







MQ
背景
随着一个系统的不断壮大,为了完成一个整体功能,我们可能会把它分成几个小模块来完成,但是在大型的分布式应用中,系统间的rpc交互频繁,比如:A调用B,B调用C,C调用D,就会出现下面几个方面的劣势:
系统耦合严重
举个例子:假如系统A要发送数据给系统B和C,发送给每个系统的数据可能有差异,因此系统A对要发送给每个系统的数据进行了组装,然后逐一发送;当代码上线后,新增了一个需求:把数据也发送给D。此时就需要修改A系统,让他感知到D的存在,同时把数据处理好给D。在这个过程中你会看到,每接入一个系统,都要对A系统进行代码改造,开发联调的效率很低。其整体架构如下图:

流量大时容易冲垮
每个接口模块的吞吐能力是有限的,这个上限能力如同堤坝,当大流量(洪水)来临时,容易被冲垮。
例如:积分项目中的抢红包功能,如果这里不做流量限制的话,大量的人同时来抢红吧,我们的系统就有被击垮的风险。
存在性能瓶颈
正如上面说的抢红包功能,假如我们优化代码,增加服务器集群,但是当人足够多的时候还是会到达一个瓶颈的。再举一个直观的例子:
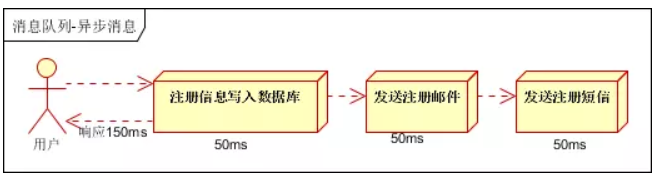
一个注册流程如图所示,那么注册一个用户需要150ms,假设CPU1秒内吞吐量是100次。则串行方式1秒内CPU可处理的请求量是7次(1000/150)
作用
针对上面介绍的一些问题,我们就可以使用MQ做出一些解决方案:
解耦合
我们可以把A中的一些公共的操作抽离出来,封装到一个公共的方法里面。
比如itoo中使用的日志审计功能
削峰
如图所示:

异步

这样注册一个用户需要50ms,假设CPU1秒内吞吐量是100次。则1秒内CPU可处理的请求量是20次(1000/50)
分类

总结
上面只是一个简单的认识与了解,可能有些观点不太正确,欢迎大家指正,一起学习!















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









