









如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现
上一篇博客总结了四种垃圾收集算法,这次就来总结一下七种不同的垃圾收集器。(概述、特点、应用场景、参数设置)

注:连线表示两个收集器可以搭配使用;
上半部分为新生代,下半部分为老年代;
首先解释一下两个名词:
- 并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态;(如 ParNew、Parallel Scavenge、Parallel Old)
- 并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行,而垃圾收集程序线程运行于另一个CPU上;(如 CMS、G1)
1、Serial收集器
2、ParNew收集器
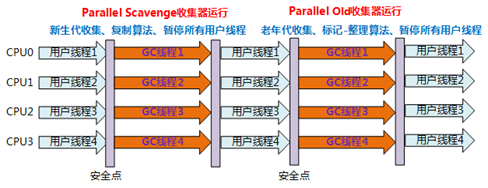
3、Parallel Scavenge收集器
4、Serial Old收集器
5、Parallel Old收集器
6、CMS(Concurrent Mark Sweep)收集器
7、G1(Garbage-First)收集器
8、IDEA中设置虚拟机参数的方法
1、Serial收集器
- 是最基本、发展历史最悠久的收集器;
- JDK1.3.1前是HotSpot新生代收集的唯一选择;
- 老年代版本:Serial Old
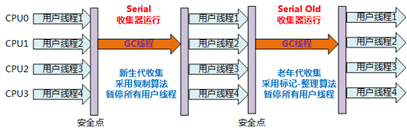
特点:
- 单线程;
(不仅只会使用一个CPU或一条线程去完成GC(Garbage Collection,垃圾收集),更重要的时在GC时,必须暂停其他所有的工作线程,直到它收集结束(Stop The World)) - 简单而高效
(因为对于限定单个CPU来说,没有线程交互的开销) - 算法:复制算法
- 使用区域:新生代(可与 运行于老年代的Serial Old 搭配使用)
应用场景:
- 运行于client模式下的虚拟机
- 对于限定单个CPU的环境来说,Serial收集器没有线程交互(切换)开销,可以获得最高的单线程收集效率
- 在用户的桌面应用场景中,可用内存一般不大(几十M至一两百M),可以在较短时间内完成垃圾收集(几十MS至一百多MS),只要不频繁发生,这是可以接受的
设置参数:
显式使用串行垃圾收集器
"-XX:+UseSerialGC"
2、ParNew收集器
- ParNew收集器其实就是Serial收集器的多线程版本
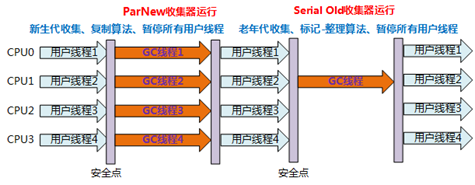
特点:
1.并行的多线程收集器;
2. 除了多线程,其余行为包括Serial收集器可用的所有控制参数、收集算法、Stop The World、对象分配策略、回收策略等都与Serial收集器完全一样
3. 除了Serial以外,目前只有它能与 CMS收集器 配合工作
4. 算法:复制算法
5. 使用区域:新生代
应用场景:
- 运行在Server模式下的虚拟机的首选
设置参数:
指定使用CMS后,会默认使用ParNew作为新生代收集:
"-XX:+UseConcMarkSweepGC"
强制指定使用ParNew:
"-XX:+UseParNewGC"
限制垃圾收集的线程数量,ParNew默认开启的收集线程与CPU的数量相同:
"-XX:ParallelGCThreads"
3、Parallel Scavenge收集器
- 其他收集器的关注点是尽可能地缩短GC时用户线程的停顿时间,而Parallel Scavenge收集器的目标是达到一个可控制的吞吐量(Throughput)。
该收集器也经常被称为“吞吐量优先”收集器。 - 老年代版本:Parallel Old收集器
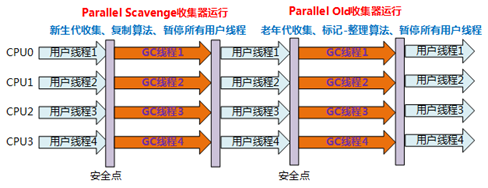
特点:
- 并行的多线程收集器;
- 以达到一个可控制的吞吐量为目的;
- 拥有自适应调节策略;
- 算法:复制算法
- 使用区域:新生代
应用场景
- 以高吞吐量为目标的虚拟机;
- 适合在后台运算而不需要太多交互的任务;
- 对收集器运作不了解,手工优化存在困难时,可使用Parallel Scavenge收集器配合自适应调节策略
设置参数:
控制最大垃圾收集停顿时间:
"-XX:MaxGCPauseMillis"
设置吞吐量大小:
"-XX:GCTimeRatio"
打开GC自适应调节策略:(不需要手工指定新生代大小(-Xmn)、Eden与Survivor区的比例(-XX:SurvivorRatio)、晋升老年代对象年龄(-XX:PretenureSizeThreshold)等参数细节)
"-XX:+UseAdaptiveSizePolicy"
4、Serial Old收集器
- Serial Old是Serial收集器的老年代版本
