







这里写目录标题
操作系统物理内存管理主要包括程序装入、交换技术、连续分配管理方式和非连续分配管理方式(分页、分段、段分页)。
程序装入已在本专栏上一篇文章中介绍过,因此本文主要介绍连续分配管理方式以及非连续分配管理方式。
连续分配管理方式
单一连续存储管理
在这种管理方式中,内存被分为两个区域:系统区和用户区。应用程序装入到用户区,可使用用户区全部空间。
优点:
易于管理
缺点:
对要求内存空间少的程序,造成内存浪费;程序全部装入,使得很少使用的程序也会占用—定数量的内存。
分区式存储管理
分区式存储管理是把内存分为一些大小相等或不等的分区,操作系统占用其中一个分区,其余的分区由应用程序使用,每个应用程序占用一个或几个分区。
固定分区
将用户内存空间划分为若干个固定大小的区域,每个分区只装入一道作业,容易产生浪费和不足。
优点:
易于实现,开销小。
缺点:
会产生内部碎片,造成浪费;分区总数固定,限制了并发执行的程序数目。
动态分区
不预先将内存划分,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。
下面列出了几种常用的分区分配算法:
- 最先适配法(nrst-fit):按分区在内存的先后次序从头查找,找到符合要求的第一个分区进行分配。较大的空闲分区可以被保留在内存高端。
- 下次适配法(循环首次适应算法 next fit):按分区在内存的先后次序,从上次分配的分区起查找(到最后{区时再从头开始},找到符合要求的第一个分区进行分配。较大空闲分区不易保留。
- 最佳适配法(best fit):按分区在内存的先后次序从头查找,找到其大小与要求相差最小的空闲分区进行分配。较大的空闲分区可以被保留。
- 最坏适配法(worst fit):按分区在内存的先后次序从头查找,找到最大的空闲分区进行分配。较大空闲分区不易保留。
优点:
没有内碎片。
缺点:
引入了外部碎片;算法复杂,系统开销大。
伙伴系统
固定分区和动态分区方式都有不足之处。固定分区方式限制了活动进程的数目,当进程大小与空闲分区大小不匹配时,内存空间利用率很低。动态分区方式算法复杂,回收空闲分区时需要进行分区合并等,系统开销较大。伙伴系统方式是对以上两种内存方式的一种折衷方案。
伙伴系统规定,无论已分配分区或空闲分区,其大小均为 2 的 k 次幂,k 为整数, l≤k≤m,其中21 表示分配的最小分区的大小,2m 表示分配的最大分区的大小,通常 2m是整个可分配内存的大小。
假设系统的可利用空间容量为2m个字, 则系统开始运行时, 整个内存区是一个大小为2m的空闲分区。在系统运行过中, 由于不断的划分,可能会形成若干个不连续的空闲分区,将这些空闲分区根据分区的大小进行分类,对于每一类具有相同大小的所有空闲分区,单独设立一个空闲分区双向链表。这样,不同大小的空闲分区形成了k(0≤k≤m)个空闲分区链表。
分配步骤:
- 当需要为进程分配一个长度为n 的存储空间时,首先计算一个i 值,使 2(i-1) <n ≤ 2i,然后在空闲分区大小为2i的空闲分区链表中查找。
- 若找到,即把该空闲分区分配给进程。
- 否则,表明长度为2i的空闲分区已经耗尽,则在分区大小为2(i+1)的空闲分区链表中寻找。
- 若存在2(i+1)的一个空闲分区,则把该空闲分区分为相等的两个分区,这两个分区称为一对伙伴,其中的一个分区用于配,而把另一个加入分区大小为2^i的空闲分区链表中。
内存紧缩(内存碎片化处理)
将各个占用分区向内存一端移动,然后将各个空闲分区合并成为一个空闲分区。
