






目录
2.搜索页面和播放页面的两个signature的解密操作:MD5加密
3.通过音乐ID爬取当前音乐的md3地址。也就是第一个操作部分(音乐获取)
4.通过搜索栏参数(音乐名)获取 搜索第一个的 音乐名 和 音乐id。 也就是第二个步骤(搜索指定获取)操作。
5.获取到此音频地址后,对地址发送请求,将请求得到的数据以二进制的方式保存到指定目录文件夹中。
6.判断文件是否存在。不存在则创建改文件。此文件为获取后保存的文件
前言
为一起学习或者有兴趣python爬虫的朋友提供实战项目,以及也是我个人的学习记录
此篇文章更倾向于学习记录,所以我不会在开头就说明这个东西是什么,那个东西是什么,而是一步一步,遇到什么讲解什么,也请读者能尽量按顺序按部就班的阅读.
工具模块
hashlib => md5加密:提供了许多加密哈希算法,包括MD5、SHA-1、SHA-256等。
os => 提供了访问操作系统功能的方法,例如文件操作、目录操作、进程管理等。
time => 提供了处理时间的函数,包括获取当前时间、延时等功能。
requests => 用于发送HTTP请求和处理响应。
re => 提供了正则表达式操作的函数,用于在字符串中搜索、匹配和替换文本。
json => 用于处理JSON数据,用于JSON格式转换。
tkinter => 提供了创建图形用户界面(GUI)的工具包,可以用于构建窗口、按钮、文本框等GUI元素
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_43031450/article/details/137141065
一. 概念/思路
