






 本文介绍了布隆过滤器的概念、工作原理及其在存储大量元素集合时的优势,包括空间效率和查询速度,同时讨论了其误识别问题和应用场景。
本文介绍了布隆过滤器的概念、工作原理及其在存储大量元素集合时的优势,包括空间效率和查询速度,同时讨论了其误识别问题和应用场景。
【引言】
【简介】
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。
布隆过滤器可以用于检索一个元素是否在一个集合中。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
【工作原理】
我们通过上面的电子邮件的例子来说明工作原理。
假定存储以一亿个电子邮件地址,先建立一个16亿二进制(比特),即两亿字节的向量,然后将这16亿个二进制位全部清零。
对于每一个电子邮件的地址X,用8个不同的随机数产生器(F1,F2.........F8)产生8个信息指纹(f1,f2,......f8)。
在用一个随机数产生器G把这8个信息指纹映射到1-16亿中的8个自然数g1,g2.....g8。现在把这9个位置全部设置为1。对这一亿个电子邮件都这样处理之后,一个针对这些
电子邮件地址布隆过滤器就建成了。
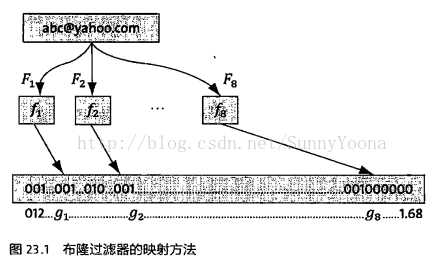
现在,让我们看看如何用布隆过滤器来检测一个可疑的电子邮件地址Y是否是在黑名单中。用相同的8个随机数(F1,F2,....F8)产生器对这个地址产生
8个信息指纹(s1,s2,.....s8),然后将这8个信息指纹对应到布隆过滤器的8个二进制位,分别是t1,t2,....t8。
如果Y在黑名单中,显然,t1,t2,...t8对应8个二进制位一定为1。这样如果再遇到黑名单中的电子邮件地址都能准确的发现。
说白了就是原理很简单,用位数组和k个不同的HASH函数。将HASH函数对应的值的位数组置1,查找时如果发现所有HASH函数对应位都是1说明存在。
【集合表示和元素查询】
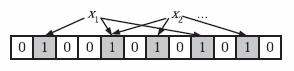
下面我们具体来看布隆过滤器是如何用位数组表示集合的。初始状态时,布隆过滤器是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,布隆过滤器使用k个相互独立的哈希函数(Hash ),它们分别将集合中的每个元素映射到{1,…,m}的范围中。
对任意一个元素x,第i个哈希函数映射的位置h(i,x)就会被置为1(1≤i≤k,代表第i个哈希函数)。
注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。
在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。
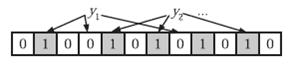
在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有h(i,y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。
下图中y1就不是集合中的元素。y2或者属于这个集合,或者刚好是一个false positive。
【误识别问题】
(引用于数学之美)


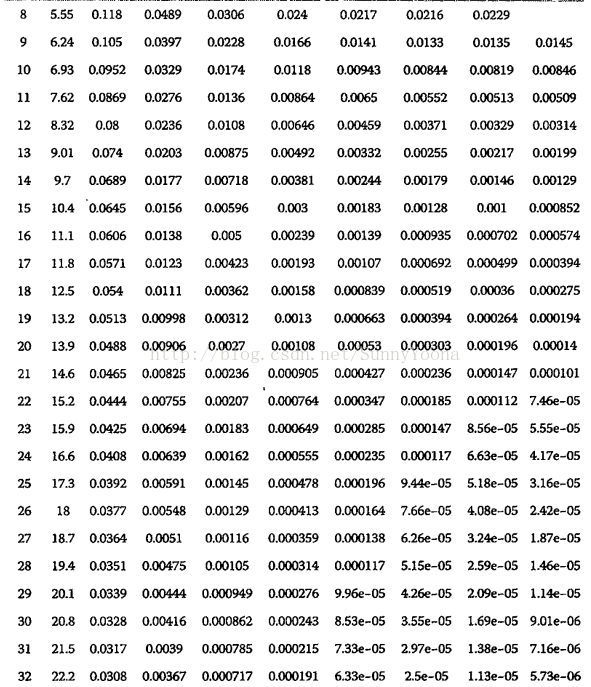
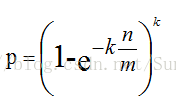
从这个公式可以看出:
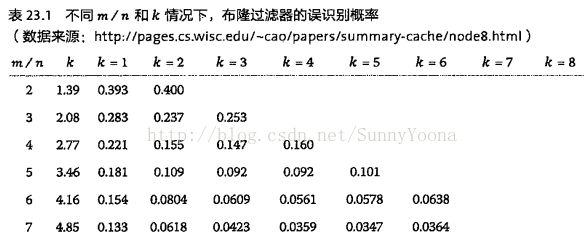
k = ln2 * m / n时 p 最小
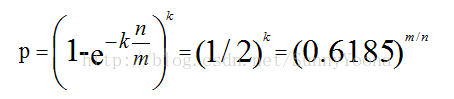
何根据输入元素个数n,确定位数组m的大小及hash函数个数。
当hash函数个数k = ln2 * m / n 时错误率最小。
在错误率p不大于E的情况 下:
推出:
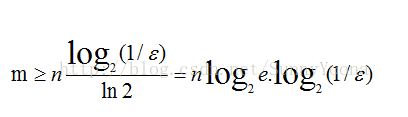
在错误率不大于E的情况 下,m至少要等于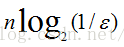
但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应 该大于等于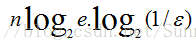
布隆过滤器背后的数学原理在于两个完全随机的数学冲突峰概率很小,因此,可以在很小的无识别率的条件下,用很小的空间存储大量的信息。
【适用范围】
可以用来实现数据字典,进行数据的判重,或者集合求交集


















 634
634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











