







一、图像分类
图像本身是一堆数字,分布非常复杂。
传统机器学习:人工设计算法,对输入进行降维。(特征工程)
深度学习:端到端的分类器(特征学习)
卷积神经网络
Transformer
模型设计和模型学习
AlexNet: 开创,使在GPU上进行训练成为可能
VGG: 5*5的kernel->3*3
GoogleNet: inception
残差学习
Resnet:跳跃连接(?),模型集成的方式
神经结构搜索
基于强化学习,搜索表现最佳的网络
Transformer
Vision Transformer
Swin-Transformer
ConvNeXt
将Swin-Transformer的要素迁移到卷积神经网络
轻量化网络
inception模块
bottleneck模块
可分离卷积:dwconv深度可分离卷积,如mobilenet(加入残差等)
分组卷积:ResNeXt
二、Vision Transformer
注意力机制
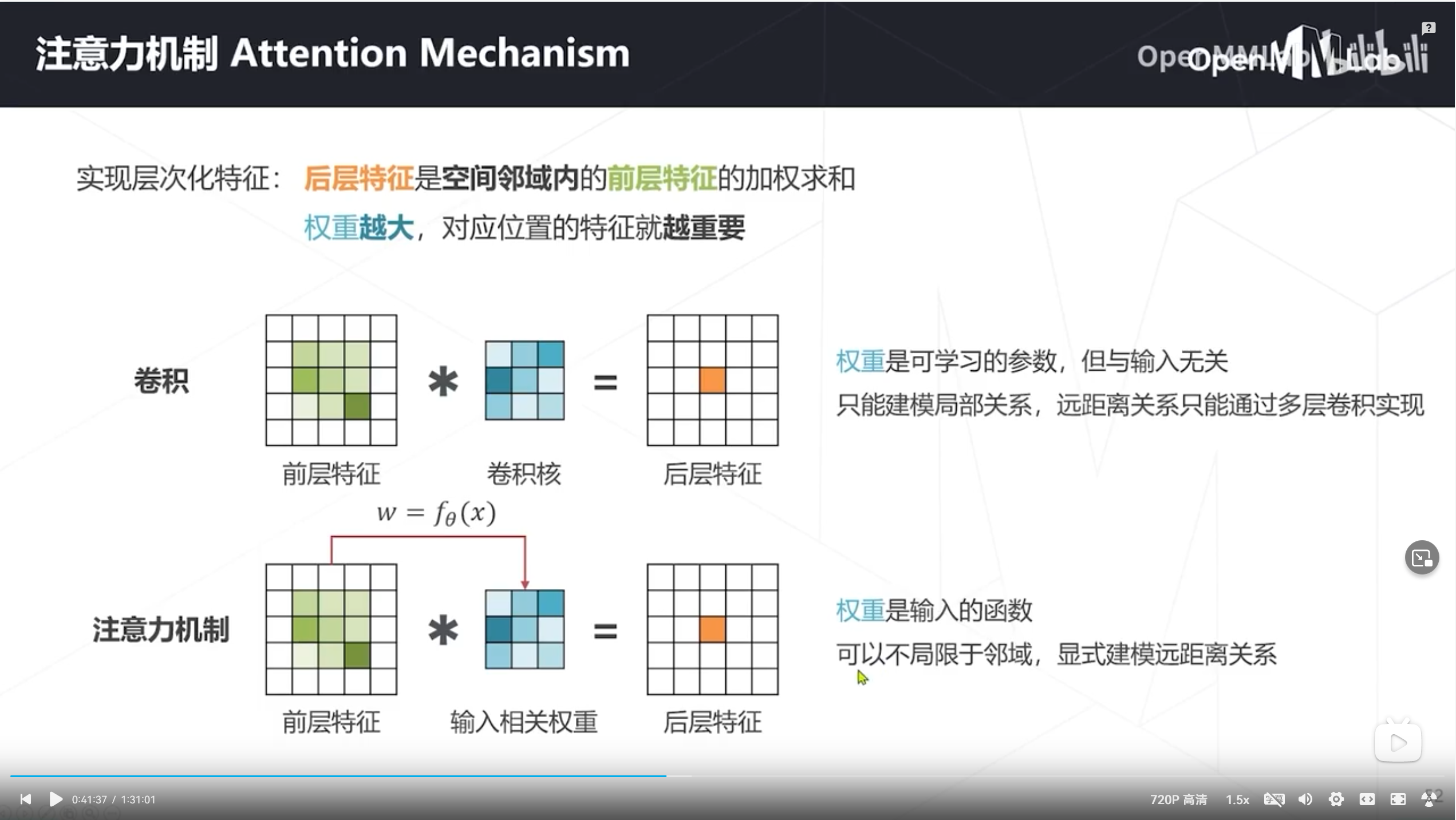
