







Samza的Job是运行在Yarn上的,那么它是如何运行在Yarn上的,这几天看了源码,并将其过程记录下来。
先来看看Yarn是如何运行一个Job的。下图是Yarn官网的架构图。
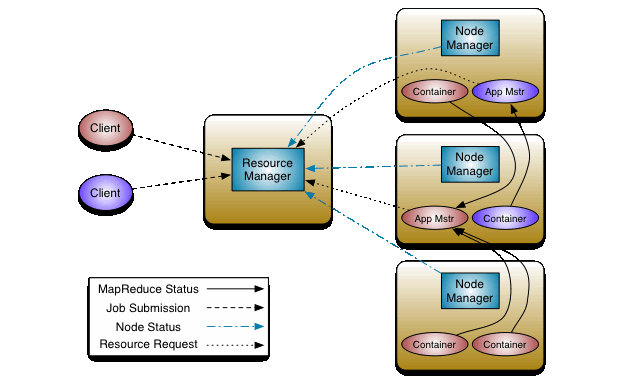
架构图中展现的是提交2个Job示例。
提交一个Job的基本过程:
- Client将Job提交到RM(使用YarnClient 类)
- RM根据当前资源分配Node Manager资源运行App Manager
- AppManager向RM申请运行Container的Node Manager资源,得到资源后运行Container
- Container中执行你提交的Job
可以看出要在Yarn上运行一个Job需要有三样东西:
- Client:提交Job到Yarn上
- App Master:申请资源、启动Container
- Container:运行程序(我们写的处理程序就在这里运行)
接下来我们一起看看Samza是如何将Job运行在Yarn上的。
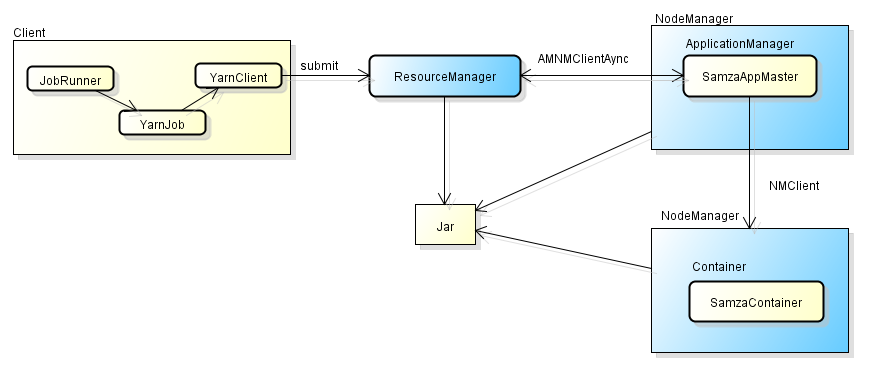
- 在Samza中是利用JobRunner提交Job到RM中的,由于Samza对于Yarn、Kafka是可插拔的,因此在此处调用了YarnJob类实际完成这个功能的。
- Samza中的AppMaster就是SamzaAppMaster类,该类与RM通信,申请资源,与NM通信启动自己的Container—SamzaContainer
- SamzaContainer启动后,会执行我们写的Task。
下面我们一起从源代码中(0.91版本)看看具体是如何处理的。
- Client提交Job,启动SamzaAppMaster的过程
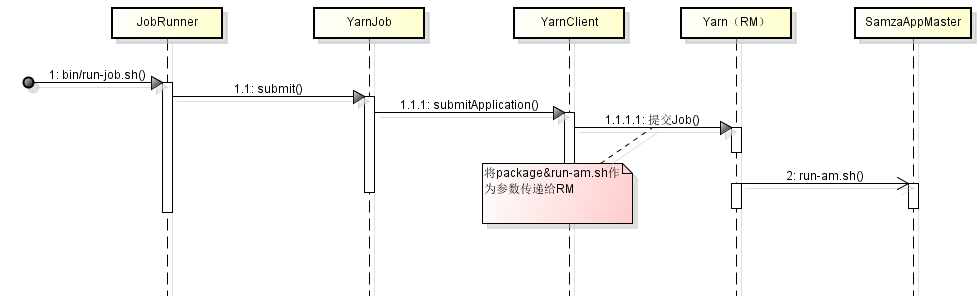
Samza是利用bin/run-job.sh提交Job的,例(hello-samza中提交Job):
deploy/samza/bin/run-job.sh --config-factory=org.apache.samza.config.factories.PropertiesConfigFactory --config-path=file://$PWD/deploy/samza/config/wikipedia-feed.properties脚本实际调用org.apache.samza.job.JobRunner来解析配置文件,以及提交Job的。
run-job.sh的内容:
exec $(dirname $0)/run-class.sh **org.apache.samza.job.JobRunner** "$@"由于配置文件中job.factory.class=org.apache.samza.job.yarn.YarnJobFactory(该处可以配置ProcessJobFactory或者ThreadJobFactory,但我只分析运行在Yarn上的情况),因此在JobRunner中实际调用了YarnJob的submit,在submit中调用的是YarnClient的submitApplication方法。其中submitApplication中接收了一个类型为ApplicationSubmissionContext参数,其中主要包括package(我们写的程序的jar包)的path,以及启动SamzaAppMaster命令行。详细代码:
def submit: YarnJob = {
