



目录
Pandas 缺失值处理函数详解
下面我将详细介绍这段代码中出现的 Pandas 函数方法,包括它们的用法和参数。
1. pd.read_csv()
功能:读取 CSV 文件并返回 DataFrame。
主要参数:
-
filepath_or_buffer:文件路径或文件对象 -
encoding:文件编码,如 'gbk', 'utf-8' 等 -
engine:解析引擎,可选 'c' (C语言引擎,更快) 或 'python' (Python引擎,功能更全) -
sep:分隔符,默认为 ',' -
header:指定作为列名的行号,默认为 0 (第一行) -
index_col:用作行索引的列编号或列名 -
na_values:指定哪些值应被视为 NA/NaN
示例:
df = pd.read_csv('data.csv', encoding='gbk', sep=',', header=0)2. DataFrame.isnull()
功能:检测缺失值,返回一个与原始 DataFrame 形状相同的布尔型 DataFrame。
特点:
-
缺失值 (NaN, None, NaT) 对应位置为 True
-
非缺失值对应位置为 False
-
别名:
isna()
相关方法:
-
notnull()/notna():与isnull()相反
示例:
na_mask = df.isnull()3. DataFrame.any()
功能:检查 DataFrame 或 Series 中是否存在 True/非零值。
参数:
-
axis:0 或 'index' (检查每列),1 或 'columns' (检查每行) -
bool_only:是否只检查布尔列 -
skipna:是否跳过 NA 值 (默认为 True)
示例:
# 检查每行是否有缺失值
has_na = df.isnull().any(axis=1)4. DataFrame.fillna()
功能:填充缺失值。
主要参数:
-
value:用于填充的值 (标量、字典、Series 或 DataFrame) -
method:填充方法 ('backfill', 'bfill', 'pad', 'ffill', None) -
axis:填充方向 (0: 沿列,1: 沿行) -
inplace:是否原地修改 (默认为 False) -
limit:最大填充数量
示例:
# 用 0 填充所有缺失值
df.fillna(0)
