







目录
3.1 实现自定义Partitioner-MyPartitioner.java
1.复习MapReduce的8个步骤

2.MapReduce中的分区
在MapReduce中, 通过我们指定分区, 会将同一个分区的数据发送到同一个 Reduce 当中进行处理。例如: 为了数据的统计, 可以把一批类似的数据发送到同一个 Reduce 当中, 在同一个Reduce 当中统计相同类型的数据, 就可以实现类似的数据分区和统计等 其实就是相同类型的数据, 有共性的数据, 送到一起去处理。
Reduce 当中默认的分区只有一个。包括我们上次写的wordcount案例,都是一个分区一个reduce。
2.1 新需求:需要分别reduce

3.IDEA实现分区-JAVA
3.1 实现自定义Partitioner-MyPartitioner.java
主要的逻辑就在这里, 这也是这个案例的意义, 通过 Partitioner 将数据分发给不同的 Reducer
package com.ucas.mapredece;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author GONG
* @version 1.0
* @date 2020/10/9 15:44
*/
public class MyPartitioner extends Partitioner<Text, LongWritable> {
/*
Text:表示K2
LongWritable:表示V2
i:表示reduce的个数
*/
@Override
public int getPartition(Text text, LongWritable longWritable, int i) {
//如果单词长度大于等于5,进入第一分区,否则进入第二分区
if (text.toString().length() >= 5) {
return 0;
} else {
return 1;
}
}
}
3.2 设置主函数:定义分区+设置分区数目
package com.ucas.mapredece;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.conf.Configured;
public class JobMain extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf(), JobMain.class.getSimpleName());
//打包到集群上面运行时候,必须要添加以下配置,指定程序的main函数
job.setJarByClass(JobMain.class);
//第一步:读取输入文件解析成key,value对
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://192.168.0.101:8020/wordcount"));
//第二步:设置我们的mapper类
job.setMapperClass(WordCountMapper.class);
//设置我们map阶段完成之后的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//第三步,第四步,第五步,第六步
//第三步:设置分区规则
job.setPartitionerClass(MyPartitioner.class);
//第七步:设置我们的reduce类
job.setReducerClass(WordCountReducer.class);
//设置我们reduce阶段完成之后的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//两个分区用到两个reduce,设置reduce个数
job.setNumReduceTasks(2);
//第八步:设置输出类以及输出路径
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.101:8020/wordcount_out"));
//上面那个路径时不允许存在的,会帮我们自动创建这个文件夹
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
/**
* 程序main函数的入口类
*
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Tool tool = new JobMain();
int run = ToolRunner.run(configuration, tool, args);
System.exit(run);
}
}
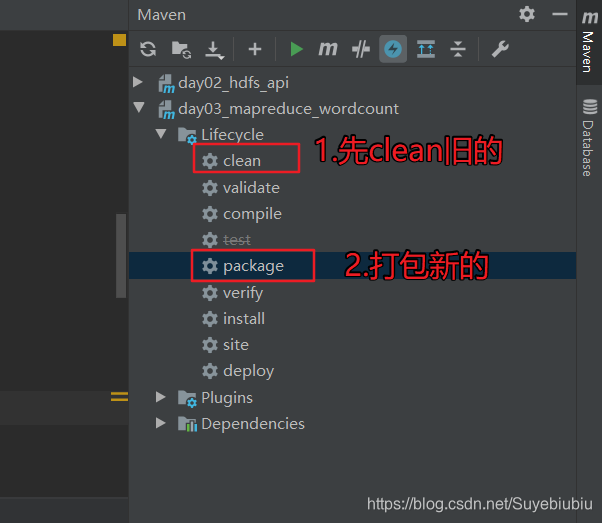
3.3 打成jar包
先clean一下以前的东西,再双击packet打包
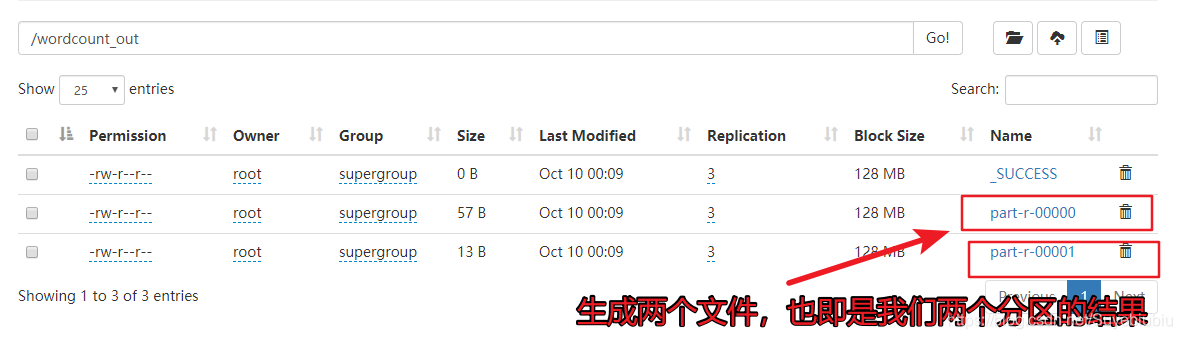
4.运行并且查看结果
将jar发送到node01中的 /export/software
进入:cd /export/software
运行命令:hadoop jar day03_mapreduce_wordcount-1.0-SNAPSHOT.jar com.ucas.mapredece.JobMain
[root@node01 software]# hadoop jar day03_mapreduce_wordcount-1.0-SNAPSHOT.jar com.ucas.mapredece.JobMain
2020-10-10 00:08:46,441 INFO client.RMProxy: Connecting to ResourceManager at node01/192.168.0.101:8032
2020-10-10 00:08:47,468 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1602247634978_0002
2020-10-10 00:08:47,823 INFO input.FileInputFormat: Total input files to process : 1
2020-10-10 00:08:47,990 INFO mapreduce.JobSubmitter: number of splits:1