一步一步探索网站中的内容完成此次爬取所需要的基础网络内容,说明酷狗音乐网页爬取音乐的基础思路.
1.资源/目标/要爬的 -.-
首先进入酷狗音乐的网址:酷狗音乐
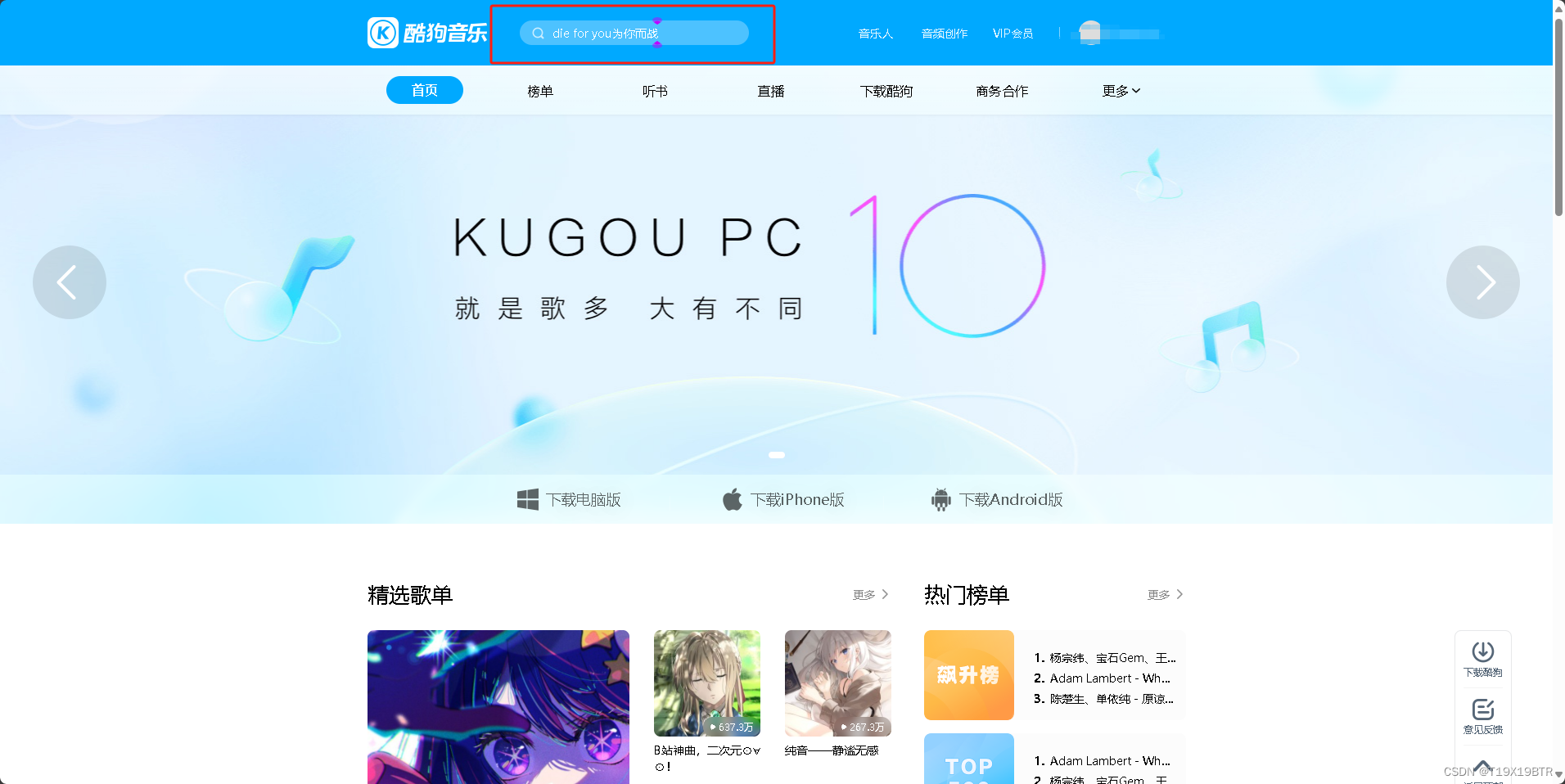
在页面搜索栏输入你想搜索的音乐,并搜索(也可以世界在主页直接点击一首音乐播放,不过后面还是要涉及搜索操作的,建议跟着我的步骤来):
进入了搜索结果页面点击播放第一首歌曲,进入单曲详情界面(播放界面)且接下来的思路概念理解操做都将围绕这两个加粗显示的界面开展: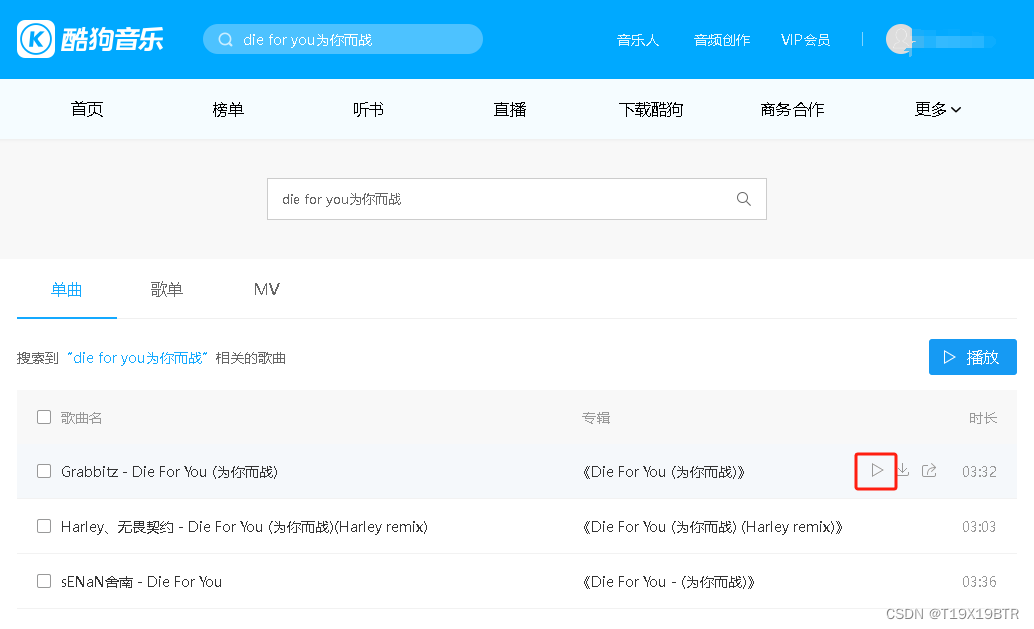
进入歌曲播放页面,按"F12" 或者鼠标右键选择"检查"打开开发者面板: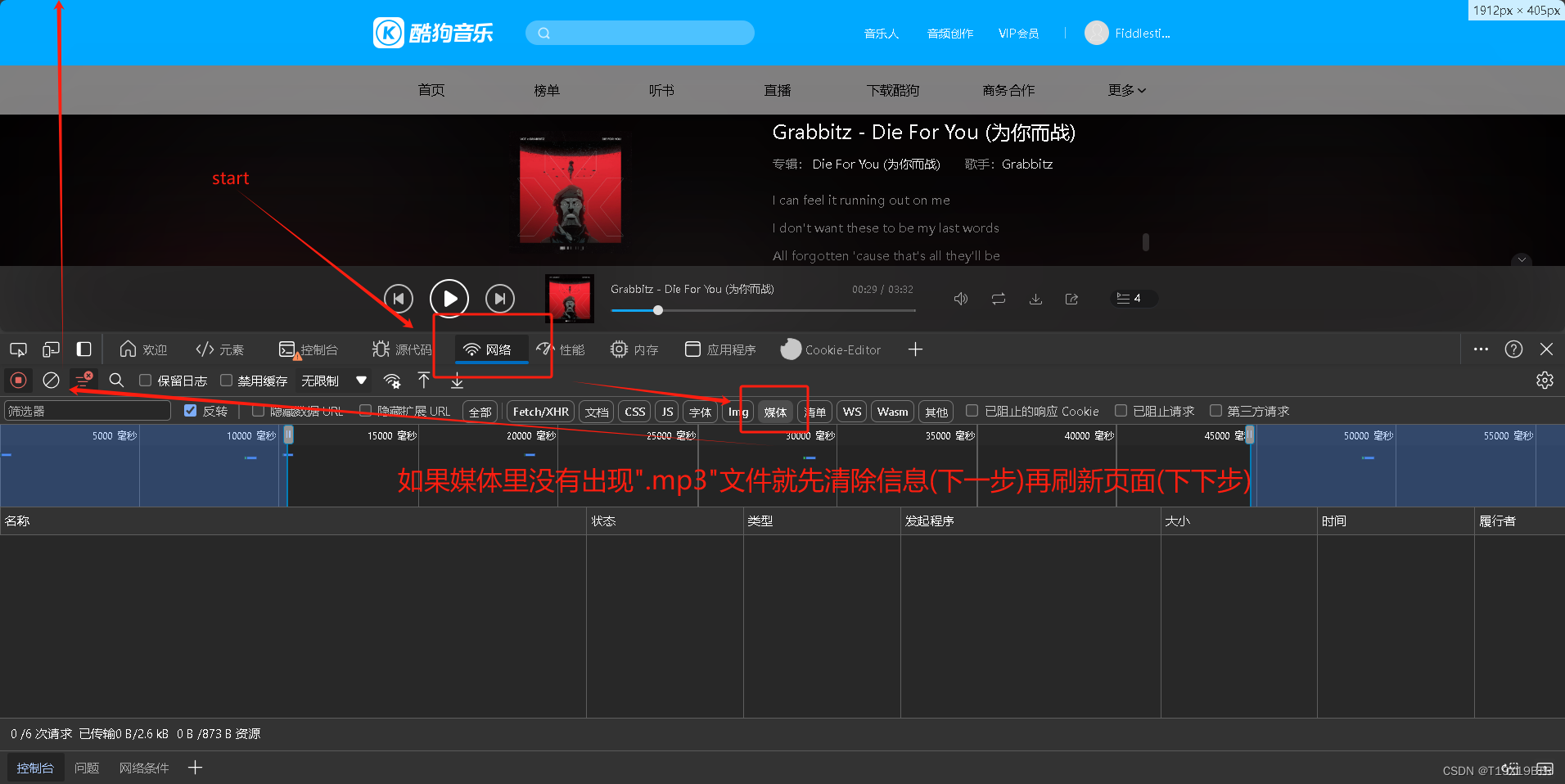
此时点击网络(network)-->媒体(media)-->清除网络日志-->刷新页面,大概率能在媒体中出现.mp3文件如果不行 " 一段一段的拖动播放进度条",到达末尾或中间部分的时候会出现mp3文件.(具体原因不太清楚)
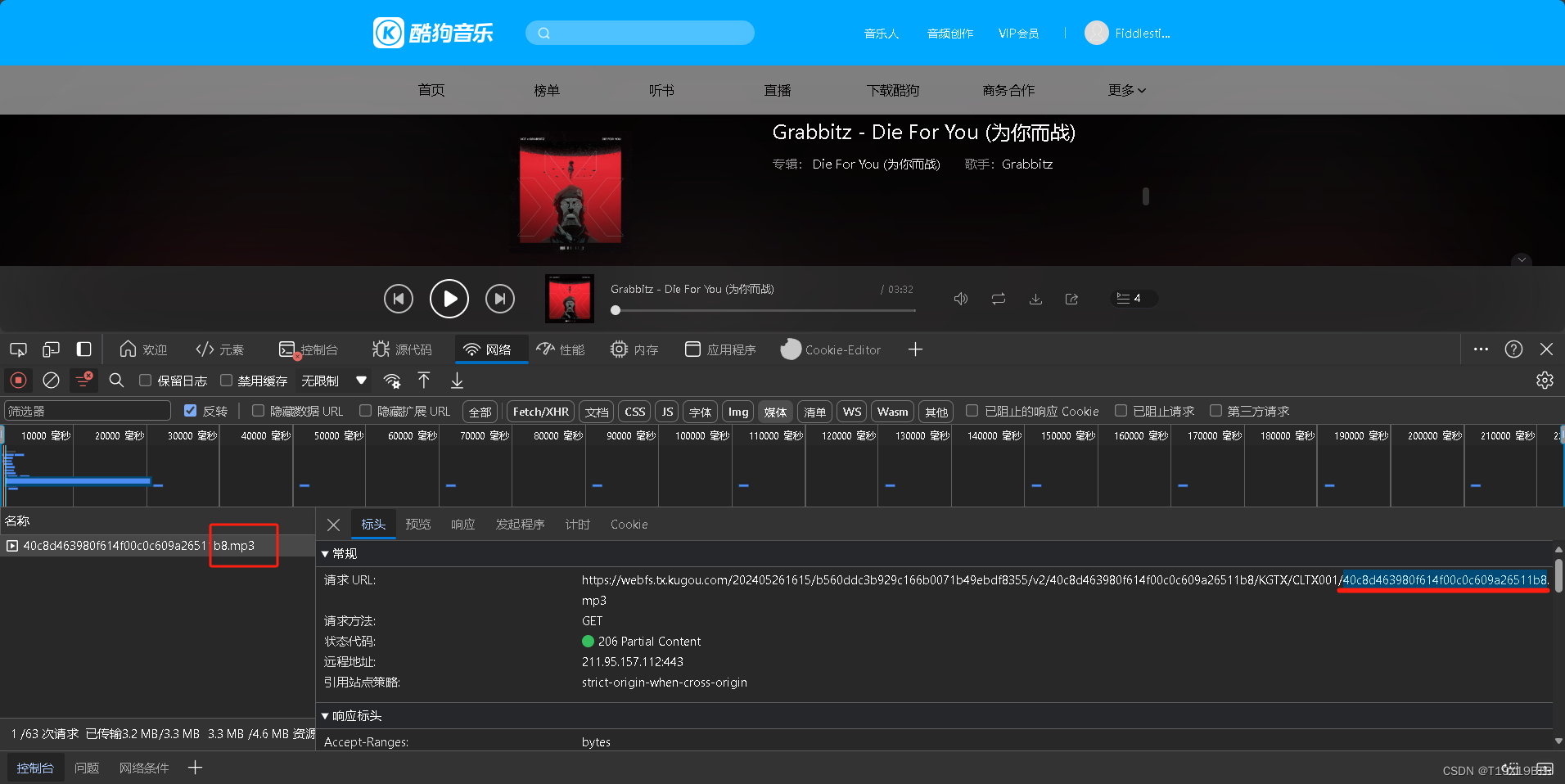
接下来点击这个媒体文件可以看见他的请求URL
URL(Uniform Resource Locator,统一资源定位符)是互联网上用来标识某一处资源的地址。它作为网页、文件、图片、视频或其他任何网络上可访问资源的地址,允许用户通过浏览器或其他网络客户端访问这些资源。
在这里说人话就是,这一长串网址指向 这首歌 存在于 网络中的本体如果我们直接复制这段网址会到达这个界面,而在这个界面我们将可以直接下载这首歌曲.