appId = client.submitApplication(/*实际调用的是YarnClient的submitApplication,YarnClient这个类主要是将job提交给Yarn的RM*/
new Path(config.getPackagePath.getOrElse(throw new SamzaException("No YARN package path defined in config.")))/*APK的路径,①http可以下载的url②hdfs的路径*/,
config.getAMContainerMaxMemoryMb.getOrElse(DEFAULT_AM_CONTAINER_MEM),
1,
List(
"export SAMZA_LOG_DIR=%s && ln -sfn %s logs && exec ./__package/bin/run-am.sh 1>logs/%s 2>logs/%s"/*Yarn的RM会执行run-am.sh来启动Samza的SamzaAppMaster*/
format (ApplicationConstants.LOG_DIR_EXPANSION_VAR, ApplicationConstants.LOG_DIR_EXPANSION_VAR, ApplicationConstants.STDOUT, ApplicationConstants.STDERR)),
Some({
val envMap = Map(
ShellCommandConfig.ENV_CONFIG -> Util.envVarEscape(SamzaObjectMapper.getObjectMapper.writeValueAsString(config)),
ShellCommandConfig.ENV_JAVA_OPTS -> Util.envVarEscape(config.getAmOpts.getOrElse("")))
val envMapWithJavaHome = config.getAMJavaHome match {
case Some(javaHome) => envMap + (ShellCommandConfig.ENV_JAVA_HOME -> javaHome)/*一些环境变量*/
case None => envMap
}
envMapWithJavaHome
}),
Some("%s_%s" format (config.getName.get, config.getJobId.getOrElse(1))))
this
}到目前为止,已经将我们的Job提交给Yarn的RM,并且RM可以启动SamzaAppMaster。
-SamzaAppMaster申请资源、启动Container的过程:
SamzaAppMaster实现了 AMRMClientAsync.CallbackHandler接口。该接口的作用是AppMaster向Yarn的RM申请资源成功后的回调函数,用以通知SamzaAppMaster。SamzaAppMaster接到通知后通知Yarn的Node Manerger来启动SamzaContainer,这样我们的Job就会被执行了。
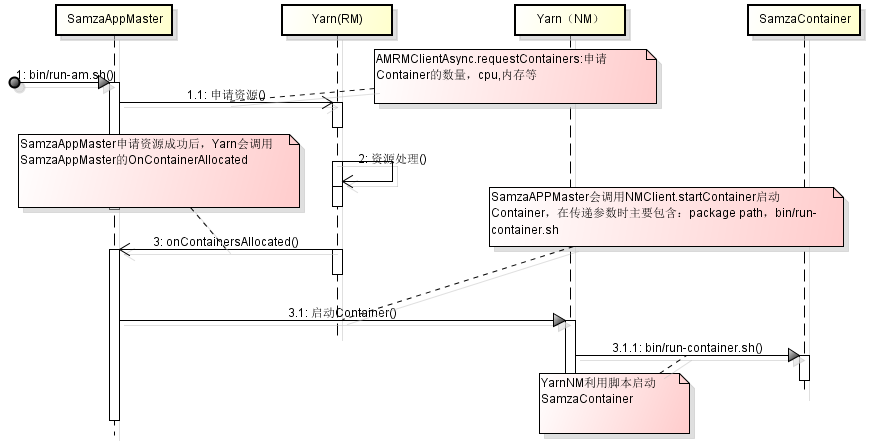
下面看看代码片段:
object SamzaAppMaster extends Logging with AMRMClientAsync.CallbackHandler {
...
