






BUAA_OO_2024 第三单元总结
1.1 UML类图+代码架构分析
1.1.1 第一次作业
(一)UML类图

除去要求实现的MyNetwork和MyPerson,我额外设计了两个辅助类BlockManager和TripleManager;具体功能在后面说明~
(二)图维护策略
在本次作业的规格设计中,每个Person关联到若干Acquaintance:public instance model non_null Person[] acquaintance;
这就十分自然地决定了我们的社交网络是一个采用邻接表维护的图。下面根据Network接口总结一下具体需要支持的功能:
isCircle:查询两节点(Person)之间是否存在通路queryBlockSum:查询整个图中"集合"数量queryTripleSum:大意是A.isLinked(B),B.isLinked(C),C.isLinked(A)同时成立即为一个triple
为解决上述问题,我设计了TripleManager和BlockManager两个类,以减轻MyNetwork的负担
TripleManager
字面意思,采用动态维护方式解决queryTripleSum()的问题——这个其实十分简单,不涉及任何算法,每次addRelation和removeRelation时以O(n)时间复杂度即可进行一次维护,具体代码如下
// TripleManager.java
private int count = 0;
public void updateWithAdd(int id1, int id2, HashMap<Integer, Person> personMap) {
for (int id : personMap.keySet()) {
if (id == id1 || id == id2) {
continue;
}
Person p = personMap.get(id);
Person p1 = personMap.get(id1);
Person p2 = personMap.get(id2);
if (p.isLinked(p1) && p.isLinked(p2)) {
count++;
}
}
}
public void updateWithRemove(int id1, int id2, HashMap<Integer, Person> personMap) {
for (int id : personMap.keySet()) {
if (id == id1 || id == id2) {
continue;
}
Person p = personMap.get(id);
Person p1 = personMap.get(id1);
Person p2 = personMap.get(id2);
if (p.isLinked(p1) && p.isLinked(p2)) {
count--;
}
}
}
public int queryTripleSum() {
return count;
}
BlockManager
BlockManager类解决isCircle和queryBlockSum的问题——前者查询两节点是否在同一集合、后者询问集合总数,直觉上想到采用并查集维护;以下是部分核心代码,主要是并查集标志性的find()方法(采用路径压缩)
// BlockManager.java
private int count = 0;
private final HashMap<Integer, Integer> parent = new HashMap<>();
private int find(int id) {
if (parent.get(id) != id) {
parent.put(id, find(parent.get(id)));
}
return parent.get(id);
}
public void addSinglePerson(int id) {
if (parent.containsKey(id)) {
throw new AssertionError("Already have this person!");
}
count++;
parent.put(id, id);
}
public void mergeBlock(int id1, int id2) {
if (id1 == id2 || isInSameBlock(id1, id2)) {