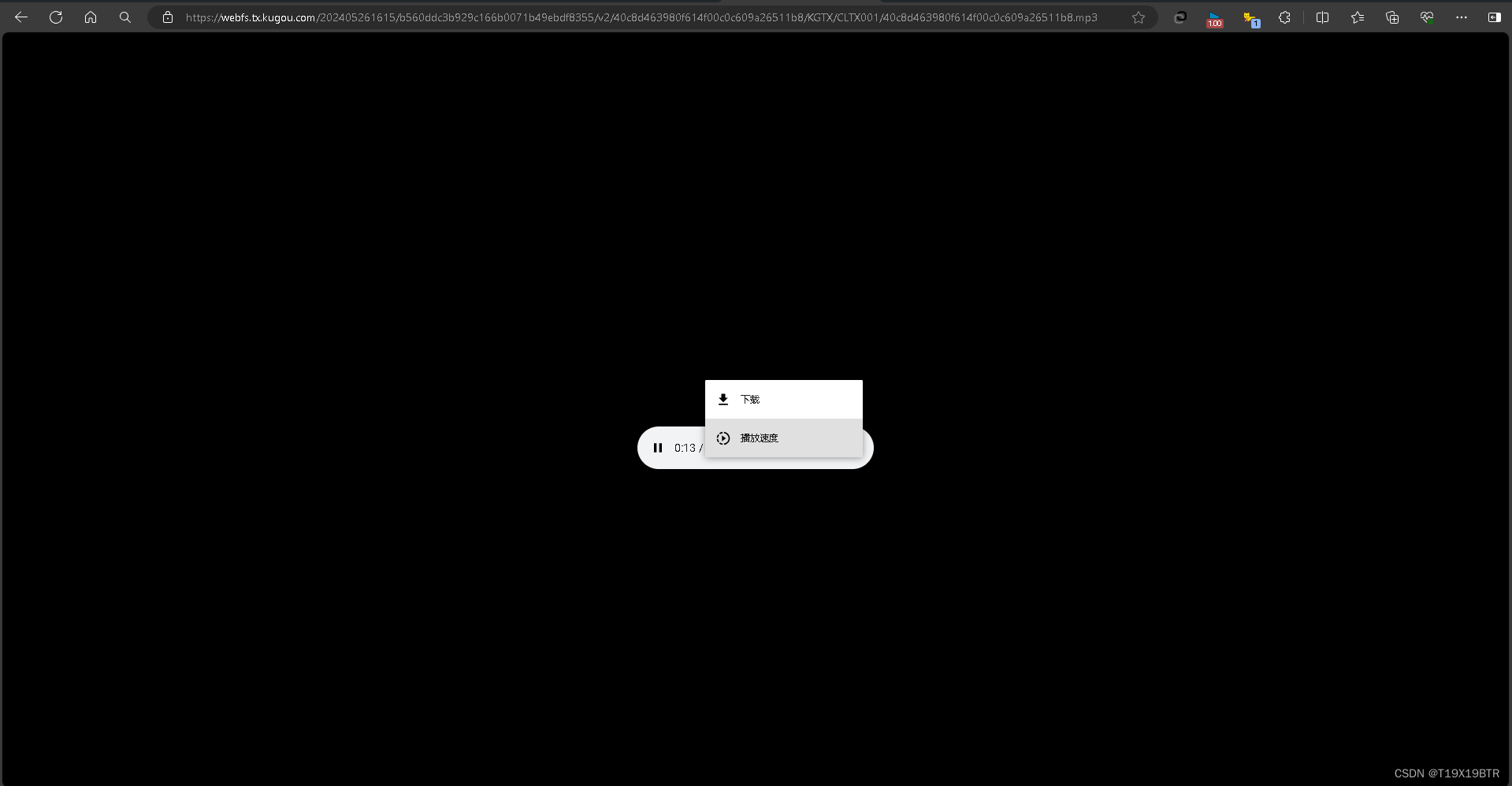
下图中我所画出红色横线(由.mp3往前到第一个斜杠的位置)也可以说被选中的这一块,即是我们此次基本思路中最重要的角色,最需要被理解的一部分现在我们的理解可以是,他在这段大长串地址中的"歌曲ID"(后面会有真的歌曲ID)因为他唯一且指向唯一的一首音乐.接下来的认识中他也会以不止一种名字被称呼如 "hash值"或"signature"(所以你搜的音乐不同,这个值也不同,不用担心)
为什么是网址的这一块,为什么是signature,别问,平台是这么设计的
2.资源哪里来/谁告诉我们去哪爬啊(反推/逆向?)