val amClient = AMRMClientAsync.createAMRMClientAsync[ContainerRequest](interval, this)/*this:将自己注册给Yarn的RM,待资源申请成功后会调用自己类的onContainersAllocated*/
...
val state = new SamzaAppMasterState(-1, containerId, nodeHostString, nodePortString.toInt, nodeHttpPortString.toInt)
val service = new SamzaAppMasterService(config, state, registry, clientHelper)
val lifecycle = new SamzaAppMasterLifecycle(containerMem, containerCpu, state, amClient)
val metrics = new SamzaAppMasterMetrics(config, state, registry)
val am = new SamzaAppMasterTaskManager({ System.currentTimeMillis }, config, state, amClient, hConfig)/*这个类主要与NM通信,并启动Container*/
listeners = List(state, service, lifecycle, metrics, am)
run(amClient, listeners, hConfig, interval)/**/
}
def run(amClient: AMRMClientAsync[ContainerRequest], listeners: List[YarnAppMasterListener], hConfig: YarnConfiguration, interval: Int): Unit = {
try {
amClient.init(hConfig)
amClient.start
listeners.foreach(_.onInit)/*此处启动所有监听和服务,也启动了SamzaAppMasterTaskManager类*/
...
}
override def onContainersAllocated(containers: java.util.List[Container]): Unit =
containers.foreach(container => listeners.foreach(_.onContainerAllocated(container)))/*资源申请成功,Yarn 的RM的回调(图中的3),真正启动SamzaContainer的是SamzaAppMasterTaskManager类中的onContainerAllocated函数*/
--------------------------------------------------------------------
SamzaAppMasterTaskManager类:
override def onInit() {
state.neededContainers = state.taskCount
state.unclaimedTasks = state.jobCoordinator.jobModel.getContainers.keySet.map(_.toInt).toSet
containerManager = NMClient.createNMClient()
containerManager.init(conf)
containerManager.start/*建立与NM的通信*/
info("Requesting %s containers" format state.taskCount)
requestContainers(config.getContainerMaxMemoryMb.getOrElse(DEFAULT_CONTAINER_MEM), config.getContainerMaxCpuCores.getOrElse(DEFAULT_CPU_CORES), state.neededContainers)/*向RM申请资源(图中的1.1)*/
}
override def onContainerAllocated(container: Container) {/*Container申请成功后的回调函数*/
...
val cmdBuilderClassName = config.getCommandClass.getOrElse(classOf[ShellCommandBuilder].getName)/*获得ShellCommandBuilder类,此类中包含启动SamzaContainer的脚本命令*/
val cmdBuilder = Class.forName(cmdBuilderClassName).newInstance.asInstanceOf[CommandBuilder]
.setConfig(config)
.setId(taskId)
.setUrl(state.coordinatorUrl)
val command = cmdBuilder.buildCommand/*得到的就是bin/run-container.sh*/
...
val cmdBuilderClassName = config.getCommandClass.getOrElse(classOf[ShellCommandBuilder].getName)
val cmdBuilder = Class.forName(cmdBuilderClassName).newInstance.asInstanceOf[CommandBuilder]
.setConfig(config)
.setId(taskId)
.setUrl(state.coordinatorUrl)
val command = cmdBuilder.buildCommand
...
startContainer(/*调用内部函数,实际调用的是NMClient.createNMClient().startContainer()*/
path/*我们提交的PKG的路径*/,
container,
env.toMap,
"export SAMZA_LOG_DIR=%s && ln -sfn %s logs && exec ./__package/%s 1>logs/%s 2>logs/%s" format (ApplicationConstants.LOG_DIR_EXPANSION_VAR, ApplicationConstants.LOG_DIR_EXPANSION_VAR, command/*此处将启动SamzaContainer的脚本传递给NM,NM得到PKG的路径后将PKG解压,之后就可以执行脚本启动Container*/, ApplicationConstants.STDOUT, ApplicationConstants.STDERR))
}
protected def startContainer(packagePath: Path, container: Container, env: Map[String, String], cmds: String*) {
...
containerManager.startContainer(container, ctx)
...
