







一、为什么使用连接池
实际开发中”获得连接“或”释放资源“是非常消耗系统资源的两个过程,为了解决此类性能问题,通常情况我们采用连接池技术,来共享连接connection。
二、连接池概述
1.概念
用池来管理Connection,这样可以重复使用Connection。有了池,所以我们不用自己来创建Connection,而是通过池来获取Connection对象。当使用完Connection后,调用Connection的close()方法也不会真的关闭Connection,而是把Connection“归还”给池。池就可以再利用这个Connection对象了。

2.规范
java为数据库连接池提供了公共的接口:javax.sql.DataSource,各个厂商需要让自己的连接池实现这个接口。这样应用程序可以方便的切换不同厂商的连接池。
常见的连接池: DBCP、C3P0。
三、C3P0连接池
c3p0开源免费的连接池,目前使用它的开源项目有:Spring、Hibernate等。使用第三方工具需要导入jar包,c3p0使用时还需要添加配置文件c3p0-config.xml

配置文件
-
- 配置文件名称:c3p0-config.xm(固定)
- 配置文件位置:src (类路径)
- 配置文件内容:命名配置

配置文件内容:默认配置

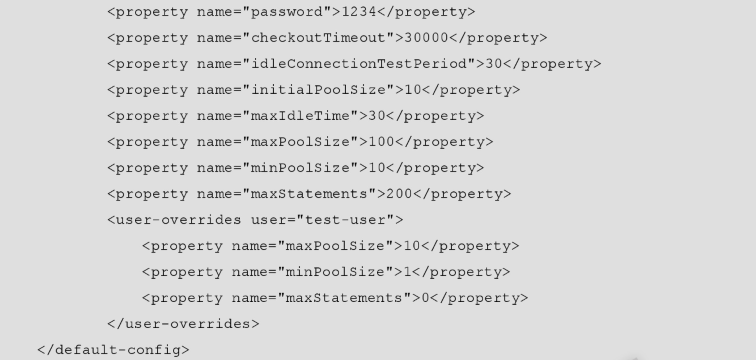
常见配置项
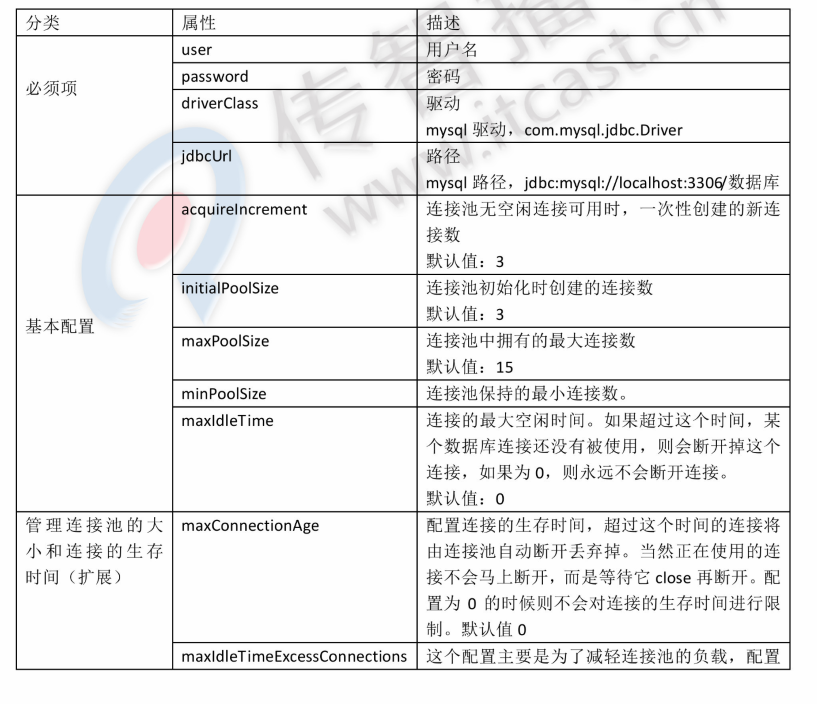
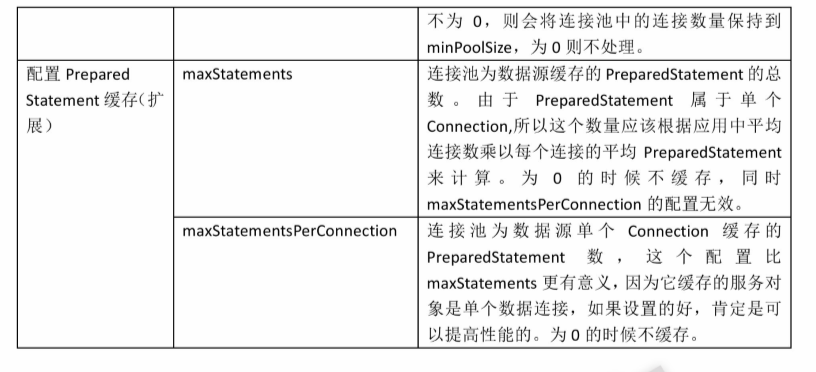
C3P0连接池的使用
第一步:引入C3P0连接池的jar包
第二步:编写代码
*手动餐设置参数
*配置文件设置参数
C3P0改造工具类
public class JDBCUtils2 {
//使用默认配置
//private static final ComboPooledDataSource DATA_SOURCE =new ComboPooledDataSource();
//使用命名配置
private static ComboPooledDataSource dataSource = new ComboPooledDataSource("itcast");
/**
* 获得连接的方法
*/
public static Connection getConnection(){
Connection conn = null;
try {
conn = DATA_SOURCE.getConnection();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return conn;
}
...
四、使用DBUtils增删改查的操作