# 用各列均值填充
df.fillna(df.mean())
# 前向填充
df.fillna(method='ffill')5. DataFrame.dropna()
功能:删除含有缺失值的行或列。
主要参数:
-
axis:0 或 'index' (删除行),1 或 'columns' (删除列) -
how:'any' (有缺失就删除) 或 'all' (全部为缺失才删除) -
thresh:保留至少有 thresh 个非缺失值的行/列 -
subset:只在指定列中检查缺失值 -
inplace:是否原地修改
示例:
# 删除有缺失值的行 (默认)
df.dropna()
# 删除有缺失值的列
df.dropna(axis=1)
# 只删除在 'age' 列有缺失值的行
df.dropna(subset=['age'])6. 布尔索引
功能:使用布尔数组/Series 筛选 DataFrame。
用法:
df[boolean_mask]示例:
# 筛选出有缺失值的行
df[df.isnull().any(axis=1)]
# 筛选出 'age' 列有缺失值的行
df[df['age'].isnull()]7. 其他相关方法
DataFrame.mode()
功能:计算众数 (出现频率最高的值)。
示例:
# 用众数填充分类列
df['gender'].fillna(df['gender'].mode()[0])DataFrame.mean()
功能:计算平均值,常用于数值列填充。
示例:
# 用均值填充数值列
df['age'].fillna(df['age'].mean())interpolate()
功能:插值填充缺失值。
示例:
# 线性插值
df['age'].interpolate()实际应用建议
-
数值型数据:
-
填充均值/中位数:
fillna(df.mean()) -
插值法:
interpolate()
-
-
分类数据:
-
填充众数:
fillna(df.mode()[0]) -
填充特定值:
fillna('Unknown')
-
-
时间序列数据:
-
前向/后向填充:
fillna(method='ffill')或fillna(method='bfill')
-
-
高缺失率数据:
-
考虑删除列:
dropna(axis=1, thresh=len(df)*0.7)(保留至少70%完整数据的列)
-