现在我们要做的是根据这个歌曲的signature反推出歌曲的来源(谁给我们反馈出这个url让我们知道该去这下载的? 0.o)
这个网址指向的是资源的本体,相当于我们此次项目搜索音乐的结果,目标,而此前而之前的搜索歌曲,播放歌曲,都已经在我们的网页中完成了,现在我们要反推,去完成完整爬取过程
按下"CTRL + F"打开开发者面板的搜索栏粘贴我们复制的signature并搜索,看到info,我的第一想法就是information,信息,因此我们的音乐信息就存储在" songinfo" 当中随便点一个搜索结果进入songinfo,通过对比我们可以发现,刚才指向资源的url就在响应信息的" play_url"当中,算是来对地方了
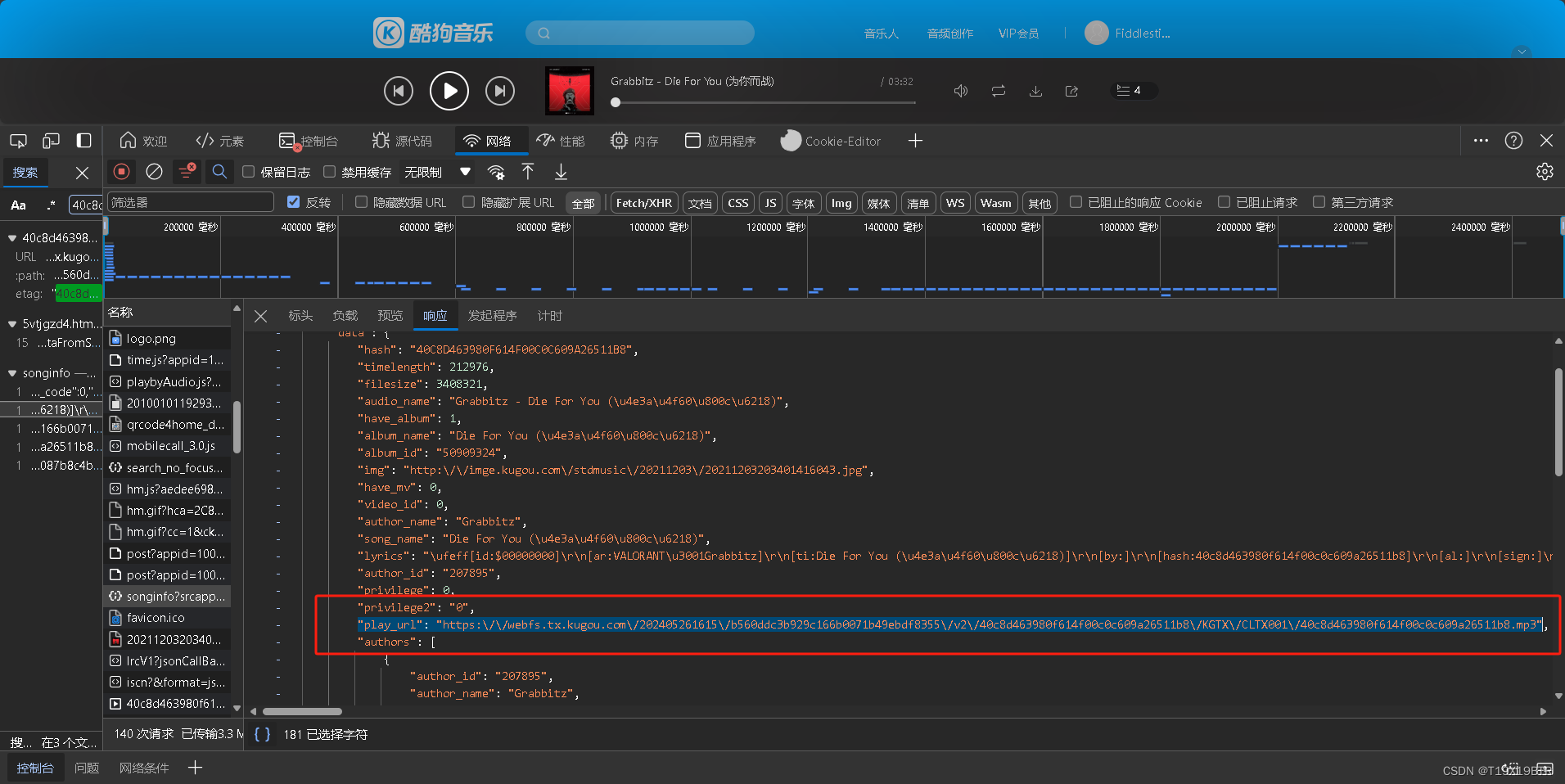 ,然后点击" 负载(payload)"就可以看到与这首音乐相关的各种id巴拉巴拉有待深入了解.
,然后点击" 负载(payload)"就可以看到与这首音乐相关的各种id巴拉巴拉有待深入了解.
我们对比一下现在知道了songinfo中有我们要的play_url,我们又该如何获取songinfo的URL呢,观察songinfo的请求URL,再对比songinfo"负载"中的信息,我们可以惊奇的发现,好像songinfo的URL的主体只有" https://wwwapi.kugou.com/play/songinfo? "! ! ! ! !,没错除了这段主题实际上其他的都是参数

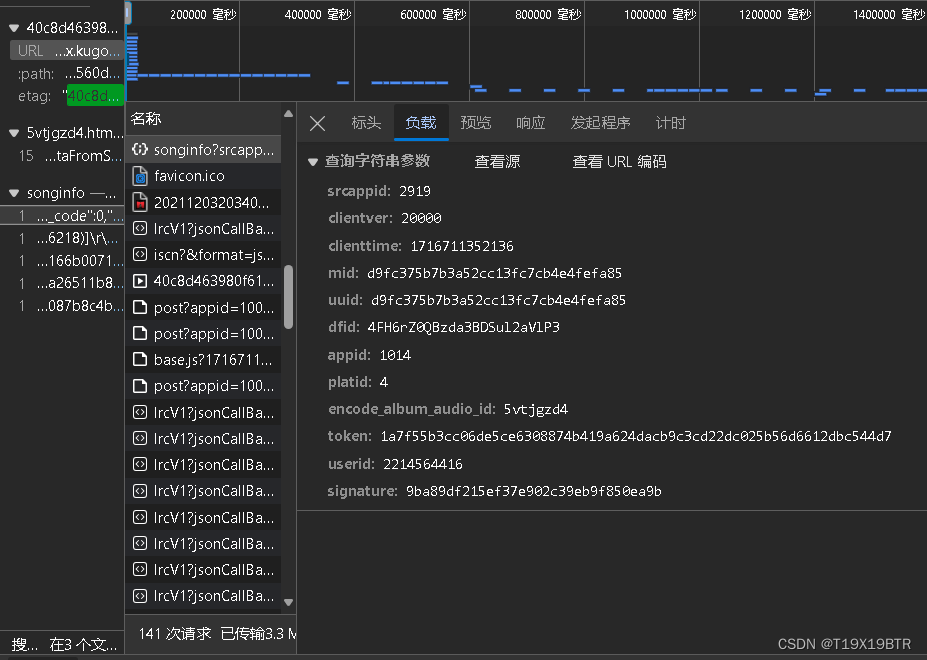 将会作为代码部分函数"fetch_url"的datas部分(没看到的不用注意此句)
将会作为代码部分函数"fetch_url"的datas部分(没看到的不用注意此句)
并且 如果你重新回到之前的步骤选择一首其他的音乐,再次找到这里后你会发现,每个音乐"负载"中的信息除了clienttime,encode和signature三个参数以外的参数都不会有改变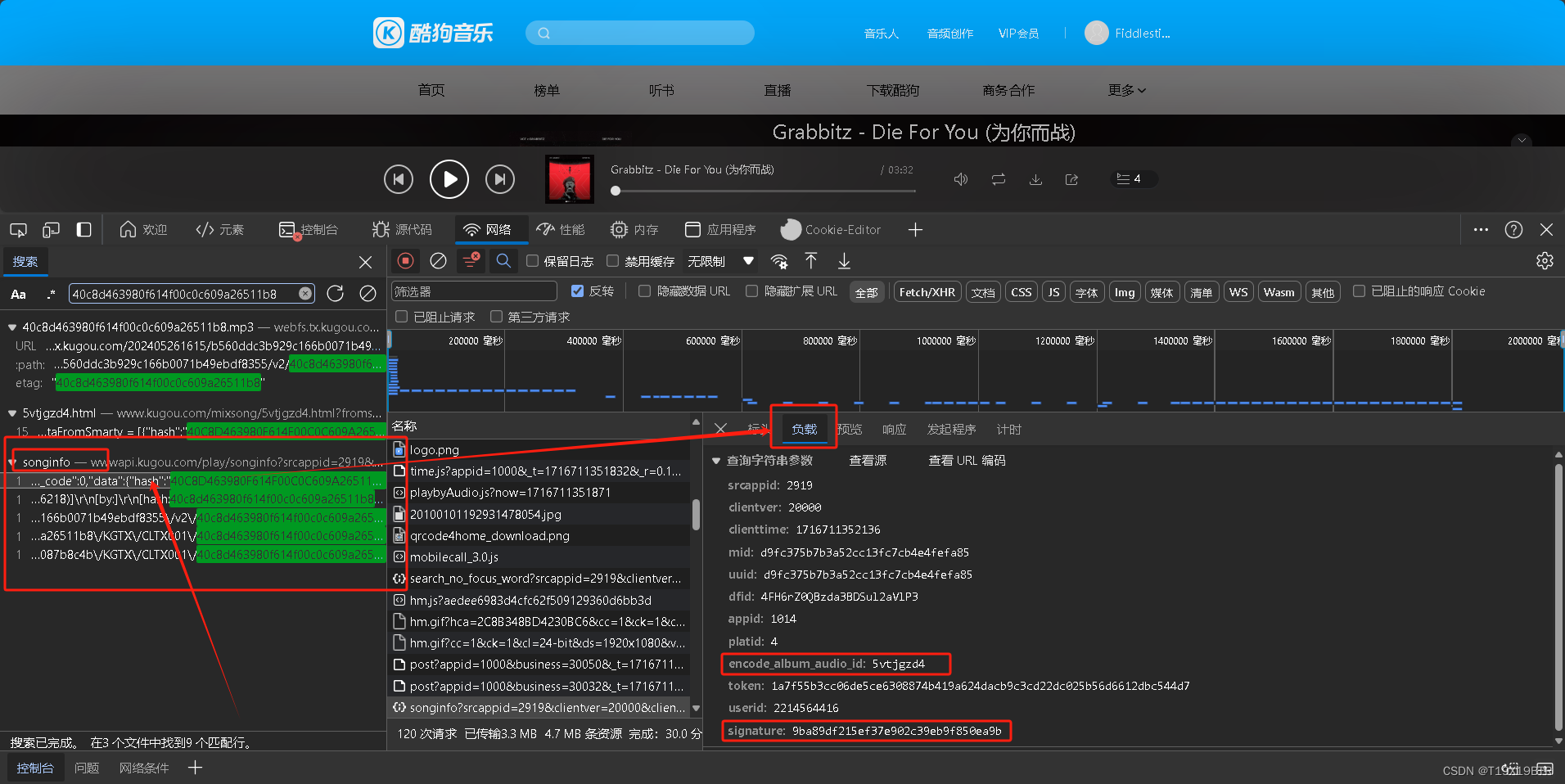
3.指引我们一路通行的signature是何方神圣?
我们现在知道了,实际上在网页中搜索的音乐信息clienttime,encode和signature不同
clienttime和encode_album_audio_id好理解,一个是时间戳,一个是音乐ID,那现在只有一个问题:
先前我所说,signature是一个"歌曲ID",但我又说有真的歌曲ID,不是哥们儿, 那这个signature到底是谁,谁家好人无聊给一个音乐设置"两个"ID?
实际上,这是平台设计的,通过结合所有的参数进行"MD5"加密后得出的一段用于发送请求的参数,是一段哈希值,也就是说signature实际上是一个在其他参数都存在,依附在其他参数之上的额外一层保密层,
因为音乐的play_url是以signature为主要指向参数的
1.除了clienttime,encode和signature都是固定值
2.signature是结合其他所有值通过MD5加密出来的32位数字.
所以我们获取时间,给出音乐ID,使用现成的MD5加密就能得到即可以获取到音乐URL
这也是在酷狗上爬取音乐的核心信息
这个MD5超出了我的知识范围就这样理解下吧
MD5(Message Digest Algorithm 5,消息摘要算法第五版)是一种广泛使用的哈希函数,它可以产生一个128位(16字节)的哈希值,通常用一个32位的十六进制字符串表示。MD5由Ron Rivest在1991年设计,最初被用来作为一种安全的密码哈希算法。
MD5的主要特点包括:
固定长度输出:无论输入数据的大小如何,MD5算法都会产生一个固定长度(128位)的哈希值。
散列唯一性:理论上,不同的输入数据应该产生不同的哈希值。MD5设计时旨在减少哈希碰撞的概率,即不同的输入产生相同输出的情况。
快速计算:MD5算法计算速度快,适用于需要快速哈希处理的场景。
单向性:MD5是单向的,意味着从哈希值几乎不可能反推出原始数据。
易于实现:MD5算法相对简单,容易在各种软件和硬件平台上实现。
4.得signature者得成功爬取(算"逆向"吗?)
现在我们按下" CTRL + shift + F " 打开全局搜索界面(图中问题可以结合原著看一下,我是不太懂)
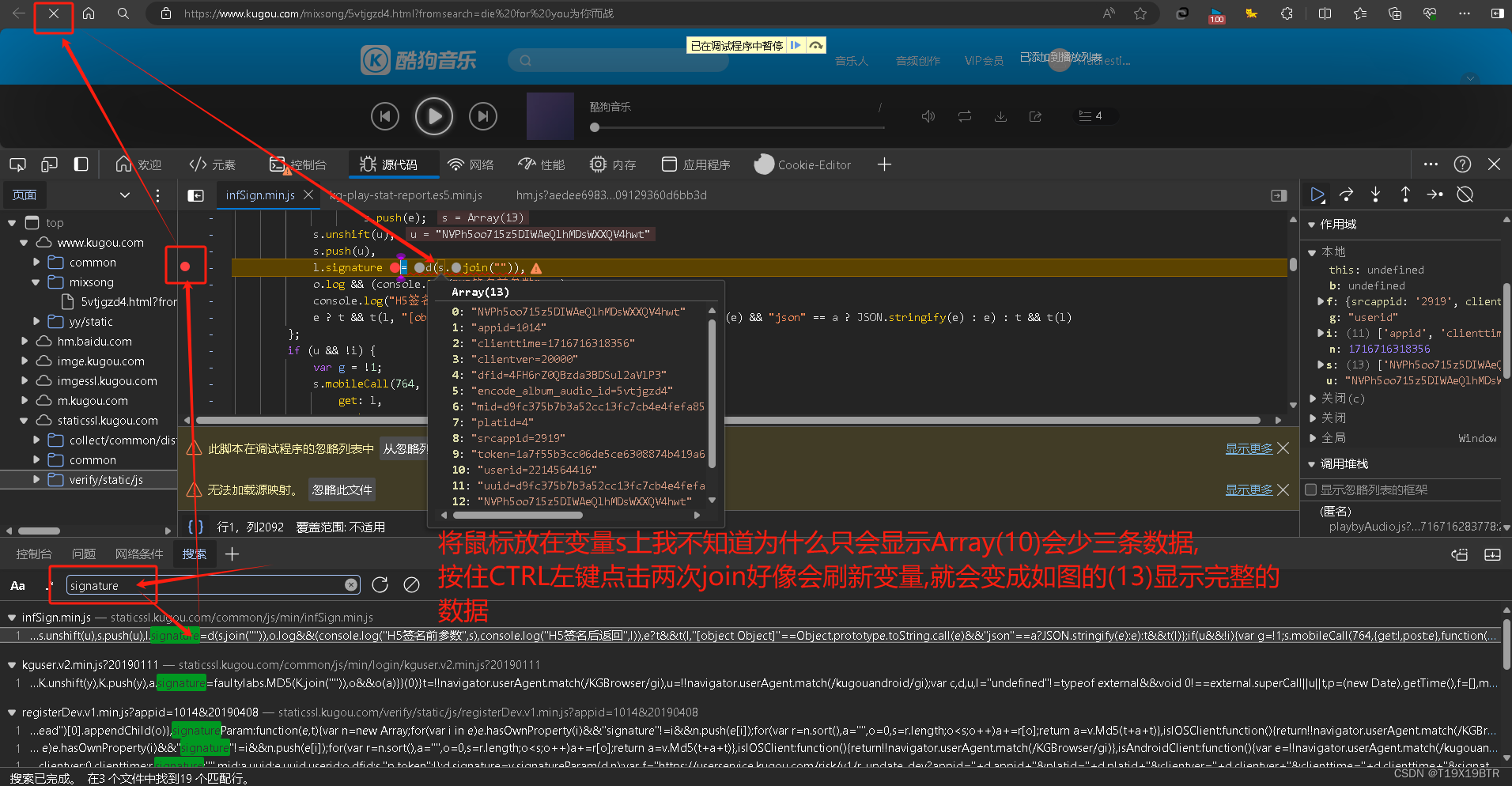
将会作为代码部分函数"MD5_sign"的lists部分(没看到的不用注意此句)
以上就为我们爬取什么,从哪爬取,怎么爬取,我能理解的所有思路和概念了也是关于单曲详情界面(播放界面)的相关概念的理解
想必各位对爬的理解也如下所示:
"爬一首音乐"
👇👇👇
"爬取一个音乐资源的URL并下载"
👇👇👇
"从音乐信息表获得资源的URL并下载"
逐渐的充实起来了.