这种技术在提供了某种程度上的灵活性的同时,也存在着一些弊端,例如:对占用分区进行内存数据搬移占用CPU时间;如果对占用分区中的程序进行“浮动”,则其重定位需要硬件支持。
紧缩时机:每个分区释放后,或内存分配找不到满足条件的空闲分区时。
覆盖技术
按自身逻辑把程序分成几个功能上相对独立的模块,不会同时执行的模块可以共享同一块内存区域,按时间先后运行(分时)。
必要的代码和数据常驻内存,不常用的代码在其余模块中实现,并且放在外存,需要时放内存,不存在调用关系的模块不必同时载入内存,可以相互覆盖,共用一个分区。
缺点:
设计开销大,程序员要划分模块和确定覆盖关系,编程复杂度增加了;覆盖模块从外存装入内存,实际是以时间来换空间。
交换技术
将暂时不能运行的程序送到外存以获得空闲内存空间,操作系统在内存管理单元MMU的帮助下把一个进程的整个地址空间的内容保存到外存中(换出swap out),而将外存中的某个进程的地址空间读入到内存中(换入swap in)。其大小为整个程序的地址空间(比较大,几十几百个页)。
进程再次换入后的内存地址不一定在原来位置上,可能已被占用,因此需要动态地址映射。也就是说同一个进程在两次换入后,虚拟地址一样,物理地址不一样。
覆盖与交换的比较
覆盖技术和交换技术的目的是一样的。
覆盖是发生在一个运行中的程序内部没有调用关系的模块之间,代价是程序员手动指定和划分逻辑覆盖结构;交换是内存中程序与管理程序或OS之间发生的,以进程作为交换的单位,需要把进程的整个地址空间都换进换出,对程序员是透明的,开销相对较大。
外部碎片和内部碎片的区别
内部碎片
内部碎片:内部碎片就是已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间;
内存的连续分配方式中的固定分区方法会产生内部碎片。
外部碎片
外部碎片:外部碎片指的是还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。
内存的连续分配方式中的动态分区方法会产生内部碎片。
非连续分配管理方式
在内存的连续分配方法中,为进程分配的空间是连续的,使用的地址都是物理地址。
内存的非连续分配方式通过引入进程的逻辑地址,把逻辑空间与实际存储空间分离,增加存储管理的灵活性。
逻辑地址和物理地址两个基本概念的定义如下:
- 逻辑地址:逻辑地址可以理解为虚拟地址(但两者并不相同),这个地址是程序看的虚拟的地址,并不真实存在。
- 物理地址:内存单元所看到的地址(加载到内存寄存器中的地址)。
逻辑地址到物理地址的映射是由内存管理单元(MMU)的硬件设备来完成的。
根据分配时所采用的基本单位不同,可将非连续分配方式分为以下三种:基本分页存储管理、基本分段存储管理和基本段页式存储管理。其中段分页存储管理是前两种结合的产物。
注意:“基本”一词是为了与虚拟内存实现的三种方式区别开。
基本分页式存储管理
基本分页管理不会产生外部碎片。进程只会在为最后一个不完整的块申请一个块时,才产生内部碎片,这种碎片相对于进程来说也是很小的,每个进程平均只产生半个块大小的内部碎片(也称页内碎片)。
基本分页存储的几个基本概念
(1)页/页框/块
进程中的块称为页(Page),内存中的块称为页框(Page Frame,或页帧)。外存也以同样的单位进行划分,直接称为块(Block)。进程在执行时需要申请主存空间,就是要为每个页面分配主存中的可用页框,这就产生了页和页框的一一对应。
(2)地址结构