2020-10-10 00:08:48,052 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
2020-10-10 00:08:48,342 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1602247634978_0002
2020-10-10 00:08:48,345 INFO mapreduce.JobSubmitter: Executing with tokens: []
2020-10-10 00:08:48,636 INFO conf.Configuration: resource-types.xml not found
2020-10-10 00:08:48,636 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2020-10-10 00:08:48,757 INFO impl.YarnClientImpl: Submitted application application_1602247634978_0002
2020-10-10 00:08:48,835 INFO mapreduce.Job: The url to track the job: http://node01:8088/proxy/application_1602247634978_0002/
2020-10-10 00:08:48,836 INFO mapreduce.Job: Running job: job_1602247634978_0002
2020-10-10 00:09:00,140 INFO mapreduce.Job: Job job_1602247634978_0002 running in uber mode : false
2020-10-10 00:09:00,156 INFO mapreduce.Job: map 0% reduce 0%
2020-10-10 00:09:10,638 INFO mapreduce.Job: map 100% reduce 0%
2020-10-10 00:09:18,756 INFO mapreduce.Job: map 100% reduce 50%
2020-10-10 00:09:19,772 INFO mapreduce.Job: map 100% reduce 100%
2020-10-10 00:09:25,853 INFO mapreduce.Job: Job job_1602247634978_0002 completed successfully
2020-10-10 00:09:26,115 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=203
FILE: Number of bytes written=647888
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=185
HDFS: Number of bytes written=70
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Job Counters
Launched map tasks=1
Launched reduce tasks=2
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=7940
Total time spent by all reduces in occupied slots (ms)=11782
Total time spent by all map tasks (ms)=7940
Total time spent by all reduce tasks (ms)=11782
Total vcore-milliseconds taken by all map tasks=7940
Total vcore-milliseconds taken by all reduce tasks=11782
Total megabyte-milliseconds taken by all map tasks=8130560
Total megabyte-milliseconds taken by all reduce tasks=12064768
Map-Reduce Framework
Map input records=4
Map output records=12
Map output bytes=167
Map output materialized bytes=203
Input split bytes=114
Combine input records=0
Combine output records=0
Reduce input groups=9
Reduce shuffle bytes=203
Reduce input records=12
Reduce output records=9
Spilled Records=24
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=279
CPU time spent (ms)=2730
Physical memory (bytes) snapshot=604041216
Virtual memory (bytes) snapshot=7283023872
Total committed heap usage (bytes)=318500864
Peak Map Physical memory (bytes)=364597248
Peak Map Virtual memory (bytes)=2409140224
Peak Reduce Physical memory (bytes)=122572800
Peak Reduce Virtual memory (bytes)=2436947968
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=71
File Output Format Counters
Bytes Written=70
[root@node01 software]#

















 494
494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









