






Redis是一款内存高速缓存数据库,客户端访问web端时,php直接访问MYSQL数据库速度不是很快,这时redis可以作为MYSQL的缓存,他把mysql的数据缓存在内存中,而不是磁盘中,所以redis的查询速度更快。
Redis-非关系型数据库:不是关系型模型为基础构建的数据库
基于缓存,速度快;支持多种数据结构
消耗内存相对较少,支持数万的QPS(查询请求)
支持持久化存储,可以把数据放在内存,也可以存储在磁盘
MYSQL还是要用的,因为大多数的数据都还是有关联的,Reids做不了,并且Reids有可能丢失数据
关系型数据库优点:
- 保证数据的一致性和原子性;
- 数据更新的开销很小(因为是按行匹配);
- 进行负责处理(跨库跨表);
- 存在较多成熟案例和模板信息;
关系型数据库缺点:
- 大量的数据写入(数据都是要经过内存放在磁盘内,IO很慢);
- 表结构的变更(比如要在表中添加一个新列表,因为是按行写入,要一行一行的写,很占资源;所以在关系型模型中一般在建立表的时候会提前创建一些新列表中的字段,用来改名,这样消耗资源远远小于创建新字段)
- 查询速度(redis的QPS可以达到数万,QPS是每秒查询率;因为他的数据会放在内存里;数据之间没有关联;MYSQL不可能)
- 集群化的难度(MYSQL有状态的集群化是非常难实现的)
NOSQL(是一类数据库):弥补关系型数据库的不足,种类有200多种,每一种都有自己的特性,Redis是其中的一种
NOSQL类数据库的优点:
- 易于数据分散、数据间相对独立、没有关联
- 提升性能和扩展,是水平扩展的解决方案
- 速度较快,绝大多数数据存储在内存中
NOSQL的分类:
- 面向键值的数据库:处理速度较快,因为数据间没关联;以k/v结构存储数据:k--zhangsan_home v(值)--“北京市昌平区”
存储时有三类:临时存储--通过内存保存数据(memcache)
永久存储--通过硬盘保存数据(flar、rona)
临时+永久存储--数据放在内存里当索引,特定情况下把数据转储在磁盘里(Reids)
- 面向表的数据库:把数据插入在表中,但是和RDBMS有区别;不定义表结构,支持复杂的查询条件(mangodb)
- 面向列的数据库:mysql,redis都是面向行的数据库,都是按行索引;这里是面向列(hbash)
面向行的数据库:对少量行进行读取和更新时速度较快
面向列的数据库:对大量行进行读取时,速度较快,对所有行的特定列进行同时更新时速度较快
Reids的安装
- 安装编译环境:yum install -y gcc gcc-c++ tcl
- 把redis软件包拉到Linux中
- 解压redis压缩包:tar -zxvf redis-3.2.12.tar.gz
- 进入redis目录:make;make test(测试当前环境是否满足redis的运行)
- make PREFIX=/usr/local/redis install(指定安装路径)
- 手动拷贝配置文件:cd /usr/local/redis/ cp -a /root/redis-3.2.12/redis.conf .
- 启动redis:/usr/local/redis/bin/redis-server /usr/local/redis/redis.conf
配置文件/usr/local/redis/redis.conf:
redis默认是前台进程,把它放到后台
查看服务是否打开:netstat -antp | grep :6379
连接:/usr/local/redis/bin/redis-cli
bind指定redis绑定在哪一个网卡上
安全模式:起到一个安全保护的目的,如果开启就必须配置bind ip 或者是访问密码才允许访问;如果没有修改绑定的ip,没有给redis一个访问密码的话,就不允许远程用户过来连接;只能自己访问自己
客户端如果多长时间没有发出指令,就被server主动断开;一般来说会设为0,redis是给php用的,而不是给客户访问的
server端每多长时间向客户端发起一个ick的请求,检测客户端是否存活;默认就可以
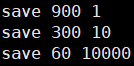
如果在900s内,有一个键值发生变化,那么就执行save命令,把内存里的数据保存到磁盘里
如果在300s内,有十个键值发生变化,那么就执行save命令,把内存里的数据保存到磁盘里
如果在300s内,有一万个键值发生变化,那么就执行save命令,把内存里的数据保存到磁盘里
开启了RDB快照功能(把内存数据转储为RDB文件,后期可以通过RDB文件恢复数据)如果rdb备份过程中存储失败,当前数据库停止写请求
RDB文件是否允许压缩
RDB文件名称,就用它恢复数据
当前数据库会从哪个目录下会找RDB文件,一般写/usr/local/redis
- 主从同步:
2.6版本后,redis 从服务器默认只读
redis的数据库密码(没有用户)
最大并发量,如果超过限制,就会返回给客户端报错
redis能够调用的最大的内存
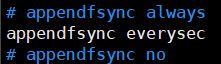
是否开启aof
aof文件名称
redis持久化由两部分构成:RDB文件和AOF
客户端给服务器给数据,数据会在客户端内存中发送给服务器内存中,服务器端再去调用系统命令,把数据往磁盘里写;如果过程中内存往硬盘里存储出现了错误,那么rdb文件就没有了;所以用AOF机制,它会把写入的命令通过一个单独的线程追加到文件中,只要有修改就写到文件中。RDB是延时的,全量备份,恢复速度快,较容易丢失;AOF是即时的,增量备份,恢复速度慢,不容易丢失;这两个一起使用会比较好的保障数据库的数据稳定。AOF一般不开启,不然并发量会明显下降,因为写入数据时同时向文件中写入命令。
always 每次写入数据时要执行一次sync;no 每次写入数据时等数据量达到一定地步时执行sync,everysec 每秒执行一次
sync的默认重写策略,如果有新的写入操作,不去执行sync,所有的数据先放在内存里,等数据重写数据完成后,再保存到磁盘
远程连接:/usr/local/redis/redis-cli -h localhost -p 6379 -a 指定密码
[root@localhost ~]# redis-cli -h 192.168.66.11 -p 6379