Pandas 缺失值处理实例
我们先来看一段这样一段整体的代码:
import pandas as pd
"""
缺失值处理方式:
1.数据补齐 2.删除对应数据行 3.不处理
"""
df = pd.read_csv(r"C:\Users\86135\lanzhi\pandass\Pandas库应用实例\数据处理\2.缺失值处理\data.csv",
encoding='gbk',engine='python')
"""
进行逻辑判断,判定空值所在的位置
"""
na = df.isnull()
print(na)
"""
找出空值所在的行数据【逻辑判断+取数】
"""
a=df[na.any(axis=1)]
"""
找出空值所在的列数据
"""
b=df[na[['gender']].any(axis=1)]
c=df[na[['age']].any(axis=1)]
d=df[na[['age', 'gender']].any(axis=1)]
"""
填充缺失值
"""
df1 = df.fillna('1')
"""
删除缺失值【删除整行数据】
"""
df2 = df.dropna()
这段代码展示了使用Pandas处理数据中缺失值的几种方法。我将逐步解释每一部分的功能,为后面介绍具体的数据清洗案例打下坚实基础:
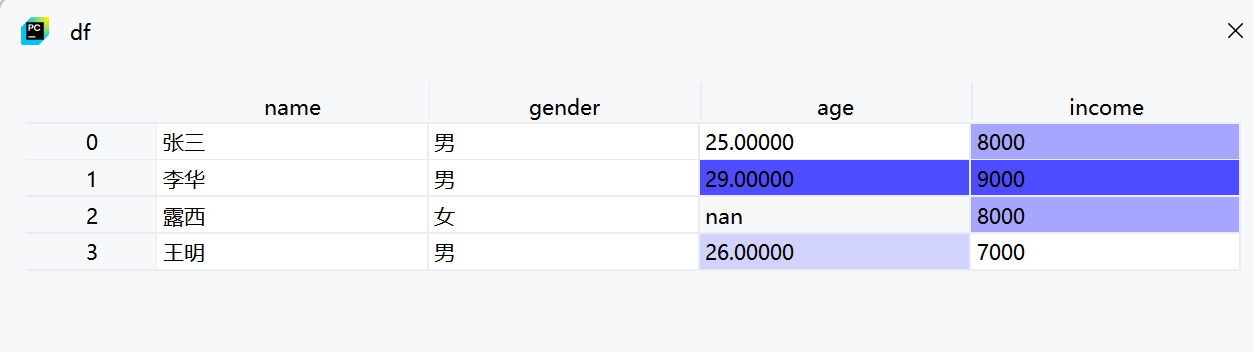
1. 数据读取
df = pd.read_csv(r"C:\Users\86135\lanzhi\pandass\Pandas库应用实例\数据处理\2.缺失值处理\data.csv",
encoding='gbk',engine='python')-
使用
pd.read_csv读取CSV文件 -
encoding='gbk'指定文件编码为GBK(适合中文编码) -
engine='python'指定使用Python引擎解析文件
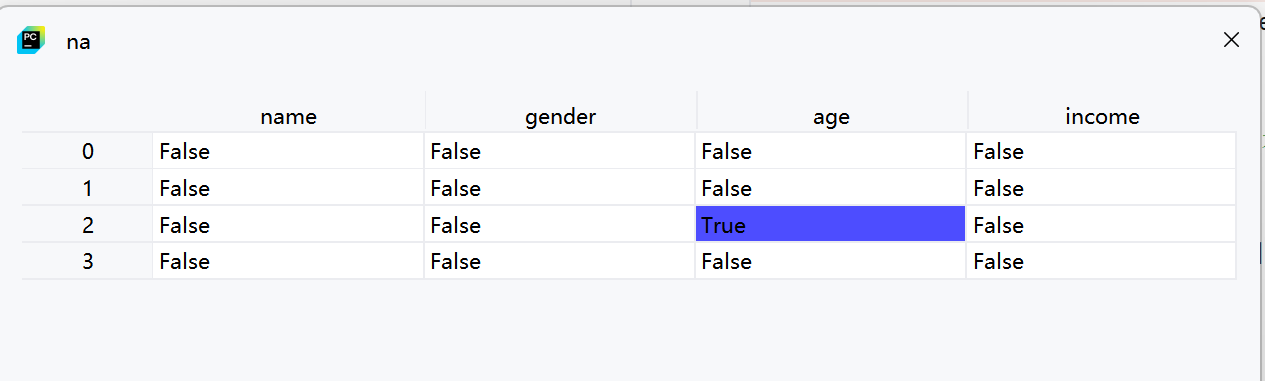
2. 检测缺失值
na = df.isnull()
print(na)-
df.isnull()返回一个与原始DataFrame形状相同的布尔型DataFrame -
True表示该位置是缺失值(NaN),False表示不是
-
打印结果会显示整个DataFrame中每个值是否为缺失值

3. 找出含有缺失值的行
a = df[na.any(axis=1)]-
