







 Lattice LSTM是2018年ACL论文《Chinese NER Using Lattice LSTM》提出的一种结构,它结合字符和词信息进行编码,解决了字粒度和词粒度编码的局限。通过额外的门控机制,Lattice LSTM能够在处理字符序列时融入词信息,有效地利用分词特征,尤其在中文NER任务中表现优秀。尽管实现较复杂,但该结构为引入分词信息提供了一种有效途径。
Lattice LSTM是2018年ACL论文《Chinese NER Using Lattice LSTM》提出的一种结构,它结合字符和词信息进行编码,解决了字粒度和词粒度编码的局限。通过额外的门控机制,Lattice LSTM能够在处理字符序列时融入词信息,有效地利用分词特征,尤其在中文NER任务中表现优秀。尽管实现较复杂,但该结构为引入分词信息提供了一种有效途径。
Lattice LSTM - 将分词信息带入LSTM
Lattice LSTM来自于2018年发表在ACL的文章《Chinese NER Using Lattice LSTM》。这里只介绍 Lattice LSTM,论文其它内容不作介绍。
Lattice LSTM能够将字符级别序列信息和该序列对应的词信息同时编码供模型自动取用。相较于字粒度(字符级)的编码,Lattice LSTM加入了词信息,丰富了语义表达;相较于词粒度的编码,Lattice LSTM可以避免分词错误带来的影响。
对于序列“南京市长江大桥“,每个位置的字粒度以及词粒度输入如下表所示:
| 当前位置( j j j) | 字粒度 | 词粒度 |
|---|---|---|
| 1 | 南 | |
| 2 | 京 | 南京 |
| 3 | 市 | 南京市 |
| 4 | 长 | 市长 |
| 5 | 江 | 长江 |
| 6 | 大 | |
| 7 | 桥 | 大桥、长江大桥 |
下图为Lattice LSTM处理字符序列(当前位置 j j j没有对应的词序列,如上表位置1和6所示情况)的LSTM结构。
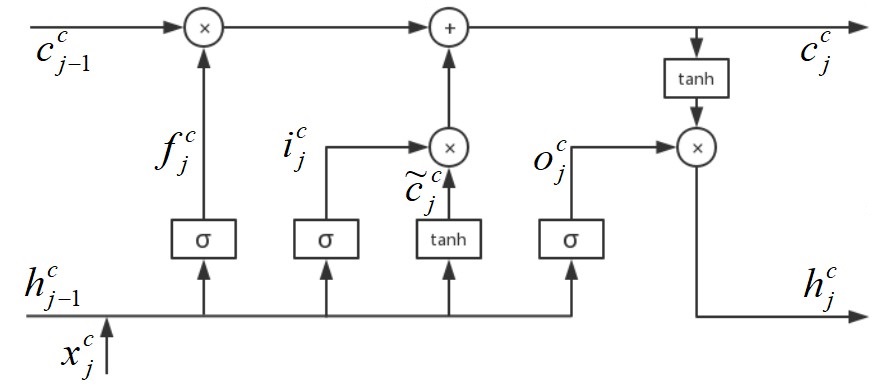
其对应的数学公式(上标 c c c表示字粒度变量,下标 j j j表示序列的当前位置, x j c x_j^c xjc表示当前输入的字粒度信息)如下:
[ i j c o j c f j c c ~ j c ] = [ σ σ σ t a n h ] ( W c ⊤ [ x j c h j − 1 c ] + b c ) c j c = f j c ⊙ c j − 1 c + i j c ⊙ c ~ j c h j c = o j c ⊙ t a n h ( c j c ) \begin{aligned} \left[ \begin{array}{cccc} \textbf{i}^c_j\\ \textbf{o}^c_j\\ \textbf{f}^c_j\\ \widetilde{\textbf{c}}^c_j \end{array} \right ] &= \left[ \begin{array}{cccc} \sigma\\ \sigma\\ \sigma\\ tanh \end{array} \right ] \left ( \textbf{W}^{c\top} \left [ \begin{array}{cc} \textbf{x}^c_j\\ \textbf{h}^c_{j-1} \end{array} \right ] +\textbf{b}^c \right ) \\ \textbf{c}^c_j &= \textbf{f}^c_j \odot \textbf{c}^c_{j-1} + \textbf{i}^c_j \odot \widetilde{\textbf{c}}^c_j \\ \textbf{h}^c_j &= \textbf{o}^c_j \odot tanh(\textbf{c}^c_j) \end{aligned} ⎣⎢⎢⎡ijcojcfjcc
jc⎦⎥⎥⎤cjchjc=⎣⎢⎢⎡σσσtanh⎦⎥⎥⎤(Wc⊤[x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2002
2002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









