







 本文探讨了推荐系统召回阶段的策略,包括用户行为序列召回、用户多兴趣拆分和知识图谱融合召回。模型召回解决了多路召回的截断问题,但可能引发头部领域集中问题。用户行为序列召回利用GRU、CNN和Transformer等模型捕捉兴趣。用户多兴趣拆分通过胶囊网络和记忆网络实现兴趣细分,缓解召回头部问题。知识图谱融合召回利用物品间的知识联系增强推荐效果。
本文探讨了推荐系统召回阶段的策略,包括用户行为序列召回、用户多兴趣拆分和知识图谱融合召回。模型召回解决了多路召回的截断问题,但可能引发头部领域集中问题。用户行为序列召回利用GRU、CNN和Transformer等模型捕捉兴趣。用户多兴趣拆分通过胶囊网络和记忆网络实现兴趣细分,缓解召回头部问题。知识图谱融合召回利用物品间的知识联系增强推荐效果。
推荐排序——召回 笔记
模型召回具备自己独有的好处和优势,比如多路召回每路截断条数的超参个性化问题等会自然被消解掉。当然,它也会带来自己的问题,比较典型的是召回内容头部问题,因为之前多路,每路召回个数靠硬性截断,可以根据需要,保证你想要召回的,总能通过某一路拉回来;而由于换成了模型召回,面向海量物料库,排在前列得分高的可能聚集在几个物料分布比较多的头部领域。解决这个问题的方法包括比如训练数据对头部领域的降采样,减少某些领域主导,以及在模型角度鼓励多样性等不同的方法。
如果在召回阶段使用模型召回,理论上也应该同步采用和排序模型相同的优化目标,尤其是如果排序阶段采用多目标优化的情况下,召回模型也应该对应采取相同的多目标优化。同理,如果整个流程中包含粗排模块,粗排也应该采用和精排相同的多目标优化,几个环节优化目标应保持一致。因为召回和粗排是精排的前置环节,否则,如果优化目标不一致,很可能会出现高质量精排目标,在前置环节就被过滤掉的可能,影响整体效果。
典型工作
- FM模型召回:推荐系统召回四模型之:全能的FM模型
- DNN双塔召回:Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations
用户行为序列召回

抽象地来看的话,利用用户行为过的物品序列对用户兴趣建模,本质上就是这么个过程:输入是用户行为过的物品序列,可以只用物品ID表征,也可以融入物品的Side Information比如名称,描述,图片等,现在我们需要一个函数Fun,这个函数以这些物品为输入,需要通过一定的方法把这些进行糅合到一个embedding里,而这个糅合好的embedding,就代表了用户兴趣。无论是在召回过程,还是排序过程,都可以融入用户行为序列。在召回阶段,我们可以用用户兴趣Embedding采取向量召回,而在排序阶段,这个embedding则可以作为用户侧的特征。
所以,核心在于:这个物品聚合函数Fun如何定义的问题。这里需要注意的一点是:用户行为序列中的物品,是有时间顺序的。理论上,任何能够体现时序特点或特征局部性关联的模型,都比较适合应用在这里,典型的比如CNN、RNN、Transformer等,都比较适合用来集成用户行为序列信息。而目前的很多试验结果证明,GRU(RNN的变体模型)可能是聚合用户行为序列效果最好又比较简单的模型。当然,RNN不能并行的低效率,那是另外一个问题。
在召回阶段,如何根据用户行为序列打embedding,可以采取有监督的模型,比如Next Item Prediction的预测方式即可;也可以采用无监督的方式,比如物品只要能打出embedding,就能无监督集成用户行为序列内容,例如Sum Pooling。而排序侧,必然是有监督的模式,需要注意的是:排序侧表征用户特征的时候,可以只用用户行为过的物品序列,也可以混合用户其它特征,比如群体属性特征等一起来表征用户兴趣,方式比较灵活。比如DIEN,就是典型的采用混合模式的方法。
典型工作
- GRU:Recurrent Neural Networks with Top-k Gains for Session-based Recommendations
- CNN:Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
- Transformer: Self-Attentive Sequential Recommendation
用户多兴趣拆分
但是,另外一个现实是:用户往往是多兴趣的,比如可能同时对娱乐、体育、收藏感兴趣。这些不同的兴趣也能从用户行为序列的物品构成上看出来,比如行为序列中大部分是娱乐类,一部分体育类,少部分收藏类等。那么能否把用户行为序列物品中,这种不同类型的用户兴趣细分,而不是都笼统地打到一个用户兴趣Embedding里呢?用户多兴趣拆分就是解决这类更细致刻画用户兴趣的方向。