5.通过搜索来指定爬取内容
这里的操作是有关搜索结果页面的内容理解的
"简单描述此操作 就是输入你想要的 音乐名 或 音乐名加作者名 搜索到音乐,获取 音乐ID 交给
第一步操作获得音乐mp3文件
我们现在需要模拟酷狗搜索栏操作,通过关键字搜索,并获取与关键字最相识的第一个音乐。"
在大部分的操作上是重复的回到搜索结果页面打开开发者面板如图操作,可以看见这个页面的所有音乐都在datas 的lists中其中[0]就是这个网页的第一首音乐,展开[0]音乐可以看见该页面第一首歌曲的信息.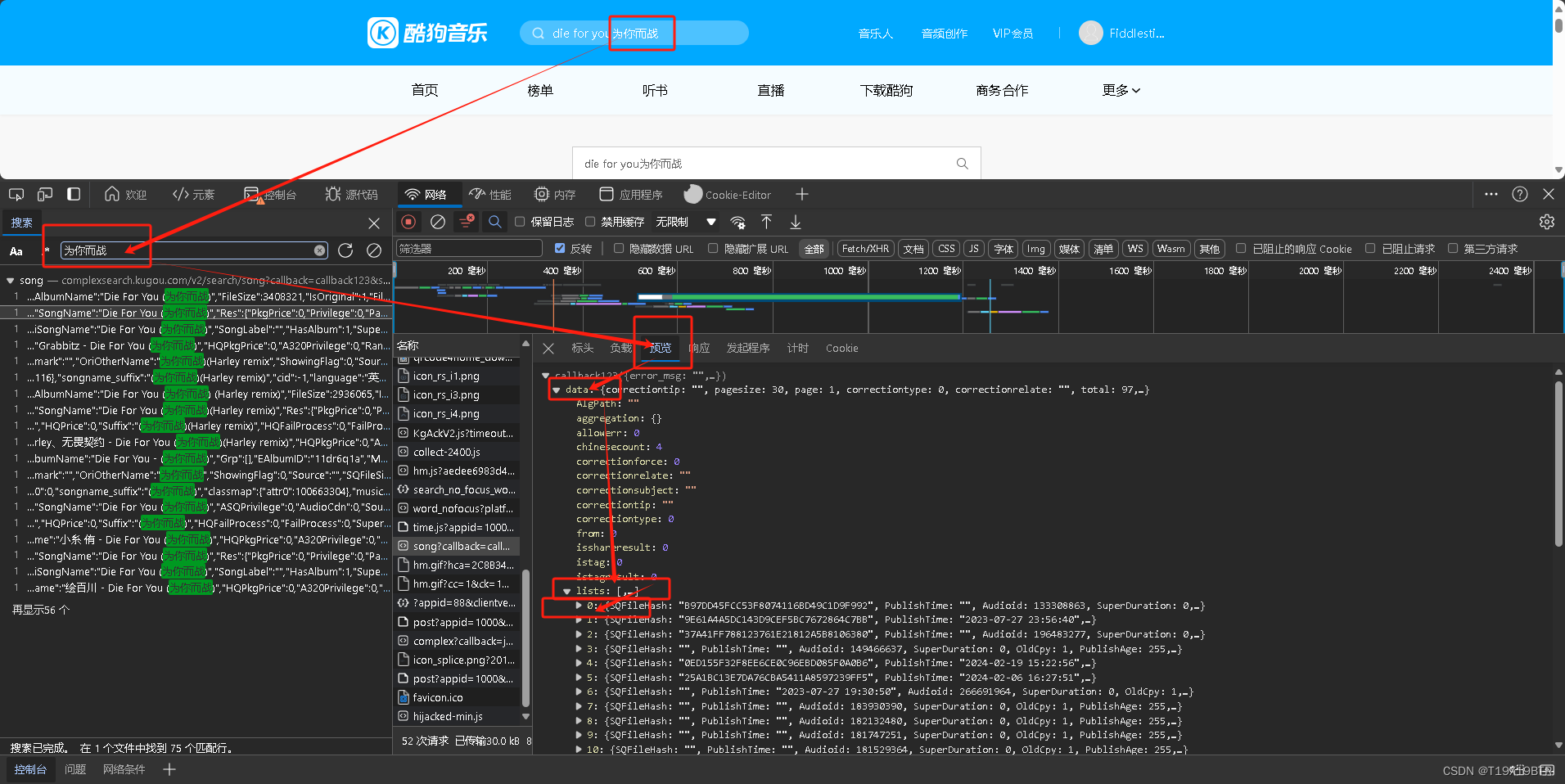
