







 这篇教程教你如何在没有API接口的网站上抓取数据。通过Chrome浏览器,进入网页,右键检查,选择Network面板。刷新页面找到.json文件,查看网页的JSON网址和User-Agent等关键参数,便于进行网页爬虫操作。
这篇教程教你如何在没有API接口的网站上抓取数据。通过Chrome浏览器,进入网页,右键检查,选择Network面板。刷新页面找到.json文件,查看网页的JSON网址和User-Agent等关键参数,便于进行网页爬虫操作。
爬虫时有些网站没有api接口,需要转换成json格式,这期教程来分享一下,如何获取网页headers和一些参数。只要你有Chrome。
第一步
来到你想爬取的网页,右键选择检查,选择network,如果进去后没有那刷新一下。
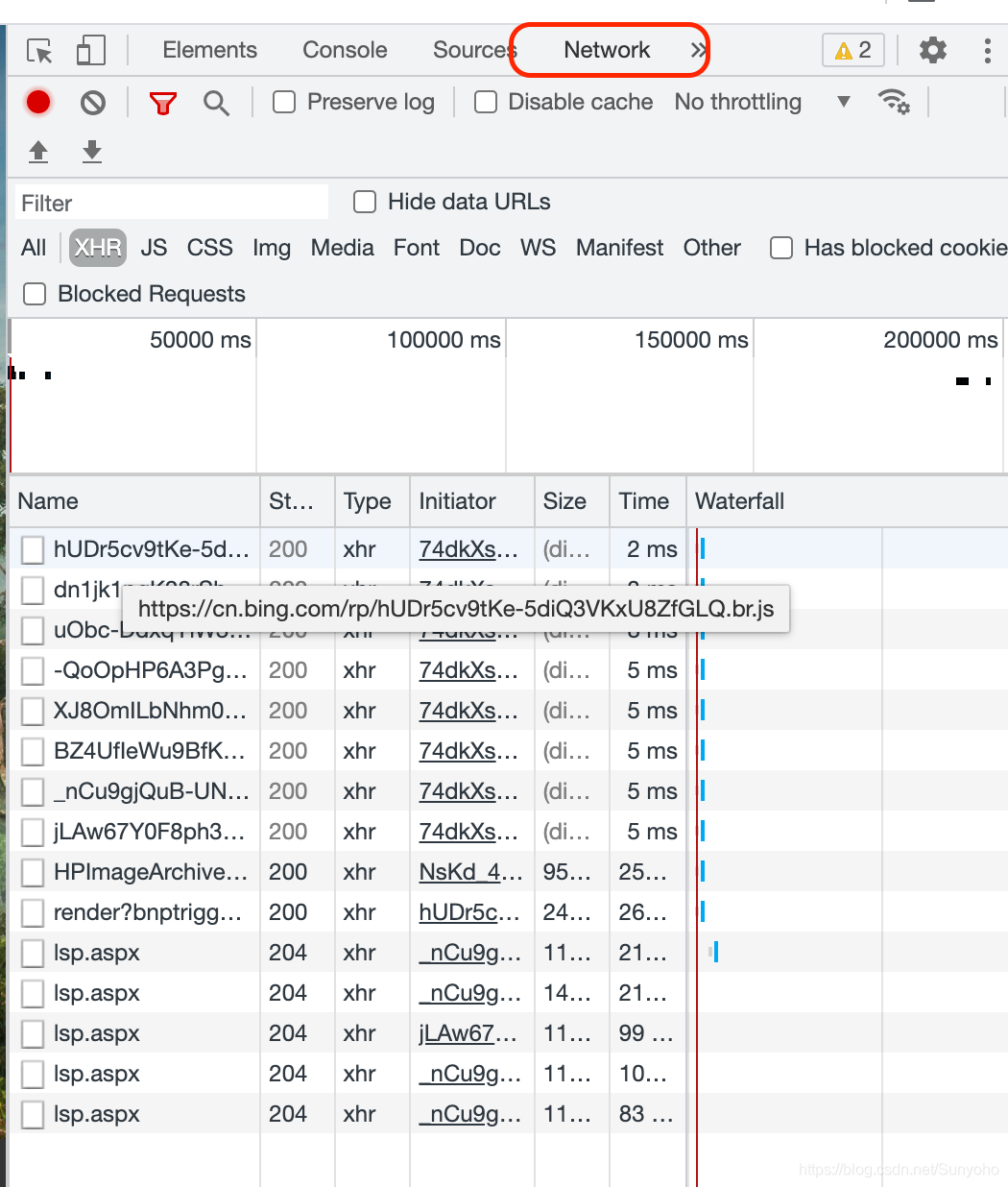
刷新好后,里面会有一个.json结尾的文件,单击他。你就可以看到,网页的json网址。
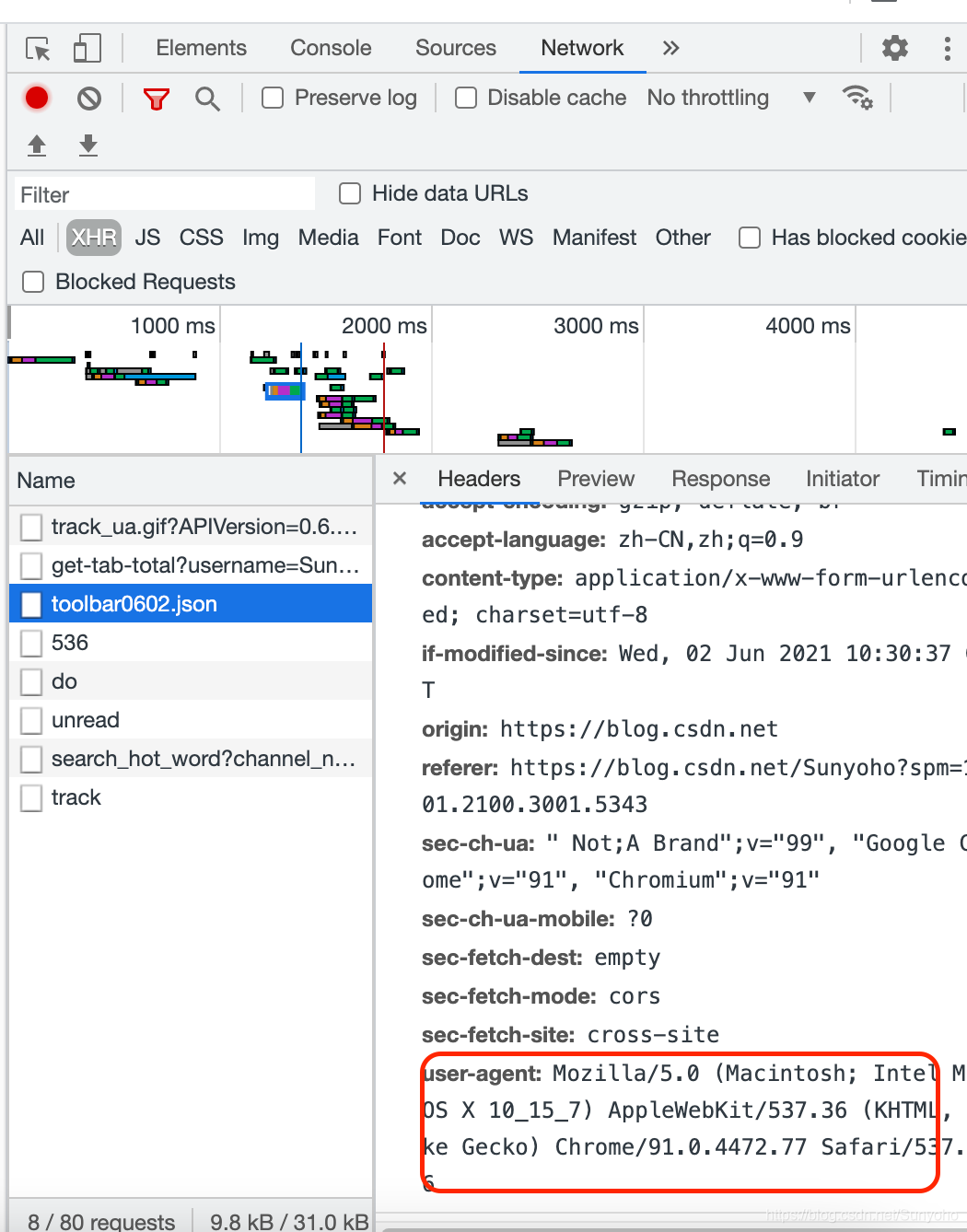
获取User-Agent就往下翻,翻到这。
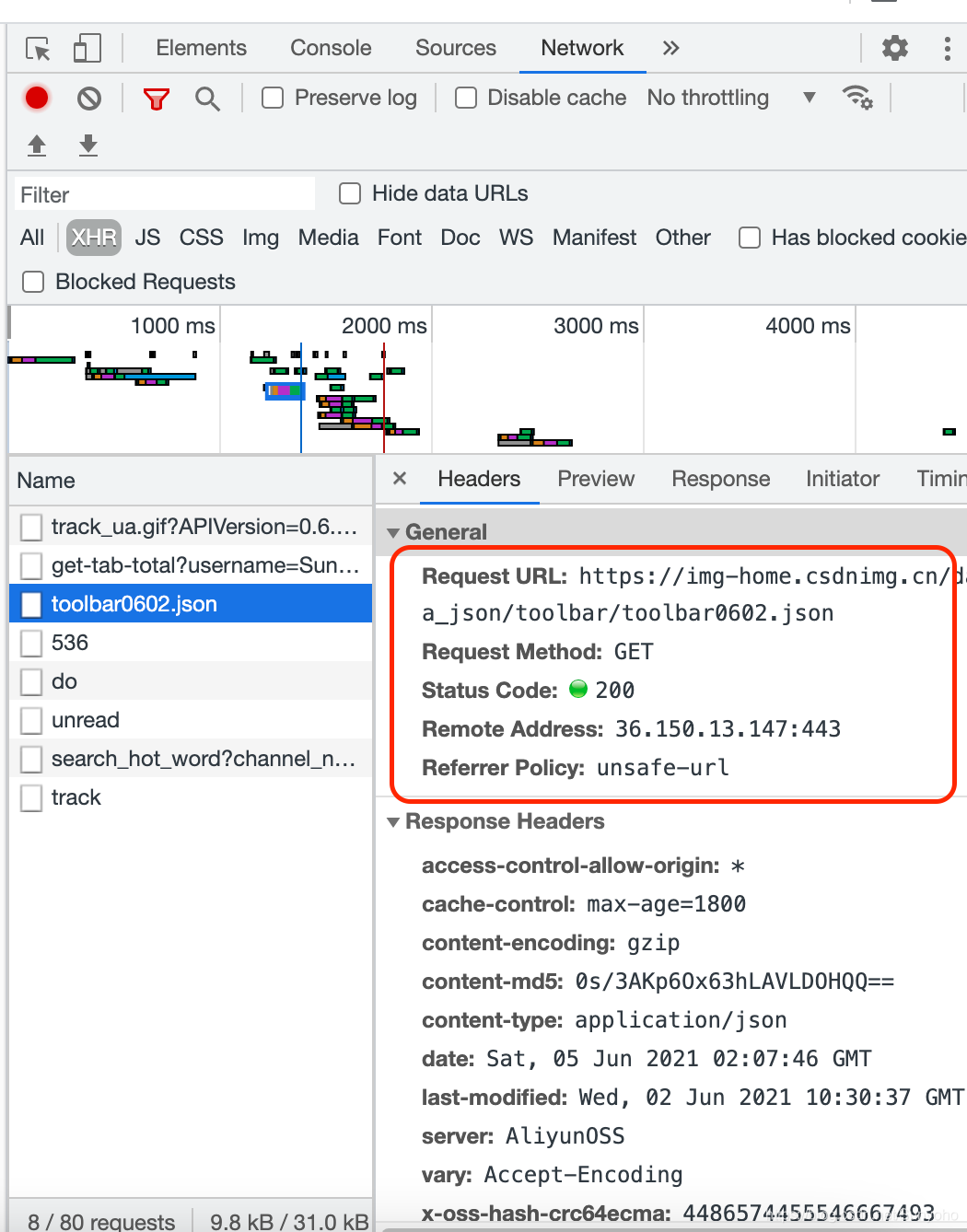
总之,携带的参数都在这个json文件里。
一起学习,一起进步!
爬虫时有些网站没有api接口,需要转换成json格式,这期教程来分享一下,如何获取网页headers和一些参数。只要你有Chrome。
来到你想爬取的网页,右键选择检查,选择network,如果进去后没有那刷新一下。
刷新好后,里面会有一个.json结尾的文件,单击他。你就可以看到,网页的json网址。
获取User-Agent就往下翻,翻到这。
总之,携带的参数都在这个json文件里。
一起学习,一起进步!
 4881
4956
4881
4956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