1.案例分析
如果只使用JDBC进行开发,我们会发现冗余代码过多,为了简化JDBC开发,使用DBUtils可以有效解决这一问题。
DBUtils就是JDBC的简化开发工具包。需要使用技术:连接池(获得连接),SQL语句
2.概述
DBUtils是java编程中的数据库操作使用工具。
DBUtils封装了对JDBC的操作,简化了JDBC操作。
DBUtils三个核心功能介绍
QueryRunner中提供对sql语句操作的API
ResultSetHandler接口,用于定义select操作后,怎样封装结果集
DBUtils类,它就是一个工具类,定义了关闭资源与事务处理的方法
QueryRunner核心类
QueryRunner(DataSource ds),提供数据源(连接池),DBUtils底层自动维护连接connection
update(String sql,Object... params),执行更新数据
query(String sql,ResultSetHander<T> rsh,Object... params),执行查询
ResultSetHandler结果集处理类
DBUtils
提供了一个接口
ResultSetHandler
,它就是用来
ResultSet
转换成目标类型的工具。你可以自己去实现这个接口,把
ResultSet
转换成你想要的类型。
DBUtils
提供了很多个
ResultSetHandler
接口的实现,这些实现已经基本够用了,我们通常不用自己去实现
ResultSet
接口了。
-
MapHandler :单行处理器!把结果集转换成 Map<String,Object> ,其中列名为键!
-
MapListHandler :多行处理器!把结果集转换成 List<Map<String,Object>> ;
-
BeanHandler :单行处理器!把结果集转换成 Bean ,该处理器需要 Class 参数,即 Bean 的类型;
-
BeanListHandler :多行处理器!把结果集转换成 List<Bean> ;
-
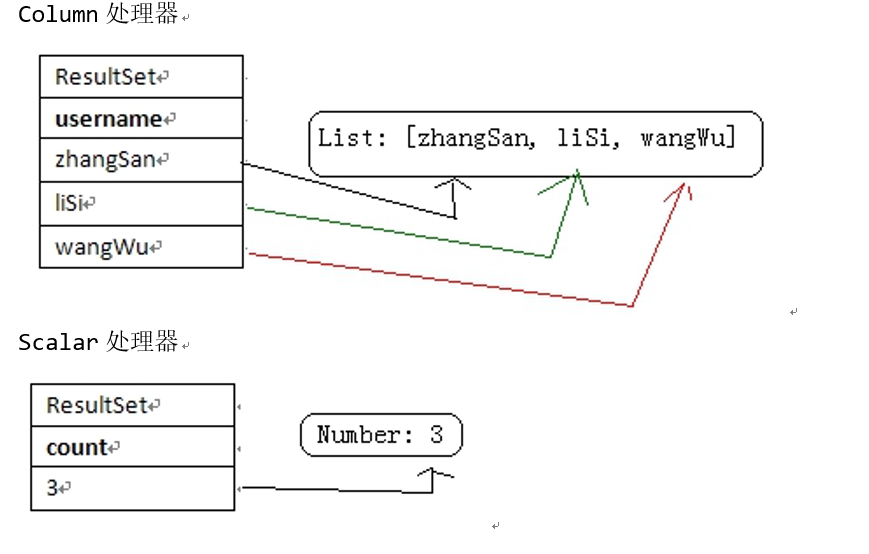
ColumnListHandler :多行单列处理器!把结果集转换成 List<Object> ,使用 ColumnListHandler 时需要指定某一列的名称或编号,例如: new ColumListHandler(“name”) 表示把 name 列的数据放到 List 中。
-
ScalarHandler :单行单列处理器!把结果集转换成 Object 。一般用于聚集查询,例如 select count(*) from tab_student 。
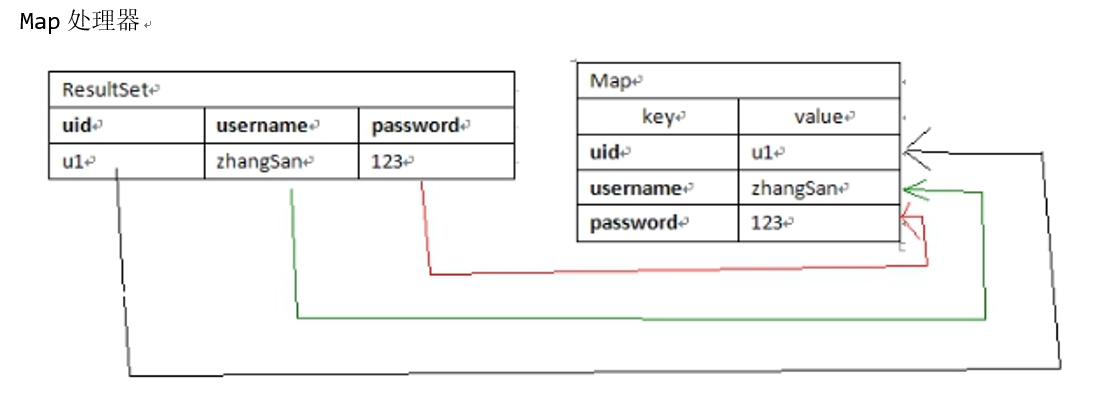