查看这首歌曲的"负载"内容,同样与其他搜索的音乐对比可以发现,又是除了时间戳,音乐名字和signature值不同的其他参数固定,且signature依旧是以其他参数为基础MD5加密后的32为值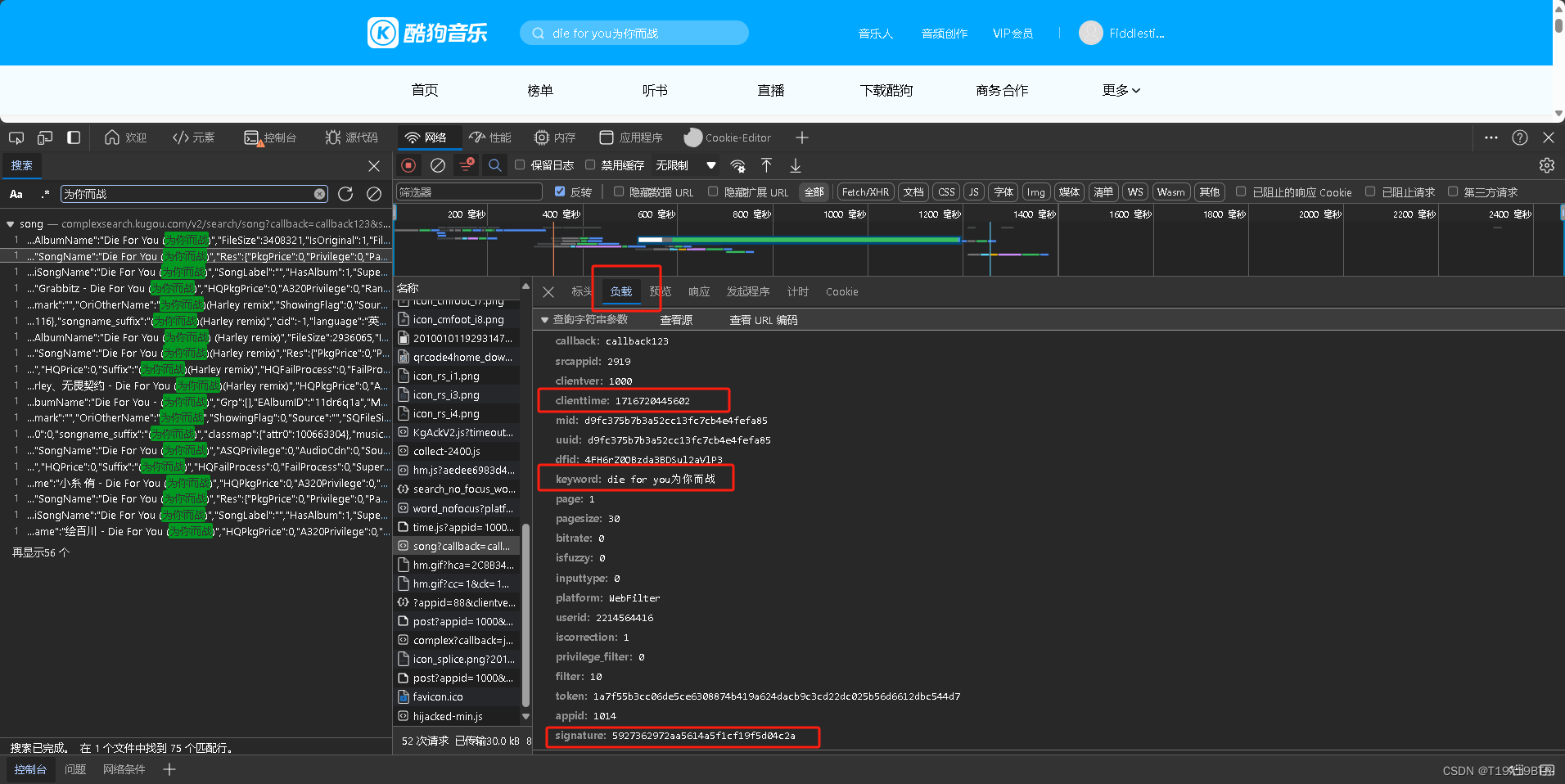
将会作为代码部分函数"audio_id_list"的datas部分(没看到的不用注意此句)
同样全局搜索signature找到s变量的参数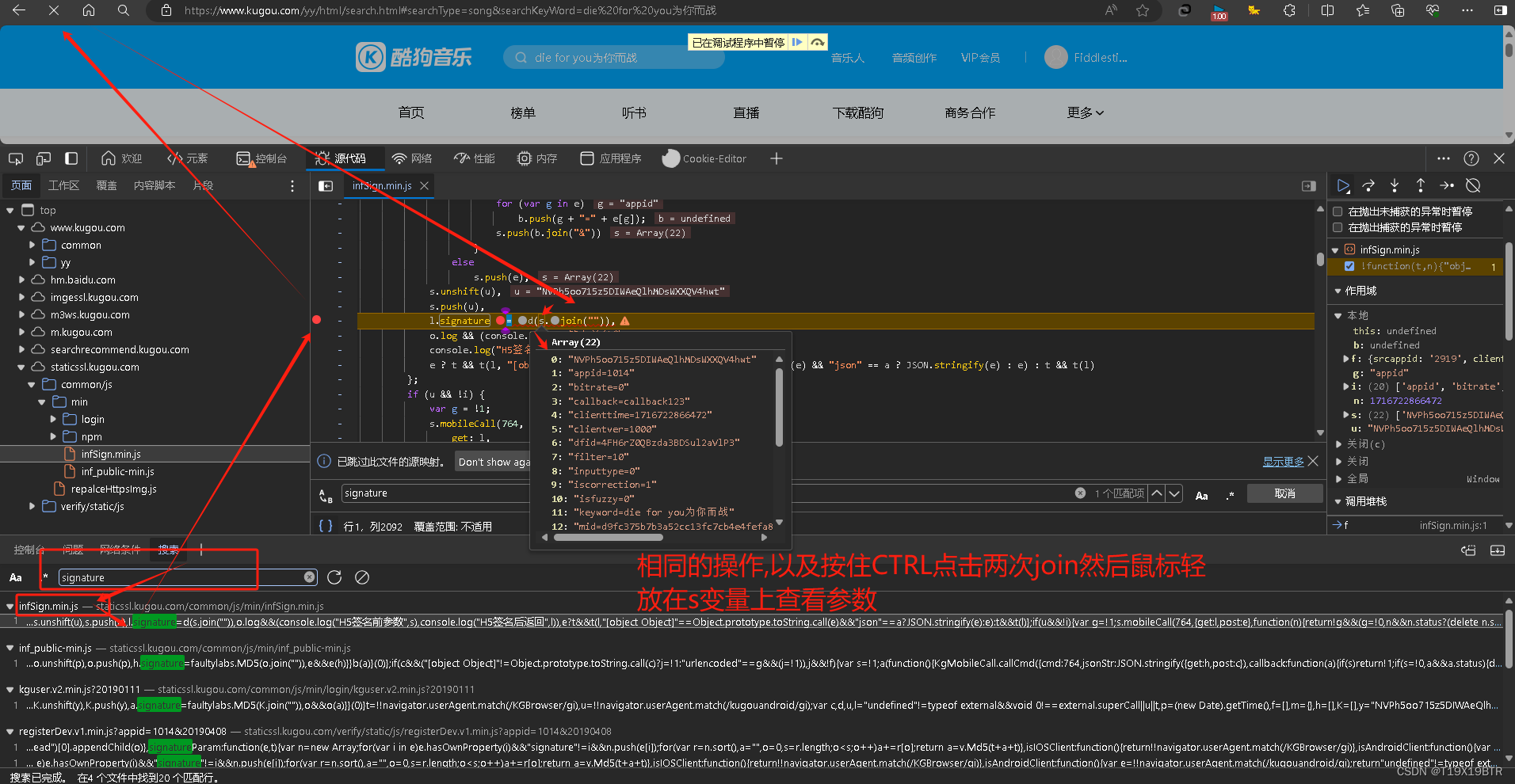 将会作为代码部分函数"MD5_sign_search"的lists部分(没看到的不用注意此句)
将会作为代码部分函数"MD5_sign_search"的lists部分(没看到的不用注意此句)
二 .代码启动!