return;
}
count--;
parent.put(find(id1), find(id2));
}
public boolean isInSameBlock(int id1, int id2) {
return find(id1) == find(id2);
}
public int queryBlockSum() {
return count;
}
MyNetwork中,addRelation()调用mergeBlock()(合并集合),isCircle()调用isInSameBlock()(查询);并查集维护允许这两种操作时间复杂度都接近O(1)
但也存在一个问题:~~(至少,我会的)~~并查集并不支持低复杂度的删边操作,所以在删除某个Relation时,不得不进行整个并查集重建——即如下的flush()方法,内部采用深度优先或广度优先进行一次遍历
// BlockManager.java
public void flush(HashMap<Integer, Person> personMap) { // 重建并查集
parent.clear();
count = 0;
for (int id : personMap.keySet()) {
addSinglePerson(id);
}
HashMap<Integer, Boolean> visited = new HashMap<>();
for (int id : personMap.keySet()) {
if (!visited.getOrDefault(id, false)) {
dfs(id, personMap, visited); // 遍历节点, or bfs
}
}
}
private void dfs(Integer curId,
HashMap<Integer, Person> personMap, HashMap<Integer, Boolean> visited) {
visited.put(curId, true);
for (int acqId : ((MyPerson) personMap.get(curId)).getAllAcquaintance()) {
if (visited.getOrDefault(acqId, false)) {
continue;
}
mergeBlock(curId, acqId);
dfs(acqId, personMap, visited);
}
}
至此第一次作业就完成了~
1.1.2 第二次作业
涉及到不少新增的动态维护值,个人看来本次作业难点主要是维护方法略有点费脑子(以及十分容易写出bug)
(一)UML类图
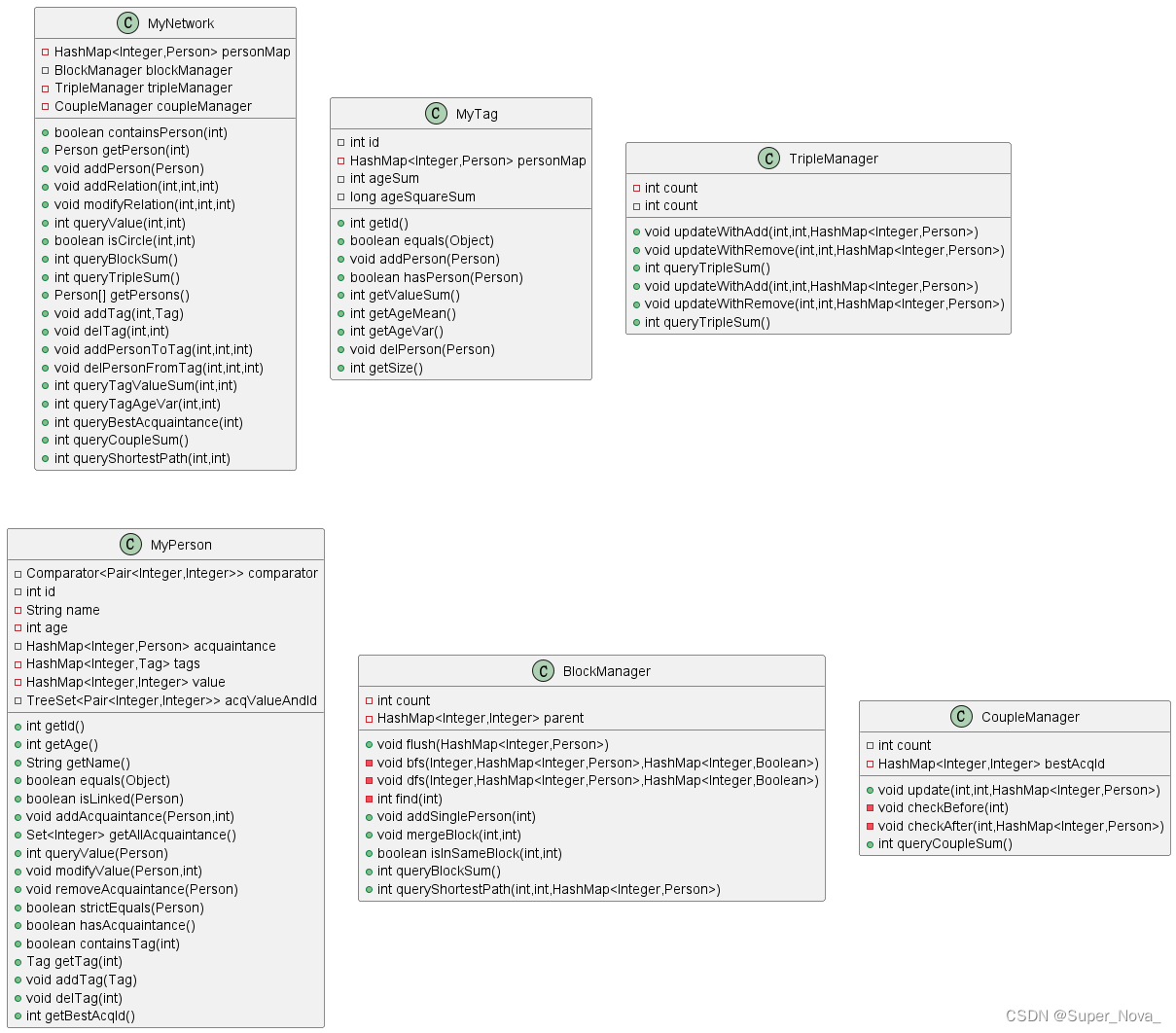
(二)新增需求+维护策略分析
Network.queryShortestPath()
解决图中两节点的最短路问题。由于此最短路问题中边权值均为1,直接利用bfs的性质(优先遍历到最近节点)即可解决——
// BlockManager.java
public int queryShortestPath(int id1, int id2, HashMap<Integer, Person> personMap) {
if (id1 == id2) {
return 0;
}
HashMap<Integer, Integer> distance = new HashMap<>();
Queue<Integer> queue = new LinkedList<>();
queue.add(id1);
distance.put(id1, 0);
while (!queue.isEmpty()) {
int curId = queue.peek();
queue.remove();
for (int acqId : ((MyPerson) personMap.get(curId)).getAllAcquaintance()) {
if (!distance.containsKey(acqId)) {
distance.put(acqId, distance.get(curId) + 1);
if (acqId == id2) {
return distance.get(id2) - 1;
}
queue.add(acqId);
}
}
}
return Integer.MAX_VALUE; // IMPOSSIBLE
}
