) {
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
} 查询操作 get
(((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASEsegment的定位采用了Unsafe机制,(h >>> segmentShift) & segmentMask通过移位和按位与操作取得hash值的高位对segment进行定位- 在segment内部采用与HashMap类似的查找方式,逐个遍历table数组点,如果对应位置不为空再遍历该位置上的链表
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
} 插入更新操作
int j = (hash >>> segmentShift) & segmentMask,取hash值的高位定位segment号s = ensureSegment(j);,由于初始化时使用了懒加载,并没有初始化所有的segment,该函数用来根据segment[0]首次创建对应segment- 构造HashEntry放入对应segment,
static final class Segment<K,V> extends ReentrantLock implements Serializable {,segment继承自Reentlock,在放入元素时首先尝试锁定,然后用key的hash值的低位(通过与table.length-1按位与,由于table.lenght是2的幂次,按位与即取余操作),定位在segment的table数组中的位置,然后执行头插法,将元素插入 - 注意如果插入位置已有元素就不会执行扩容,只有插入到segment的table位置不为空时才会检查
capacity*loadFactor>size而调用rehash方法进行扩容 - 每个segment都保存自己的count,而不是整个HashMap保存一份count,避免了多个segment共享一个变量成为性能瓶颈
- 获取头节点时的检查
由于在并发环境下,其他线程的put,rehash或者remove操作可能会导致链表头结点的变化,因此在过程中需要进行检查,如果头结点发生变化则重新对表进行遍历。而如果其他线程引起了链表中的某个节点被删除,可能导致当前线程无法观察到,但因为不影响遍历的正确性所以忽略不计。之所以在获取锁的过程中对整个链表进行遍历,主要目的是希望遍历的链表被CPU cache所缓存,为后续实际put过程中的链表遍历操作提升性能。 - ConcurrentHashMap对扩容方法rehash进行了优化,这种优化在存在连续的节点在扩容后index不变的情况下才会有效
- 首先不同的hash值的key被定位到table的同一index位置是由于取余操作。
- 由于HashMap扩容是二倍扩容,在原table上指定位置的元素由于取余的数组长度加倍,rehash后可能会定位到原来位置加上原数组长度的位置
- 由于有大量的Entry在扩容后还是留在原Index,所以没有必要全部重建Entry
- rehash方法中会定位第一个后续所有节点在扩容后index都保持不变的节点,只需要将该节点作为头结点插入指定位置,则该节点后续节点都不需要复制
- 该节点之前的节点需要进行复制到对应的位置
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
// 当对应segment不存在时,创建对应segment
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
// segment 类内部函数
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
} 统计元素个数 size()
- 首先尝试锁定所有segment
- 然后对每个segment的count值进行加和,并验证是否超过Integer.MaxValue,如果超过返回Integer.MaxValue
- 在finally块中释放锁,确保释放操作的执行
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
} 其他操作
- containsValue 与size()操作类似
- containsKey 与get()方法类似
public boolean containsKey(Object key) {
Segment<K,V> s; // same as get() except no need for volatile value read
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return true;
}
}
return false;
}
public boolean containsValue(Object value) {
// Same idea as size()
if (value == null)
throw new NullPointerException();
final Segment<K,V>[] segments = this.segments;
boolean found = false;
long last = 0;
int retries = -1;
try {
outer: for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
long hashSum = 0L;
int sum = 0;
for (int j = 0; j < segments.length; ++j) {
HashEntry<K,V>[] tab;
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null && (tab = seg.table) != null) {
for (int i = 0 ; i < tab.length; i++) {
HashEntry<K,V> e;
for (e = entryAt(tab, i); e != null; e = e.next) {
V v = e.value;
if (v != null && value.equals(v)) {
found = true;
break outer;
}
}
}
sum += seg.modCount;
}
}
if (retries > 0 && sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return found;
} 迭代器
- 一个segment遍历完需要跳到另一个segment
- segment内部当一个table数组点的位置的链表遍历结束,跳到下一个table index位置处
abstract class HashIterator {
int nextSegmentIndex;
int nextTableIndex;
HashEntry<K,V>[] currentTable;
HashEntry<K, V> nextEntry;
HashEntry<K, V> lastReturned;
HashIterator() {
nextSegmentIndex = segments.length - 1;
nextTableIndex = -1;
advance();
}
/**
* Set nextEntry to first node of next non-empty table
* (in backwards order, to simplify checks).
*/
final void advance() {
for (;;) {
if (nextTableIndex >= 0) {
if ((nextEntry = entryAt(currentTable,
nextTableIndex--)) != null)
break;
}
else if (nextSegmentIndex >= 0) {
Segment<K,V> seg = segmentAt(segments, nextSegmentIndex--);
if (seg != null && (currentTable = seg.table) != null)
nextTableIndex = currentTable.length - 1;
}
else
break;
}
}
final HashEntry<K,V> nextEntry() {
HashEntry<K,V> e = nextEntry;
if (e == null)
throw new NoSuchElementException();
lastReturned = e; // cannot assign until after null check
if ((nextEntry = e.next) == null)
advance();
return e;
}
public final boolean hasNext() { return nextEntry != null; }
public final boolean hasMoreElements() { return nextEntry != null; }
public final void remove() {
if (lastReturned == null)
throw new IllegalStateException();
ConcurrentHashMap.this.remove(lastReturned.key);
lastReturned = null;
}
} 总结
由于对于Map而言,读操作使用频度要远大于写入修改。通过 HashEntry 对象的不变性和用 volatile 型变量协调线程间的内存可见性,使得 大多数时候,读操作不需要加锁就可以正确获得值。ConcurrentHashMap 是一个并发散列映射表的实现,它允许完全并发的读取,并且支持给定数量的并发更新。相比于 HashTable 和用同步包装器包装的 HashMap(Collections.synchronizedMap(new HashMap())),ConcurrentHashMap 拥有更高的并发性。在 HashTable 和由同步包装器包装的 HashMap 中,使用一个全局的锁来同步不同线程间的并发访问,这虽然保证多线程间的安全并发访问,但同时也导致对容器的访问变成串行化的了。
在使用锁来协调多线程间并发访问的模式下,减小对锁的竞争可以有效提高并发性。有两种方式可以减小对锁的竞争:
- 减小请求 同一个锁的 频率。
- 减少持有锁的 时间。
ConcurrentHashMap 的高并发性主要来自于三个方面:
- 用分离锁实现多个线程间的更深层次的共享访问。
- 用 HashEntery 对象的不变性来降低执行读操作的线程在遍历链表期间对加锁的需求。
- 通过对同一个 Volatile 变量的写 / 读访问,协调不同线程间读 / 写操作的内存可见性。















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