以完成指定搜索爬取为目标的顺序展现代码
1.所需要的工具包
#导入所需模块
import hashlib
import os
import time
import requests
import re
import json
from tkinter import *
2.搜索页面和播放页面的两个signature的解密操作:MD5加密
def MD5_sign(timestamp, audio_id):
"""
通过音乐id解密详情页单个音乐的signature参数
:param timestamp: 时间戳
:param audio_id: 音乐id(例如:72jrv7fa)
:return:
"""
signature_list = ['NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt',
'appid=1014',
f'clienttime={timestamp}',
'clientver=20000',
'dfid=3MmrUf3e5zpy3cStkN3Bn9oS',
f'encode_album_audio_id={audio_id}',
'mid=c4de83c1ebb2e73fc5ae95304a674918',
'platid=4',
'srcappid=2919',
'token=483ef68936faa09268f3a42f7ab7ee31b584a3f155828a100c95fadf7c5ddd1e',
'userid=2078452878',
'uuid=c4de83c1ebb2e73fc5ae95304a674918',
'NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt']
string = "".join(signature_list)
MD5 = hashlib.md5()
MD5.update(string.encode('utf-8'))
sign = MD5.hexdigest() # md5 32位加密内容
return sign
def MD5_sign_search(timestamp, music_name):
"""
通过音乐id解密搜索页的signature参数
:param timestamp:时间戳
:param music_name:搜索框音乐名(例如:把回忆拼好给你)
:return:加密后32位md5参数(例如:72181cc6baf76ee0404837d5d657dd5c)
"""
signature_list = ['NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt',
'appid=1014',
'bitrate=0',
'callback=callback123',
f'clienttime={timestamp}',
'clientver=1000',
'dfid=3MmrUf3e5zpy3cStkN3Bn9oS',
'filter=10',
'inputtype=0',
'iscorrection=1',
'isfuzzy=0',
f'keyword={music_name}',
'mid=c4de83c1ebb2e73fc5ae95304a674918',
'page=1',
'pagesize=30',
'platform=WebFilter',
'privilege_filter=0',
'srcappid=2919',
'token=483ef68936faa09268f3a42f7ab7ee31b584a3f155828a100c95fadf7c5ddd1e',
'userid=2078452878',
'uuid=c4de83c1ebb2e73fc5ae95304a674918',
'NVPh5oo715z5DIWAeQlhMDsWXXQV4hwt']
string = "".join(signature_list)
MD5 = hashlib.md5()
MD5.update(string.encode('utf-8'))
sign_lis = MD5.hexdigest() # md5 32位加密内容
return sign_lis
3.通过音乐ID爬取当前音乐的md3地址。也就是第一个操作部分(音乐获取)
def fetch_url(audio_id):
"""
通过音乐ID爬取当前音乐的md3地址
:param audio_id: 音乐ID(72jrv7fa)
:return:音乐url(........mp3)
"""
timestamp = int(time.time() * 1000)
print('audio_id:', audio_id)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
}
sign = MD5_sign(timestamp, audio_id)
datas = {
'srcappid': '2919',
'clientver': '20000',
'clienttime': timestamp,
'mid': 'c4de83c1ebb2e73fc5ae95304a674918',
'uuid': 'c4de83c1ebb2e73fc5ae95304a674918',
'dfid': '3MmrUf3e5zpy3cStkN3Bn9oS',
'appid': '1014',
'platid': '4',
'encode_album_audio_id': audio_id,
'token': '483ef68936faa09268f3a42f7ab7ee31b584a3f155828a100c95fadf7c5ddd1e',
'userid': '2078452878',
'signature': sign,
}
response = requests.get(url='https://wwwapi.kugou.com/play/songinfo?', headers=headers, params=datas)
jsurl = response.json()
# print('jsurl: ', jsurl)
play_url = jsurl['data']['play_url']
return play_url
4.通过搜索栏参数(音乐名)获取 搜索第一个的 音乐名 和 音乐id。 也就是第二个步骤(搜索指定获取)操作。
def audio_id_list(music_name):
"""
通过搜索栏参数(音乐名)获取 搜索第一个的 音乐名 and ID
:param music_name: 搜索栏参数(音乐名) 例如: 苏星婕 - 把回忆拼好给你
:return: 音乐名 音乐ID(苏星婕 - 把回忆拼好给你 72jrv7fa)
"""
timestamp = int(time.time() * 1000)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0',
}
sign = MD5_sign_search(timestamp, music_name)
datas = {
'callback': 'callback123',
'srcappid': '2919',
'clientver': '1000',
'clienttime': timestamp,
'mid': 'c4de83c1ebb2e73fc5ae95304a674918',
'uuid': 'c4de83c1ebb2e73fc5ae95304a674918',
'dfid': '3MmrUf3e5zpy3cStkN3Bn9oS',
'keyword': music_name,
'page': '1',
'pagesize': '30',
'bitrate': '0',
'isfuzzy': '0',
'inputtype': '0',
'platform': 'WebFilter',
'userid': '2078452878',
'iscorrection': '1',
'privilege_filter': '0',
'filter': '10',
'token': '483ef68936faa09268f3a42f7ab7ee31b584a3f155828a100c95fadf7c5ddd1e',
'appid': '1014',
'signature': sign,
}
response = requests.get(url='https://complexsearch.kugou.com/v2/search/song?', headers=headers, params=datas)
callback_dict = re.findall('callback123\((.*)\)', response.text)[0]
jsurl = json.loads(callback_dict)
fileName = jsurl['data']['lists'][0]['FileName']
eMixSongID = jsurl['data']['lists'][0]['EMixSongID']
return fileName, eMixSongID
5.获取到此音频地址后,对地址发送请求,将请求得到的数据以二进制的方式保存到指定目录文件夹中。
def download_url(file_name, url_mp3):
"""
通过已经获取的mp3文件保存到文件夹中
:param file_name: 音乐名
:param url_mp3: 音乐url(.....mp3)
:return: 无
"""
response = requests.get(url_mp3)
try:
with open(f"./music_files/{file_name}.mp3", "wb") as f:
f.write(response.content)
except:
with open(f"./music_files/{int(time.time() * 1000)}.mp3", "wb") as f:
f.write(response.content)
print(f'{file_name}-----下载成功')
6.判断文件是否存在。不存在则创建改文件。此文件为获取后保存的文件
def directory_create():
"""判断文件是否存在。不存在则创建改文件"""
directory = "./music_files"
if not os.path.exists(directory):
os.makedirs(directory)7.运行程序
if __name__ == '__main__':
directory_create() # 判断music_flie文件是否存在
music_name = input("请输入你需要下载的音乐名字")
audio_id = audio_id_list(music_name) # (苏星婕 - 把回忆拼好给你, 72jrv7fa)
file_name = audio_id[0] # 苏星婕 - 把回忆拼好给你
emixsong_id = audio_id[1] # 72jrv7fa
time.sleep(2)
url_mp3 = fetch_url(emixsong_id) # 获取 ......mp3
download_url(file_name, url_mp3) # 下载保存总结
到这里就结束了这一次的酷狗音乐爬取的项目啦,可以看出,这个项目可以优化的地方真的很多很多,比如是否精准搜索,爬取多首音乐,爬取整个歌单,没有UI 界面等,有太多太多的可能. 不过这次的实战对我来说依旧意义颇深,仿若醍醐灌顶,对爬虫有了跟之前相比完全不同的理解,以及看到了爬虫无限的可能
结尾也说一下,我无数次问AI,它无数次返回的一句相同的话
"请注意,爬取音乐文件可能涉及版权问题,确保在遵守相关法律法规的前提下进行爬虫操作。"
原文链接:https://blog.csdn.net/qq_43031450/article/details/137141065


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