Network.queryBestAcquaintance() && Network.queryCoupleSum()
所谓couple,即A与B互为BestAcquaintance(value最大);显然,我们还是倾向于进行动态维护
首先是queryBestAcquaintance:MyPerson类内部采用红黑树TreeSet动态维护最大value(value相同,取id最小)的acquaintance;这里手动再实现一个Pair的comparator即可
private final TreeSet<Pair<Integer, Integer>> acqValueAndId = new TreeSet<>(comparator);
private final Comparator<Pair<Integer, Integer>> comparator = (o1, o2) -> {
if (o1.getKey().compareTo(o2.getKey()) != 0) {
return -o1.getKey().compareTo(o2.getKey());
}
return o1.getValue().compareTo(o2.getValue());
};
接下来是如何在新建的CoupleManager类中维护coupleSum:
- 维护时机:addRelation和modifyRelation时
- addRelation前:对Person1和Person2:,比较add前后bestAcq是否变化——若变化则分别count–(《各"切断"一条边》),但如果二人原本为couple,只减一次
- modifyRelation同理(比较add前后bestAcq是否变化)、
到此也不免觉得,第二次作业中新增众多的动态维护value,想到正确的方法还是有点小费脑子的(
MyTag.queryTagValueSum()
对于tagValueSum的动态维护,主要是捋清楚思路上我费了点时间,但回头看又觉得还好?
首先是addPersonToTag()和delPersonFromTag()时:O(n)维护
// MyTag.addPerson(): (delPerson()反之)
for (Person p : personMap.values()) {
valueSum += 2 * p.queryValue(person);
}
addRelation()和modifyRelation()时:O(1)维护
// MyTag.java
public void updateValueSum(Person p1, Person p2, int oldValue, int newValue) {
if (hasPerson(p1) && hasPerson(p2)) {
valueSum += 2 * (newValue - oldValue);
}
}
1.1.3 第三次作业
(一)UML类图

本次作业新增Message类,模拟社交网络中发送短信的行为;本次作业不涉及图算法,难点全在阅读超长JML规格;
本次作业重点放在对规格设计的理解与数据构造策略上——见[1.2.2 规格设计与Junit单元测试](# 1.2.2 规格设计与Junit单元测试)
1.2 单元测试过程
1.2.1 对各类测试的理解
黑箱测试与白箱测试
- 黑箱测试:将待测试的软件系统视为一个黑盒子,只关注系统的输入和输出,而不考虑内部的实现细节;黑箱测试侧重于测试软件是否能完成预期的功能
- 白箱测试:待测试软件对测试者可视——测试人员需要了解系统的源代码、设计文档等内部信息,以便设计测试用例并评估系统的覆盖率和质量。白箱测试侧重于发现系统中的逻辑错误、代码缺陷和性能问题等
单元测试、功能测试、集成测试、压力测试、回归测试
- 单元测试:是指对软件中的最小可测试单元进行检查和验证。至于“单元”的大小或范围,并没有一个明确的标准,“单元”可以是一个函数、方法、类、功能模块或者子系统。单元测试通常和白盒测试联系到一起
- 功能测试:字面意思(),通常与黑盒测试相关联
- 集成测试:在单元测试的基础上,将所有模块按照设计要求(如根据结构图)组装成为子系统或系统,进行集成测试
- 压力测试:向软件系统加压,观测软件在极限数据下的运行情况;目的一般是测试软件性能缺陷;hw10中strong10测试点采用qtvs饱和轰炸就是压力测试的典型(问就是我挂了)
- 回归测试:是指修改了旧代码后,重新进行此前已通过的测试,以确认修改未引入新的Bug——在OO的Bug修复阶段采用的就是回归测试!