192.168.66.11:6379>
#代表可以远程访问,可以在配置文件中bind里修改服务器地址ln -s /usr/local/redis/bin/* /usr/local/bin/:连接数据库
redis主从同步:备份数据
- 原理:
1.从服务器向主服务器发送一个SYNC。
2.主服务器接收SYNC指令,然后执行BGSAVE命令生成RDB文件,并且使用缓存区记录执行命令。
3.主服务器发送一个快照给从服务器并且记录缓存命令
4.从服务器接收快照,丢弃旧数据,载入快照
5.主服务器然后向从服务器发送缓存命令
6.从服务器然后接受主服务器的命令,并执行来自缓冲区的写入命令。
- 从服务器打开配置文件:vim redis/redis.conf
bind 192.168.66.12
daemonize yes
dir /usr/local/redis
slaveof 192.168.66.11 6379 #指定主服务器地址
masterauth 123456 #指定主服务器密码
redis集群:(最少6个)
让客户端访问更多的redis,实现高并发;有多台主redis,多台slave,每个主redis都会绑定一个slave,如果主redis宕机了,slave就会变成主redis,master和slave要建立主从关联,master1和slave1数据一致,master2和slave2数据一致;和实现了真正的分布式存储;如果其中一个主死亡,并不会让集群丢失,而且会让slave顶替主redis;
自动切换;水平扩容;自动化迁移(自动分配槽位)
虽然都是master节点,但是他们保存的数据都是不一样的,利用一种算法,把key放进去就会得出一个从0-16383的一个值
比如:name---wangyang,先把name放到算法内,得到一个值,就放到对应的master里存储,每个master都有一个值的范围;
- 实验准备:
6379是主redis 6378是slave备份
- 构建redis环境
1.三台主机都部署redis,每台主机部署两个redis,把redis的目录都放在/data下,一个叫6379,一个叫6378
启动前优化内存:echo 'vm.overcommit_memory=1' >>/etc/sysctl.conf && sysctl -p
启动服务:redis-server /user/local/redis/conf/redis.conf & 测试:redis-cli
2.构建redis-cluster集群:
创建两个redis的目录:mkdir -p /data/{6378,6379}
把配置文件放到/data/redis/6378和6379下:cp /root/redis-3.2.12/redis.conf /data/6378/;
配置redis.conf文件:配置6378,也要配置6379(把6378改成6379即可)
把配置文件传给12和13主机上,实现和11主机一样的环境:
scp -r /usr/local/redis/ root@192.168.66.12:/usr/local/;scp -r /usr/local/redis/ root@192.168.66.13:/usr/local/
把redis目录传到12和13主机上:
scp -r /data/ root@192.168.66.12:/data/;scp -r /data/ root@192.168.66.13:/data/
为了方便调用可以给12和13设置:ln -s /usr/local/redis/bin/* /usr/local/bin/
启动redis进程:redis-server /data/6378/redis.conf ;redis-server /data/6379/redis.conf
- 创建redis cluster集群,因为集群化初始化工具是通过ruby语言写的,所以要安装ruby环境,而且需要ruby环境安装redis需要的依赖包:
连通公网:ifup eth1
安装ruby环境:yum install ruby rubygems -y
使用ruby的源:gem sources --add http://mirrors.aliyun.com/rubygems/ --remove http://rubygems.org/
通过ruby安装reids:gem install redis -v 3.3.3
创建一个包含三个主节点和三个从节点的集群:cp /root/redis-3.2.12/src/redis-trib.rb /usr/local/redis/bin/
初始化:/usr/local/redis/bin/redis-trib.rb create --replicas 1 192.168.66.11:6378 192.168.66.11:6379 192.168.66.12:6378 192.168.66.12:6379 192.168.66.13:6378 192.168.66.13:6379
- create:创建一个新的集群
- replicas:每个主节点创建一个从节点
M是master,S是slave,slots是槽位
连接测试:redis-cli -c(通过集群模式连接)-p 6378 -h 192.168.66.11
查看当前槽位关系:cluster keyslot key
查看槽点和节点对应关系:cluster slots
这时候就可以用redis-cluster的集群了
创建:set msg 'yangqimin'
分配了8303槽位,放在了12主机的6378节点
11的6378节点是空的,因为放在了12的6378
安装 MySQL 数据库进行协同测试,redis的数据都是从mysql中获取来的
- 准备一台机器安装mysql,往进写入数据:
给mysql远程调取权限:
- 用11机器创建一个脚本:把mysql数据写到redis里
给11主机做密钥认证:ssh-keygen -t rsa;ssh-copy-id root@192.168.66.14
给脚本加运行权限:chmod a+x mysql-to-redis.sh



















 1647
1647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