基本分页存储的逻辑地址结构如下图所示:
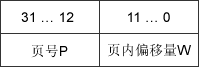
地址结构包含两部分:前一部分为页号P,后一部分为页内偏移量W。地址长度为32 位,其中0-11位为页内地址,可以计算得每页大小为4KB;12-31位为页号,地址空间最多允许有2^20页。
(3)页表
为了便于在内存中找到进程的每个页面所对应的物理块,系统为每个进程建立一张页表,记录页面在内存中对应的物理块号,页表一般存放在内存中。
在配置了页表后,进程执行时,通过查找该表,即可找到每页在内存中的物理块号。可见,页表的作用是实现从页号到物理块号的地址映射,如下图所示:
基本分页存储的地址转换机构
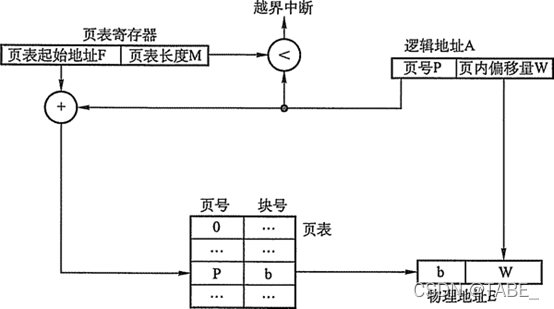
设页面大小为L,逻辑地址A到物理地址E的变换过程如下:
- 计算页号P(P=A/L)和页内偏移量W (W=A%L)。
- 比较页号P和页表长度M,若P >= M,则产生越界中断,否则继续执行。
- 页表中页号P对应的页表项地址 = 页表起始地址F + 页号P * 页表项长度,取出该页表项内容b,即为物理块号。
- 计算E=b*L+W,用得到的物理地址E去访问内存。
基本分页存储的缺点
- 每次访存操作都需要进行逻辑地址到物理地址的转换,地址转换过程必须足够快,否则访存速度会降低。
- 为每个进程引入了页表,用于存储映射机制,页表不能太大,否则内存利用率会降低。
快表TLB
由上面介绍的地址转换过程可知,若页表全部放在内存中,则存取一个数据或一条指令至少要访问两次内存:一次是访问页表,确定所存取的数据或指令的物理地址,第二次才根据该地址存取数据或指令。显然,这种方法比通常执行指令的速度慢了一半。为此,在地址转换过程中增设了一个具有并行查找能力的高速缓冲存储器——快表(TLB),用来存放当前访问的若干页表项,以加速地址变换的过程。与此对应,主存中的页表也常称为慢表, 配有快表的地址变换过程如下图所示:
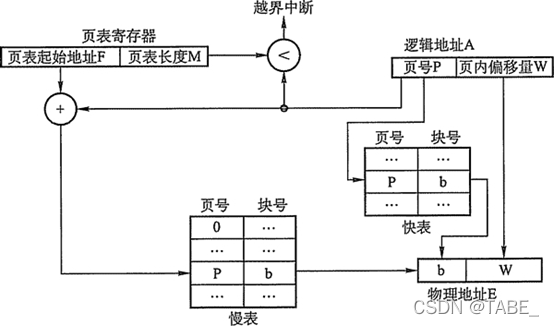
在具有快表的分页机制中,地址的变换过程如下:
- CPU给出逻辑地址后,由硬件进行地址转换并将页号送入TLB,并将此页号与TLB中的所有页号进行比较。
- 如果找到匹配的页号,说明所要访问的页表项在快表中,则直接从中取出该页对应的页框号,与页内偏移量拼接形成物理地址。这样,存取数据仅一次访存便可实现。
- 如果没有找到,则需要访问主存中的页表,在读出页表项后,应同时将其存入快表,以便后面可能的再次访问。但若快表已满,则必须按照一定的算法对旧的页表项进行替换。
快表的有效性是基于著名的局部性原理,这在后面的虚拟内存中将会具体讨论。
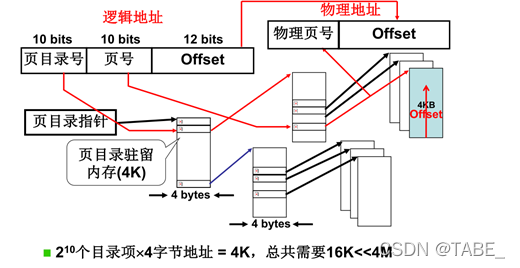
多级页表
linux从最初的2级页表,到3级页表(x86支持物理地址扩展),再到4级页表(64cpu)。
为了提高内存空间利用率,页应该小。但是页小了,页表就大。既要连续又要让页表占用内存少,可以通过多级页表来建立上一级页表,用于存储页表的映射关系。
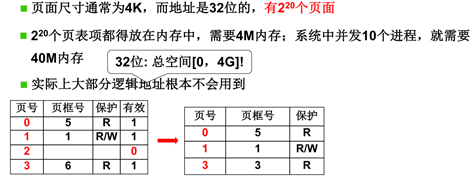
为什么 Linux 系统默认页大小是 4KB
- 过小的页面大小会带来较大的页表,增加寻址时的查找速度和额外开销。
- 过大的页面大小会浪费内存空间,造成内存碎片,降低内存的利用率。
上个世纪在设计内存页大小时充分考虑了上述的两个因素,最终选择了 4KB 的内存页作为操作系统最常见的页大小。