1.2.2 规格设计与Junit单元测试
本单元的作业中新增Junit黑盒测试数据点,考察我们针对特定方法,结合JML规格构造相应测试数据——说白了,我们构造的测试数据点只要忠实地、面面俱到地翻译JML的具体要求即可。恰恰是我们基于JML规格实现Junit单元测试的便捷性,决定了Junit在检验代码实现与规格一致中的突出作用!!!
比如在homework11中,要求实现deleteColdEmoji()的Junit单元测试,其中部分JML规格约束如下:
@ ensures (\forall int i; 0 <= i && i < \old(messages.length);
@ (\old(messages[i]) instanceof EmojiMessage &&
@ containsEmojiId(\old(((EmojiMessage)messages[i]).getEmojiId())) ==> \not_assigned(\old(messages[i])) &&
@ (\exists int j; 0 <= j && j < messages.length; messages[j].equals(\old(messages[i])))));
@ ensures (\forall int i; 0 <= i && i < \old(messages.length);
@ (!(\old(messages[i]) instanceof EmojiMessage) ==> \not_assigned(\old(messages[i])) &&
@ (\exists int j; 0 <= j && j < messages.length; messages[j].equals(\old(messages[i])))));
最开始我卡在case8与case9,一个重要原因就是注意力集中在输出是否正确,忽视了是否满足invariant/constraint的约束条件;因此后面加入了类似如下的代码,通过测试:
// NetworkTest.java
Message[] allMessagesBefore = network.getMessages();
network.deleteColdEmoji(3);
Message[] allMessagesAfter = network.getMessages();
for (Message msg : allMessagesBefore) {
if (!(msg instanceof EmojiMessage) || network.queryPopularity(((EmojiMessage) msg).getEmojiId()) >= 3) {
assertTrue(Arrays.asList(allMessagesAfter).contains(msg));
}
}
for (Message msg : allMessagesAfter) {
assertTrue(Arrays.asList(allMessagesBefore).contains(msg));
}
有趣的一点:课程网站上声明
getMessages是浅拷贝,但经过以最终0提交次数为代价的若干次《大胆》尝试验证,黑盒代码中的getMessages似乎都是深拷贝——否则上面一段代码显然是毫无意义的
1.2.3 数据构造策略补充
在自测、互测中进行白箱测试时,还可以有针对性地进行压力测试,比如针对某些复杂度不合理的实现方法进行高压数据点hack(如下1.3 性能问题分析中的queryTagValueSum())
1.3 性能问题分析
1.3.1 性能Bug分析
最初提交强测的homework10中,本人遭到了来自strong10qtvs过饱和轰炸的小小压力测试震撼:
...
qtvs 114514 1919810
qtvs 114514 1919810
qtvs 114514 1919810
qtvs 114514 1919810
qtvs 114514 1919810
...
本人十分致命地在queryTagValueSum()中采用了O(N2)暴力算法,事实上这是进行简单的复杂度估算是完全可以避免的错误:
- 一个tag最多1111人,约合103;
- 最坏情况下,qtvs最多进行105次,总的计算次数已达103*103*105=1011,十分危险!
因此最后Bug修复阶段还是采用了动态维护的方式;
这里也能总结一点教训:切忌感性分析时间开销——原来我在*《直觉上》*觉得动态维护计算量不一定比直接算小,但这种《直觉》哪怕正确也无法确保通过压力测试!
1.3.2 关于规格设计与实现的分离
如上案例十分鲜明地体现了何谓将规格设计与具体实现分离开来——
- 规格设计上,为了明确表述需求、方便后续编写测试,采取逻辑上最简单的方法表述是合理的;
- 而对于具体实现,除了满足正确性需求,还必须在可读性、整体架构、尤其是性能上统筹兼顾;此时直接翻译JML规格恐怕就会在评测中出现如上CTLE的尴尬情形
1.4 心得体会
- 本单元中,我初步认识了契约式设计的思维,在阅读浩如烟海的JML规格设计中充分锻炼了自己规格化设计的能力;与此同时,在新增的Junit黑盒测试数据点中,学会了如何忠实地利用设计规格生成测试数据
- 与此同时,本单元作业围绕模拟社交网络这一主题,让我得以了解常用的图算法;特别是从中进一步加强了在不同的实现策略上,通过估计时间开销,实现性能与代码复杂度、可读性之间的权衡















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