na.any(axis=1)对每一行进行判断,如果该行有任意一个True(缺失值),则返回True -
df[na.any(axis=1)]筛选出所有含有至少一个缺失值的行

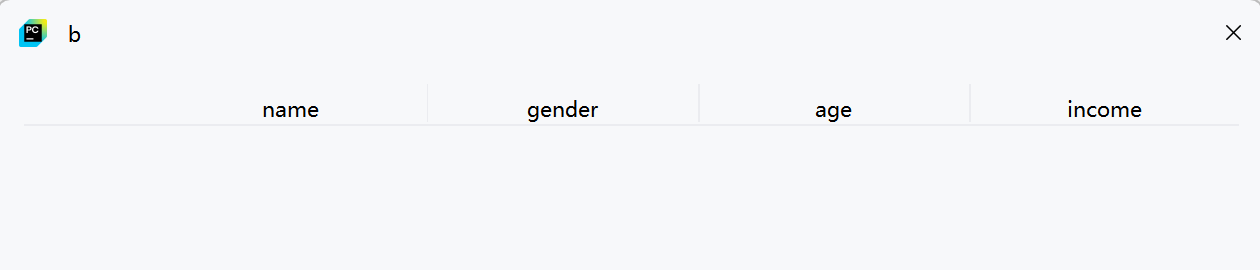
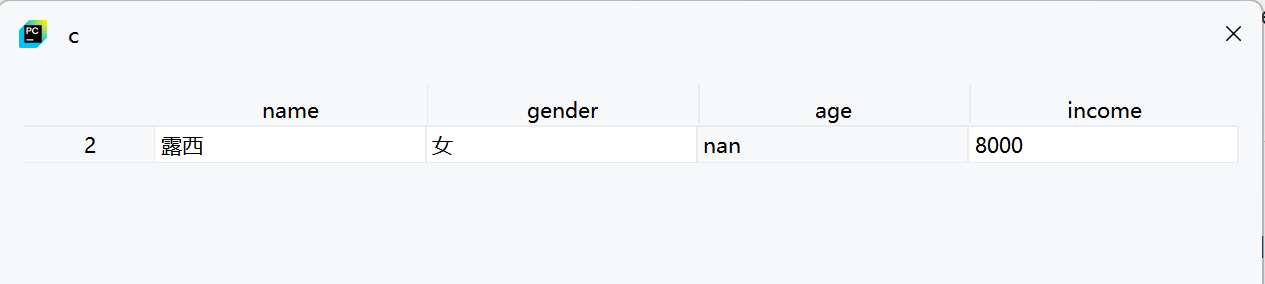
4. 找出特定列含有缺失值的行
b = df[na[['gender']].any(axis=1)] # gender列有缺失值的行
c = df[na[['age']].any(axis=1)] # age列有缺失值的行
d = df[na[['age', 'gender']].any(axis=1)] # age或gender列有缺失值的行-
通过指定列名来检查特定列的缺失值
-
na[['gender']]只选择gender列的缺失值情况 -
.any(axis=1)判断这些列中是否有缺失值


5. 填充缺失值
df1 = df.fillna('1')-
fillna('1')将所有缺失值填充为字符串'1' -
注意:这种方法将所有类型的缺失值都填充为'1',可能不适合数值列
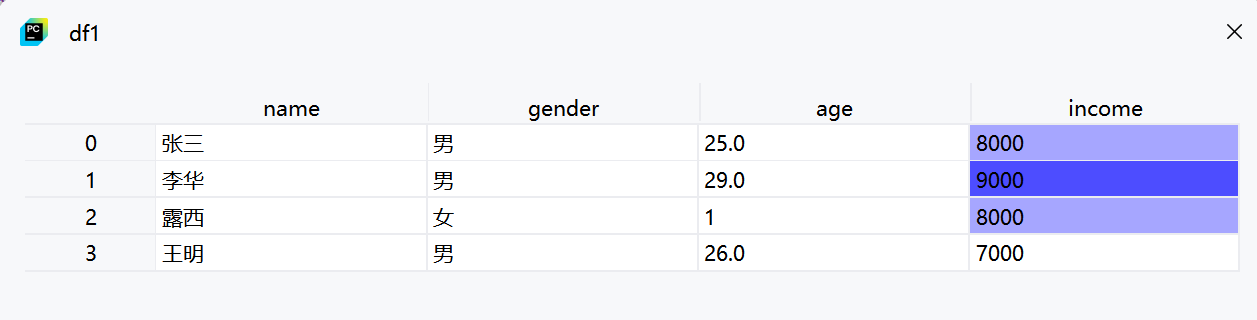
6. 删除含有缺失值的行
df2 = df.dropna()-
dropna()默认删除含有任何缺失值的整行数据 -
结果DataFrame
df2中将不包含任何有缺失值的行
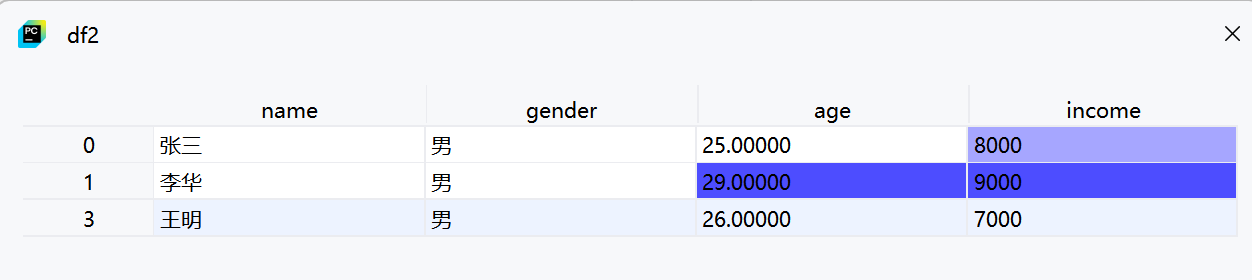
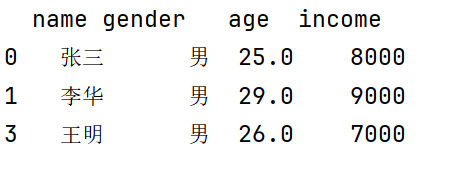
补充说明
实际应用中,缺失值处理需要更细致的方法:
-
数据补齐:可以使用均值、中位数、众数或插值法填充数值列
-
删除数据:对于缺失比例高的列/行可以考虑删除
-
不处理:某些算法可以自动处理缺失值
更完善的填充方法示例:
# 对数值列填充均值
df['age'] = df['age'].fillna(df['age'].mean())
# 对分类列填充众数
df['gender'] = df['gender'].fillna(df['gender'].mode()[0])
















 1418
1418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