基本分段式存储管理
基本分页管理方式是从计算机的角度考虑设计的,以提高内存的利用率,提升计算机的性能, 且分页通过硬件机制实现,对用户完全透明。
基本分段式管理方式则按照用户进程中的自然段划分逻辑空间。例如,用户进程由主程序、两个子程序、栈和一段数据组成,于是可以把这个用户进程划分为5个段,每段从0 开始编址,并分配一段连续的地址空间(段内要求连续,段间不要求连续,因此整个作业的地址空间是二维的)。
地址结构
分段存储的逻辑地址结构由段号S与段内偏移量W两部分组成,如下图所示:
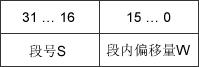
在段段式存储管理方式中,段号和段内偏移量必须由用户显示提供,在髙级程序设计语言中,这个工作由编译程序完成。
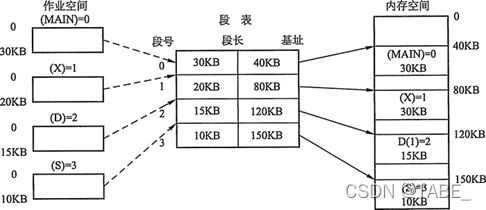
段表
每个进程都有一张逻辑空间与内存空间映射的段表,段表中每一个段表项对应进程的一个段,段表项记录该段在内存中的起始地址和段的长度。段表项的内容如下图所示:

在配置了段表后,执行中的进程可通过查找段表,找到每个段所对应的内存区。可见,段表用于实现从逻辑段到物理内存区的映射,如下图所示:
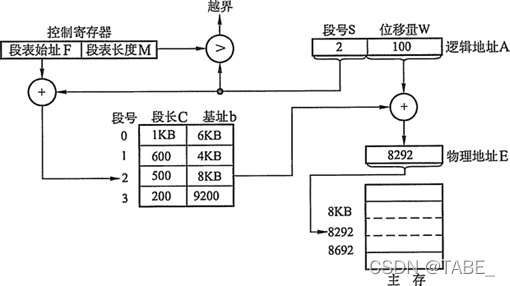
基本分段存储的地址转换机构
分段系统的地址变换过程如下图所示。为了实现进程从逻辑地址到物理地址的变换功能,在系统中设置了段表寄存器,用于存放段表始址F和段表长度M。其从逻辑地址A到物理地址E之间的地址变换过程如下:
- 从逻辑地址A中取出前几位为段号S,后几位为段内偏移量W。
- 比较段号S和段表长度M,若S多M,则产生越界中断,否则继续执行。
- 段表中段号S对应的段表项地址 = 段表起始地址F + 段号S *段表项长度,取出该段表项的前几位得到段长C。若段内偏移量>=C,则产生越界中断,否则继续执行。
- 取出段表项中该段的起始地址b,计算 E = b + W,用得到的物理地址E去访问内存。
基本段页式存储管理
基本分页存储管理能有效地提高内存利用率,而基本分段存储管理能反映程序的逻辑结构。如果将这两种存储管理方法结合起来,就形成了基本段页式存储管理方式。
地址结构
在基本段页式系统中,作业的逻辑地址分为三部分:段号、页号和页内偏移量,如下图:

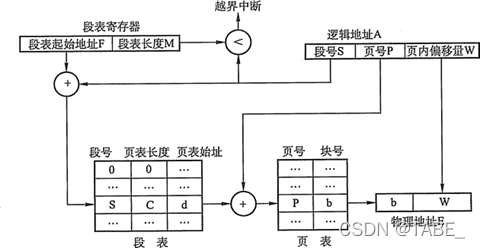
基本段页存储的地址转换机构
为了实现地址变换,系统为每个进程建立一张段表,而每个分段有一张页表。段表表项中至少包括段号、页表长度和页表起始地址,页表表项中至少包括页号和块号。此外,系统中还应有一个段表寄存器,指出作业的段表起始地址和段表长度。
注意:在一个进程中,段表只有一个,而页表可能有多个。
段页存储的地址变换过程如下:
- 在被调进程的PCB中取出段表始址F和段表长度M,装入段表寄存器。
- 段号S与段表长度M比较,若S大于等于M,发生地址越界中断,停止调用,否则继续。
- 由段号S结合段表始址F求出页表始址d和页表大小C。
- 页号P与段表的页表大小C比较,若P大于等于C,发生地址越界中断,停止调用,否则继续。
- 由页表始址d结合段内偏移量W求出存储块号b。
- b&W,即得物理地址E。














 3111
3111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









