







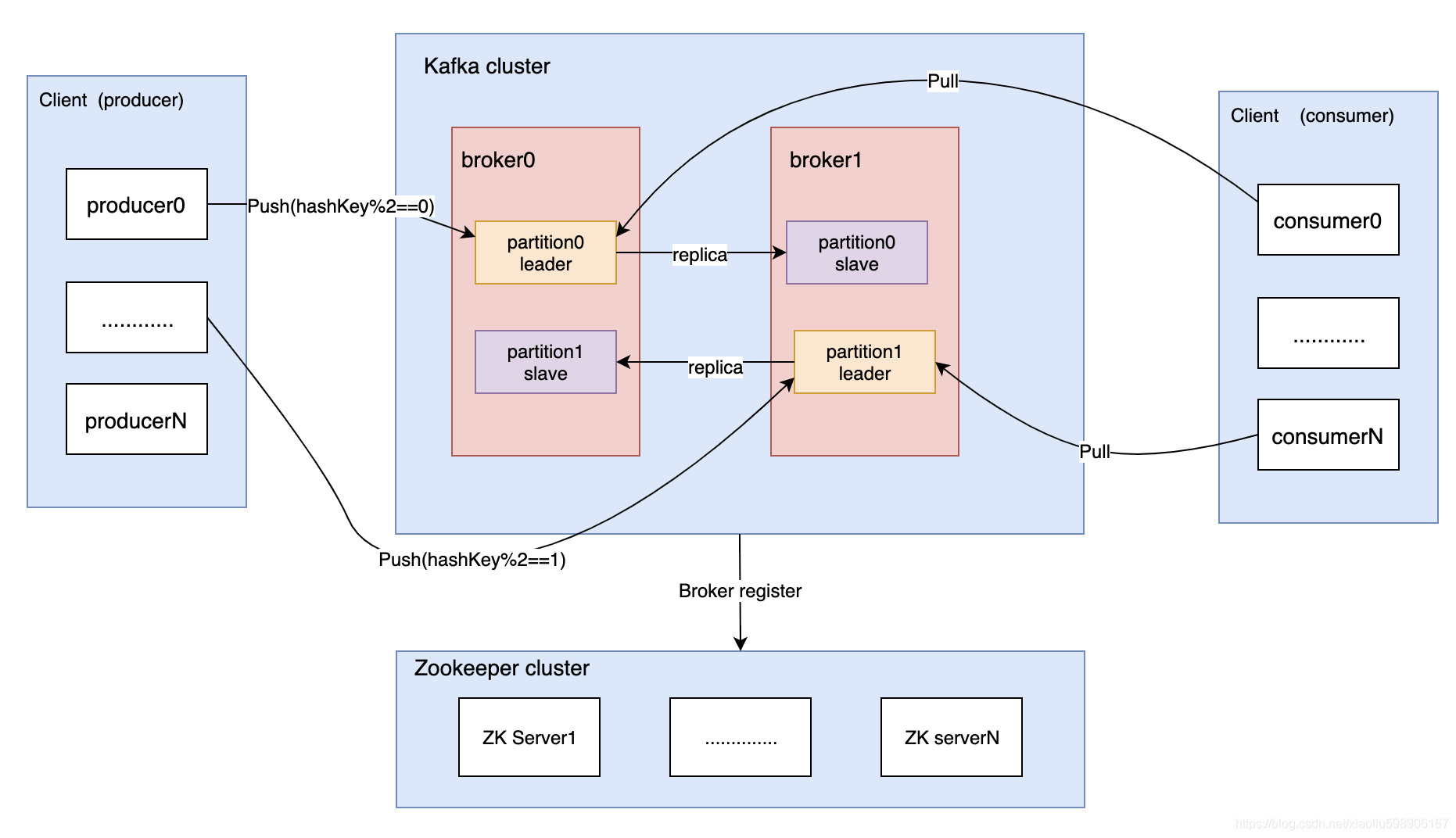
kafka基本概念
Kafka是一种高吞吐量、分布式、基于发布/订阅的消息系统。
基本概念:
-
broker:就是一个kafka服务,可以有多个broker形成集群
-
toptic:每个broker里面可以有若干个toptic(类似于标签,将消息分类)
-
partition:一个toptic里面可以有多个分区,分区是物理存储,消息会被追加到分区log末端
-
副本:一个分区可以有多个副本(类似于主从复制,副本因子一直在同步主分区的数据,如果主分区宕了,其中副本因子升级为主分区)
-
Zookeeper:保存着集群 broker、 topic、 partition等meta 数据;另外,还负责broker故障发现, partition leader选举,负载均衡等功能
-
Consumer Group:消费者分组,每个Consumer必须属于一个group
-
offset:消息在日志中的位置,可以理解是消息在partition上的偏移量(每个消费者组维护自己对某个分区的offset)
kafka的安装部署
1、单机安装部署
kafka依赖zookeeper,而ZooKeeper服务器是用Java创建的,它运行在JVM之上。
所以,安装kafka之前先安装Java、zookeeper。

2、kafka集群
搭建kafka集群也很简单,如果要搭建三台集群。在一台机子上安装部署zookeeper,然后三台机子都安装部署上kafka,注意每个kafka的【server.properties】不一样, 主要修改以下四个地方:
#节点id
broker.id=0
#配置本机IP和端口
listeners=PLAINTEXT://10.1.0.8:9092
#配置kafka日志记录位置
log.dirs=/data/kafka-logs
#配置kafka连接zookeeper的地址
zookeeper.connect=10.1.0.9:2181
最后每台机器上启动kafka即可【参考】
springboot整合kafka
1、pom依赖
引入spring-kafka依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.10.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>
2、配置文件
kafka相关配置,也可以写配置类,此处以配置文件示例:
properties版本:
#============== kafka ===================
# 指定kafka 代理地址,可以多个
#spring.kafka.bootstrap-servers=123.xxx.x.xxx:19092,123.xxx.x.xxx:19093,123.xxx.x.xxx:19094
spring.kafka.bootstrap-servers=114.116.115.153:9092
#=============== producer生产者 =======================
spring.kafka.producer.retries=0
# 每次批量发送消息的数量
spring.kafka.producer.batch-size=16384
# 缓存容量
spring.kafka.producer.buffer-memory=33554432
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#=============== consumer消费者 =======================
# 指定默认消费者group id,如果消费的时候不指定消费者组,则以这个默认的
spring.kafka.consumer.group-id=test-app
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=100ms
# 指定消息key和消息体的编解码方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
#spring.kafka.consumer.bootstrap-servers=192.168.8.111:9092
#spring.kafka.consumer.zookeeper.connect=192.168.8.103:2181
#指定tomcat端口
server.port=8063
yaml版本:
spring:
# KAFKA
kafka:
#指定kafka 代理地址,可以多个
#bootstrap-servers: 123.xxx.x.xxx:19092,123.xxx.x.xxx:19093,123.xxx.x.xxx:19094
