







描述
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则返回 true ,否则返回 false 。假设输入的数组的任意两个数字都互不相同。
数据范围: 节点数量 0 ≤ n ≤ 1000 ,节点上的值满足 1 ≤ val ≤ 10^5 ,保证节点上的值各不相同
要求:空间复杂度 O(n) ,时间时间复杂度 O(n^2)
提示:
- 二叉搜索树是指父亲节点大于左子树中的全部节点,但是小于右子树中的全部节点的树。
- 该题我们约定空树不是二叉搜索树
- 后序遍历是指按照 “左子树-右子树-根节点” 的顺序遍历
- 参考下面的二叉搜索树,示例 1
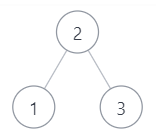
示例1
输入: [1,3,2]
返回值: true
说明:是上图的后序遍历 ,返回true
示例2
输入: [3,1,2]
返回值:false
说明:不属于上图的后序遍历,从另外的二叉搜索树也不能后序遍历出该序列 ,因为最后的2一定是根节点,前面一定是孩子节点,可能是左孩子,右孩
子,根节点,也可能是全左孩子,根节点,也可能是全右孩子,根节点,但是[3,1,2]的组合都不能满足这些情况,故返回false
前置知识
-
什么是二叉搜索树,简单来说,就是对于一个二叉树的所有的节点,如果都满足:
- 左子树的所有节点的权值都小于等于这个节点的权值。
- 右子树的所有节点的权值都大于等于这个节点的权值。
那么我们就可以称这棵二叉树为二叉搜索树,显然,样例这棵二叉树是满足这两个条件的。
- 什么是后序遍历,就是对于一棵二叉树,我们先遍历这棵二叉树的左子树,然后遍历这棵二叉树的右子树,最后遍历根节点,对子树的遍历同样需要满足这个规律。最后遍历下来的结果就称为后序遍历的序列。此外,还有前序遍历和中序遍历,其实这些称呼都是针对根节点何时被访问的顺序进行命名的。
思路分析
- 这个题目我最开始想的是用递归的写法进行求解。我们就递归判断左右子树是否满足,然后反馈到我们整个二叉树。我们观察后序遍历的结果,我们发现, 根节点的权值一定是这个序列的最右边的那个权值。 那么现在,我们要做的就是寻找到属于左右子树的节点的权值。根据二叉搜索树的规律,我们知道,寻找到当前序列第一个大于这个根节点权值的点,那么以这个点为分界线就可以大致地划分出左右子树。为什么是大致呢?因为我们还需要判断左右子树的点是否满足二叉搜索树的条件。
- 比如,一个序列
[4,8,6,12,7,14,10],我们发现我们找到第一个大于10的位置是12所在的位置,那么我们初步可以判断12-14之间就是右子树的节点的权值了,但是我们进一步判断发现右子树有一个7,大于10,显然是不符合的,所以在这里可以直接返回false.然后这样一层层递归下去进行判断就行了。
写法一(递归版)
代码如下,由于可能每个数都要访问,所以时间复杂度为O(n)
class Solution {
public:
// 为了减少参数的传递,我开了一个全局数组
vector<int> a;
int n;
bool dfs(int l,int r){
// 如果左边边界大于等于右边的边界,说明是符合的
if(l>=r) return true;
// mid记录左右子树的分界线
int mid=r;
for(int i=l;i<r;i++){
if(a[i]>a[r]){
mid=i;
break;
}
}
// 对左子树进行判断
for(int i=l;i<mid;i++){
if(a[i]>a[r]){
return false;
}
}
// 对右子树进行判断
for(int i=mid;i<r;i++){
if(a[i]<a[r]){
return false;
}
}
// 递归继续判断
return dfs(l,mid-1)&&dfs(mid,r-1);
}
bool VerifySquenceOfBST(vector<int> sequence) {
n=sequence.size();
if(n==0) return false;
// 先将序列里面的数字放到全局的vector里面
for(auto x:sequence){
a.push_back(x);
}
if(dfs(0,n-1)){
return true;
}
else{
return false;
}
}
};
运行时间:3ms
超过33.69% 用C++提交的代码
占用内存:628KB
超过14.94%用C++提交的代码
写法二(非递归版)
- 非递归写法是比较难想的,我想了好久,感觉还是想不出,所以参照了一些相关的博客,简单来说,非递归写法就是利用一个单调栈进行实现,同时需要利用到一个后序遍历的倒序,倒序之后,其实就是一个中,右,左的一个顺序了。其实质还是一个递归的思想,但是就是实现的方式不一样。这个写法就是先将递增的序列都放入栈,然后不断更新根节点,每次栈顶就是某一棵二叉树或者二叉子树的根节点的权,同时它的右子树一定已经判断完了,现在就只需要对左子树的节点进行判断了。如果现在左子树的某一个节点的权值大于当前的root节点的权值,那么就说明是不符合的。
- 时间复杂度为O(n)
class Solution {
public:
stack<int> st;
bool VerifySquenceOfBST(vector<int> sequence) {
if(sequence.size()==0) return false;
int len=sequence.size();
int root=0x3f3f3f3f;
for(int i=len-1;i>=0;i--){
// 左子树出现大于root根节点的权值
if(sequence[i]>root) return false;
while(!st.empty()&&st.top()>sequence[i]){
root=st.top();
// 这样下来,我们保证每次寻找的这个root,一定是某一个二叉树或者
// 二叉子树的一个根节点,并且将它的右子树的节点都出栈了。接下来就只要判断左子树了
st.pop();
}
st.push(sequence[i]);
}
return true;
}
};
运行时间:5ms
超过3.03% 用C++提交的代码
占用内存:552KB
超过22.59%用C++提交的代码
















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