DBUtils工具类
closeQuietly(Connection conn)关闭连接,如果有异常try后不抛
commitAndCloseQuietly(Connection conn)提交并关闭连接
rollbackAndCloseQuietly(Connection conn)回滚并关闭连接
QueryRunner之查询
QueryRunner
的查询方法是:
public <T> T query(String sql, ResultSetHandler<T> rh, Object… params)
public <T> T query(Connection con, String sql, ResultSetHandler<T> rh, Object… params)
query()
方法会通过
sql
语句和
params
查询出
ResultSet
,然后通过
rh
把
ResultSet
转换成对应的类型再返回。
@Test
public void fun1() throws SQLException {
DataSource ds = JdbcUtils.getDataSource();
QueryRunner qr = new QueryRunner(ds);
String sql = "select * from tab_student where number=?";
Map<String,Object> map = qr.query(sql, new MapHandler(), "S_2000"); //把一行记录转换成一个Map,其中键为列名称,值为列值
System.out.println(map);
}
@Test
public void fun2() throws SQLException {
DataSource ds = JdbcUtils.getDataSource();
QueryRunner qr = new QueryRunner(ds);
String sql = "select * from tab_student";
List<Map<String,Object>> list = qr.query(sql, new MapListHandler()); //把转换集转换成List<Map>,其中每个Map对应一行记录
for(Map<String,Object> map : list) {
System.out.println(map);
}
}
@Test
public void fun3() throws SQLException {
DataSource ds = JdbcUtils.getDataSource();
QueryRunner qr = new QueryRunner(ds);
String sql = "select * from tab_student where number=?";
Student stu = qr.query(sql, new BeanHandler<Student>(Student.class), "S_2000"); //把结果集转换成一个Bean对象,在使用BeanHandler时需要指定Class,即Bean的类型
System.out.println(stu);
}
@Test
public void fun4() throws SQLException {
DataSource ds = JdbcUtils.getDataSource();
QueryRunner qr = new QueryRunner(ds);
String sql = "select * from tab_student";
List<Student> list = qr.query(sql, new BeanListHandler<Student>(Student.class)); //把结果集转换成List<Bean>,其中每个Bean对应一行记录
for(Student stu : list) {
System.out.println(stu);
}
}
@Test
public void fun5() throws SQLException {
DataSource ds = JdbcUtils.getDataSource();
QueryRunner qr = new QueryRunner(ds);
String sql = "select * from tab_student";
List<Object> list = qr.query(sql, new ColumnListHandler("name")); //多行单例处理器,即获取name列数据
for(Object s : list) {
System.out.println(s);
}
}
@Test
public void fun6() throws SQLException {
DataSource ds = JdbcUtils.getDataSource();
QueryRunner qr = new QueryRunner(ds);
String sql = "select count(*) from tab_student";
Number number = (Number)qr.query(sql, new ScalarHandler()); //对聚合函数的查询结果,有的驱动返回的是Long,有的返回的是BigInteger,所以这里我们把它转换成Number,Number是Long和BigInteger的父类!然后我们再调用Number的intValue()或longValue()方法就OK了。
单行单列处理器,一般用于聚合查询,在使用ScalarHandler时可以指定列名,如果不指定,默认为第1列。
int cnt = number.intValue();
System.out.println(cnt);
}















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