用户多兴趣拆分,本质上是上文所叙述的用户行为序列打embedding方向的一个细化,无非上文说的是:以用户行为序列物品作为输入,通过一些能体现时序特点的模型,映射成一个用户兴趣embedding。而用户多兴趣拆分,输入是一样的,输出不同,无非由输出单独一个用户embedding,换成输出多个用户兴趣embedding而已。虽说道理如此,但是在具体技术使用方向上却不太一样,对于单用户兴趣embedding来说,只需要考虑信息有效集成即可。
而对于多用户兴趣拆分来说,需要多做些事情,多做什么事情呢?本质上,把用户行为序列打到多个embedding上,实际它是个类似聚类的过程,就是把不同的Item,聚类到不同的兴趣类别里去。目前常用的拆分用户兴趣embedding的方法,主要是胶囊网络和Memory Network,但是理论上,很多类似聚类的方法应该都是有效的,所以完全可以在这块替换成你自己的能产生聚类效果的方法来做。
把用户行为序列拆分到不同的embedding里,有这个必要吗?反正不论怎样,即使是一个embedding,信息都已经包含到里面了,并未有什么信息损失问题呀。
在召回阶段,把用户兴趣拆分成多个embedding是有直接价值和意义的,前面我们说过,召回阶段有时候容易碰到头部问题,就是比如通过用户兴趣embedding拉回来的物料,可能集中在头部优势领域中,造成弱势兴趣不太能体现出来的问题。而如果把用户兴趣进行拆分,每个兴趣embedding各自拉回部分相关的物料,则可以很大程度缓解召回的头部问题。
so 这种兴趣拆分,在召回阶段是很合适的,可以定向解决它面临的一些实际问题。
在排序环节使用多兴趣Embedding能发生作用的地方,好像有一个:因为我们在计算user对某个item是否感兴趣的时候,对于用户行为序列物品,往往计算目标item和行为序列物品的Attention是有帮助的,因为用户兴趣是多样的,物品Item的类型归属往往是唯一的,所以行为序列里面只有一部分物品和当前要判断的Item是类型相关的,这会对判断有作用,其它的无关物品其实没啥用,于是Attention就是必要的,可以减少那些无关物品对当前物品判断的影响。 而当行为序列物品太多的时候,我们知道,Atttention计算是非常耗时的操作,如果我们把这种Attention计算,放到聚类完的几个兴趣embedding维度计算,无疑能极大提升训练和预测的速度。貌似这个优点还是成立的。
典型工作
- 召回:Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
- 排序:Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction
知识图谱融合召回
推荐系统中,最核心的数据是用户对物品的行为数据,因为这直接表明了用户兴趣所在。如上图所示,如果把用户放在一侧,物品放在另一侧,若用户对某物品有行为产生,则建立一条边,这样就构建了用户-物品交互的二部图。其实,有另外一种隐藏在冰山之下的数据,那就是物品之间是有一些知识联系存在的,就是我们常说的知识图谱,而这类数据是可以考虑用来增强推荐效果的,尤其是对于用户行为数据稀疏的场景,或者冷启动场景。以上图例子说明,用户点击过电影“泰坦尼克号”,这是用户行为数据,我们知道,电影“泰坦尼克号”的主演是莱昂纳多,于是可以推荐其它由莱昂纳多主演的电影给这个用户。后面这几步操作,利用的是电影领域的知识图谱数据,通过知识图谱中的“电影1—>主演—>电影2”的图路径给出的推荐结果。
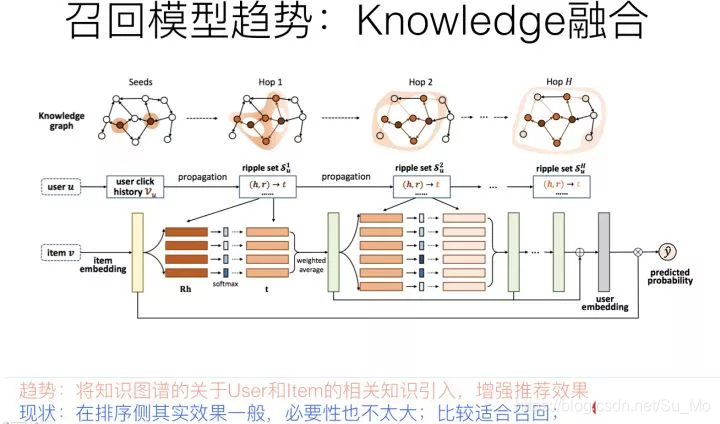
典型工作
- KGAT: Knowledge Graph Attention Network for Recommendation
- RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
- GraphSAGE: Inductive Representation Learning on Large Graphs
- PinSage: Graph Convolutional Neural Networks for Web-Scale Recommender Systems


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