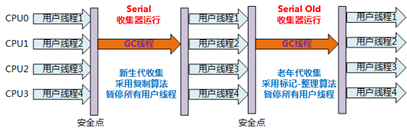
特点:
- 单线程;(Stop The World)
- 算法:“标记-整理”算法
- 使用区域:老年代
应用场景:
- Client模式下的虚拟机;
- Server模式下,在JDK1.5及之前的版本中与Paralled Scavenge收集器搭配使用;
- Server模式下,作为 CMS收集器 的后备预案,在并发收集发生Concurrent Mode Failure时使用
5、Parallel Old收集器
- Parallel Old是Parallel Scavenge收集器的老年代版本
特点:
- 并行的多线程收集器;
- 算法:“标记-整理”算法
- 使用区域:老年代(可与 Parallel Scavenge收集器 搭配使用)
应用场景:
- 注重吞吐量优先以及CPU资源敏感的场合,优先考虑Parallel Scavenge加Parallel Old收集器
设置参数:
指定使用Parallel Old收集器:
"-XX:+UseParallelOldGC"
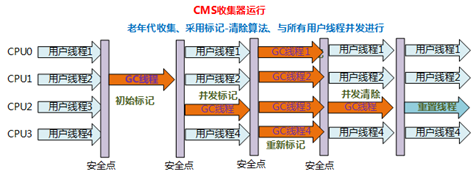
6、CMS收集器
- 也被称为“并发低停顿收集器(Concurrent Low Pause Collector)”
- 运作相对前面几种收集器来说更复杂一下,整个过程分为4个步骤:
初始标记(CMS initial mark)
并发标记(CMS concurrent mark)
重新标记(CMS remark)
并发清除(CMS concurrent sweep)
其中,初始标记和重新标记仍需Stop-The-World
特点:
- 以获取最短回收停顿时间为目标;
- 并发收集器;
- 对CPU资源非常敏感;
- 无法处理浮动垃圾,可能出现“Concurrent Mode Failure”失败而导致另一次Full GC的产生。
- 产生大量的空间碎片(设置参数可以解决)
- 算法:“标记-清除”算法
- 使用区域:老年代
应用场景:
- 集中在互联网站或者B/S系统的服务器端上的应用;(即重视服务响应速度的应用)
设置参数:
指定使用CMS收集器
"-XX:+UseConcMarkSweepGC"
空间碎片的解决方法:
"-XX:+UseCMSCompactAtFullCollection"
使得CMS出现上面这种情况时不进行Full GC,而开启内存碎片的合并整理过程;
但合并整理过程无法并发,停顿时间会变长;
默认开启(但不会进行,结合下面的CMSFullGCsBeforeCompaction);
"-XX:+CMSFullGCsBeforeCompaction"
设置执行多少次不压缩的Full GC后,来一次压缩整理;
为减少合并整理过程的停顿时间;
默认为0,也就是说每次都执行Full GC,不会进行压缩整理;
7、G1收集器
- G1(Garbage-First)收集器是当今收集器技术发展的最前沿成果之一
- 是一款面向服务端应用的垃圾收集器
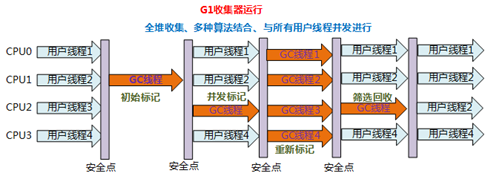
特点:
- 并行与并发
- 分代收集
- 空间整合(不会产生空间碎片,能提供规整的可用内存)
- 可预测的停顿
- 算法:**从整体上看,基于“标记-整理”算法;从局部(两个region之间)上看,基于“复制”算法**
- 使用区域:新生代和老年代
应用场景:
- 追求低停顿,并具有大堆的应用程序;
- 面向服务端应用,针对具有大内存、多处理器的机器;
设置参数:
指定使用G1收集器:
"-XX:+UseG1GC"
当整个Java堆的占用率达到参数值时,开始并发标记阶段;默认为45:
"-XX:InitiatingHeapOccupancyPercent"
为G1设置暂停时间目标,默认值为200毫秒:
"-XX:MaxGCPauseMillis"
设置每个Region大小,范围1MB到32MB;目标是在最小Java堆时可以拥有约2048个Region:
"-XX:G1HeapRegionSize"
新生代最小值,默认值5%:
"-XX:G1NewSizePercent"
新生代最大值,默认值60%:
"-XX:G1MaxNewSizePercent"
设置STW期间,并行GC线程数:
"-XX:ParallelGCThreads"
设置并发标记阶段,并行执行的线程数:
"-XX:ConcGCThreads"
8、IDEA中设置虚拟机参数的方法
选择“Edit Configurations…”,打开“Run/Debug Configurations”页面

在"VM options"中直接输入参数















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









