







第一范式
第一范式条件:数据库表的每一列都是不可分割的基本数据项,即每一列都是不可拆分的原子项。
如以下表存在可再分项(高级职称),所以不满足第一范式。在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
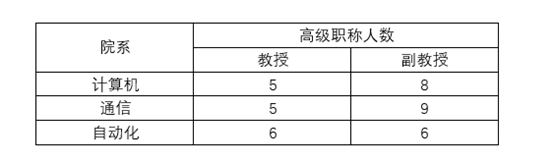
非规范化转换为规范化的第一范式方法很简单,将表分别从横向、纵向展开即可。将高级职称横向展开即可以得到满足第一范式的表结构。
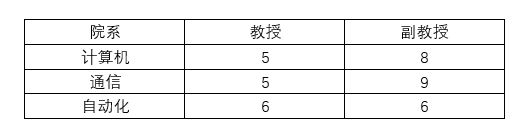
第二范式
第二范式条件:关系模式必须满足第一范式,并且所有非主属性都完全依赖于主属性。所谓完全依赖是指不能存在依赖非主属性的属性,如果存在,那么这个属性和非主属性应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。注意,符合第二范式的关系模型可能还存在数据冗余、更新异常等问题。

第三范式
第三范式的条件:关系模型满足第二范式,且属性与其它非主属性不存在传递依赖,即要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。

假设存在关系模式主键1:课程编号;列1:教师名;列2:教师家庭地址。显然满足第一范式和第二范式,但是教师家庭地址传递依赖于教师名,所以不满足第三范式。可以将教师名和教师家庭地址拆开作为一个表,此时就满足了第三范式。
范式的优点和缺点
优点:
范式的主要优点就是减少表中列和数据的冗余。
缺点:
没有任何冗余的表设计会产生更多关联以至于更多的查询行为,这意味着会产生更多次的数据库IO操作。对一些实际数据库应用,以时间换空间就不那么明智了。














 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