}-SamzaContainer运行Task的过程
具体执行的过程SamzaContainer–>main–>safeMain–>apply–>run–>RunLoop.run–>RunLoop.process
解释一下:
1、main是默认被执行的,里面直接调用了safeMain
2、在safeMain最后调用了Object的SamzaContainer(containerModel, jobModel).run
3、由于SamzaContainer是Object,那么首先会默认会执行apply,在apply中主要是对一些变量赋值、初始化,包括初始化Task实例
4、在run中主要开始对消息开始轮训处理
5、RunLoop.run这个是真正向process里读取数据的线程
6、RunLoop.process会最终调用我们写的函数
主要还是看代码吧:
object SamzaContainer extends Logging {
def main(args: Array[String]) {
safeMain(() => new JmxServer, new SamzaContainerExceptionHandler(() => System.exit(1)))
}
def safeMain{
...
jmxServer = newJmxServer()
SamzaContainer(containerModel, jobModel).run/*这里开始执行了*/
...
}
/*---------------------------------------------------*/
/*apply函数:初始化Task实例*/
def apply(containerModel: ContainerModel, jobModel: JobModel) = {
...
val taskClassName = config
.getTaskClass
.getOrElse(throw new SamzaException("No task class defined in configuration.")) /*获取配置文件中的val TASK_CLASS = "task.class" // streaming.task-factory-class*/
...
/*下面就是获取Task的实例*/
val taskInstances: Map[TaskName, TaskInstance] = containerModel.getTasks.values.map(taskModel => {
debug("Setting up task instance: %s" format taskModel)
val taskName = taskModel.getTaskName
val task = Util.getObj[StreamTask](taskClassName)
val taskInstanceMetrics = new TaskInstanceMetrics("TaskName-%s" format taskName)
val collector = new TaskInstanceCollector(producerMultiplexer, taskInstanceMetrics)
val storeConsumers = changeLogSystemStreams
.map {
case (storeName, changeLogSystemStream) =>
val systemConsumer = systemFactories
.getOrElse(changeLogSystemStream.getSystem, throw new SamzaException("Changelog system %s for store %s does not exist in the config." format (changeLogSystemStream, storeName)))
.getConsumer(changeLogSystemStream.getSystem, config, taskInstanceMetrics.registry)
(storeName, systemConsumer)
}.toMap
...
/*真正的Task生成了*/
val taskInstance = new TaskInstance(
task = task,
taskName = taskName,/*这个获取的就是配置文件中task.class声明的类*/
config = config,
metrics = taskInstanceMetrics,
consumerMultiplexer = consumerMultiplexer,
collector = collector,
offsetManager = offsetManager,
storageManager = storageManager,
reporters = reporters,
systemStreamPartitions = systemStreamPartitions,
exceptionHandler = TaskInstanceExceptionHandler(taskInstanceMetrics, config))
(taskName, taskInstance)
}).toMap
}run函数:
def run {
try {
info("Starting container.")
/*启动&初始化进程*/
startMetrics
startOffsetManager
startStores
startProducers
startTask
startConsumers
info("Entering run loop.")
runLoop.run/*这个是真正的获取Kafka中的内容,也就是我写的process就在这里*/
} catch {
case e: Exception =>
error("Caught exception in process loop.", e)
throw e
} finally {
info("Shutting down.")
shutdownConsumers
shutdownTask
shutdownProducers
shutdownStores
shutdownOffsetManager
shutdownMetrics
info("Shutdown complete.")
}
}Looper.run函数:
*/
def run {
addShutdownHook(Thread.currentThread())
while (!shutdownNow) {
process /*找到了,在这里*/
window
commit
}
}process函数:
private def process {
trace("Attempting to choose a message to process.")
metrics.processes.inc
updateTimer(metrics.processMs) {
val envelope = updateTimer(metrics.chooseMs) {
consumerMultiplexer.choose
}
if (envelope != null) {
val ssp = envelope.getSystemStreamPartition
trace("Processing incoming message envelope for SSP %s." format ssp)
metrics.envelopes.inc
val taskInstance = systemStreamPartitionToTaskInstance(ssp)
val coordinator = new ReadableCoordinator(taskInstance.taskName)
taskInstance.process(envelope, coordinator)/*是不是很熟悉了,我们写的程序终于被调用了*/
checkCoordinator(coordinator)
} else {
trace("No incoming message envelope was available.")
metrics.nullEnvelopes.inc
}
}
}到此我们的程序在Yarn上已经运行了。















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