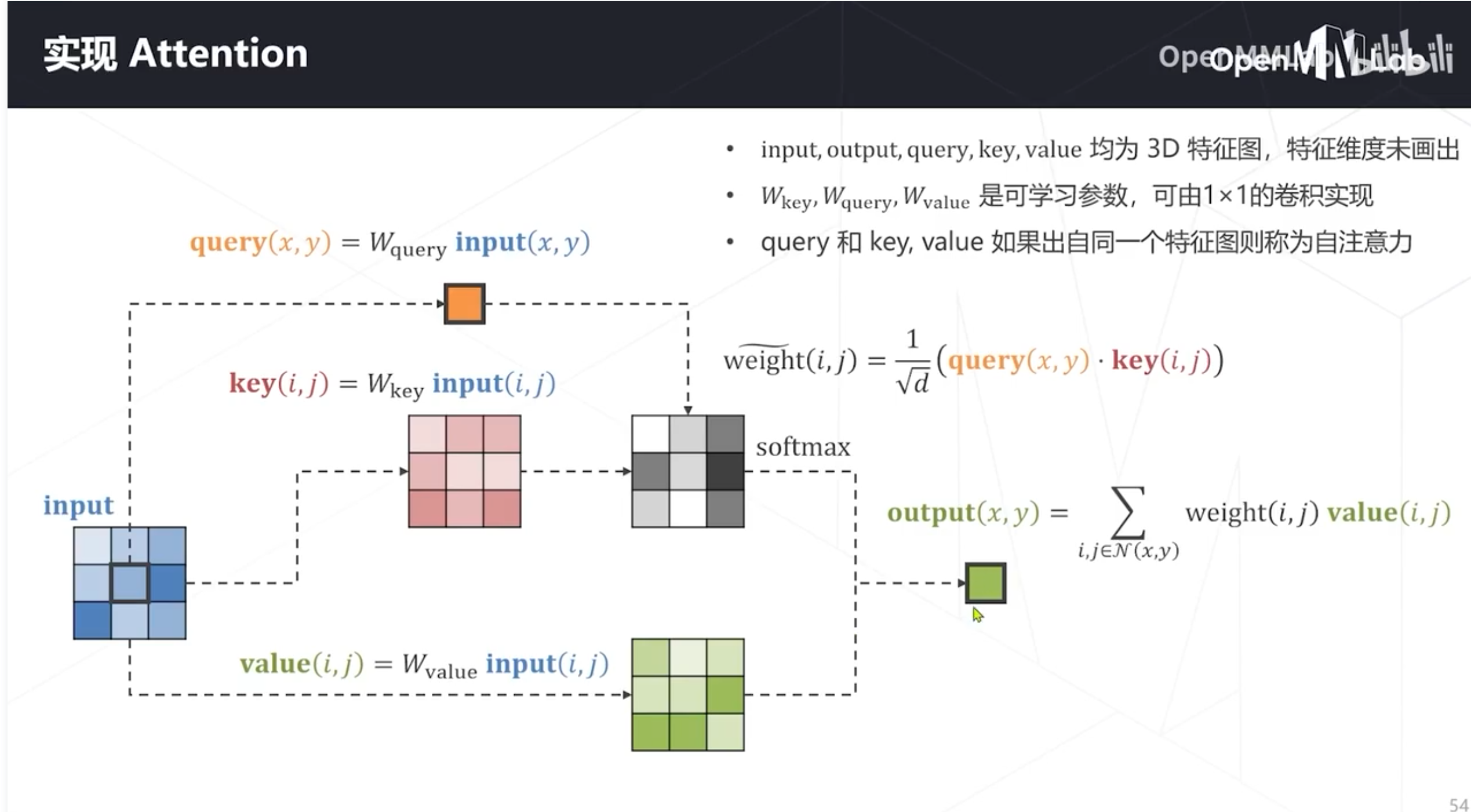
三、模型学习
监督学习 数据集标注成本
自监督学习 辅助任务
交叉熵损失cross-entropy loss
学习率与优化器策略
凯明初始化等
学习率下降(退火)
学习率warm up
linear scanning rule(经验性的)batch_size和lr同倍数
自适应梯度算法
Adam/AdamW
正则化和weight decay
早停 early stopping
EMA 模型权重平均
数据增强 Data Augmentation
几何变换
色彩变换
随机遮挡
组合图像mixup
cutmix等
标签平滑 label smoothing
dropout
自监督学习
基于代理任务 relative location
基于对比学习 simCLR info NCE loss
基于掩码学习 Masked autoencoders MAE
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