bootstrap-servers: 114.116.115.153:9092
#=============== producer生产者配置 =======================
producer:
retries: 0
# 每次批量发送消息的数量
batch-size: 16384
# 缓存容量
buffer-memory: 33554432
# ָ指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
#=============== consumer消费者配置 =======================
consumer:
#指定默认消费者的group id
group-id: test-app
#earliest
#当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
#latest
#当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
#none
#topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: latest
enable-auto-commit: true
auto-commit-interval: 100ms
#指定消费key和消息体的编解码方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
3、controller
package com.tzq.test.controller;
import com.tzq.test.utils.KafkaUtil;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/kafka")
public class KafkaController {
@Autowired
KafkaUtil kafkaUtil;
/**
* 向kafka发送消息
* @return
*/
@GetMapping("/sendMsg")
public String sendMessageToKafka(@RequestParam String topic,@RequestParam String key,@RequestParam String msg) {
//kakfa的推送消息方法有多种,可以采取带有任务key的,也可以采取不带有的(不带时默认为null)
String tetTopic = "testTopic";
kafkaUtil.send(topic, key, msg);
return "hi guy!";
}
}
4、kafka核心工具类
package com.tzq.test.utils;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
@Component
public class KafkaUtil {
@Autowired
private KafkaTemplate<String, Object> kafkaTemplate;
private final Logger logger = LoggerFactory.getLogger(KafkaUtil.class);
/**
* 向卡夫卡发送消息
* @param topic 主题
* @param taskid key
* @param jsonStr 消息字符串
*/
public void send(String topic, String taskid, String jsonStr) {
//发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, taskid, jsonStr);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
//推送成功
public void onSuccess(SendResult<String, Object> result) {
logger.info(topic + " 生产者 发送消息成功:" + result.toString());
}
@Override
//推送失败
public void onFailure(Throwable ex) {
logger.info(topic + " 生产者 发送消息失败:" + ex.getMessage());
}
});
}
/**
* 消费kafka里面的消息
* @param record
*/
//下面的主题是一个数组,可以同时订阅多主题,只需按数组格式即可,也就是用“,”隔开
@KafkaListener(topics = {"testTopic2"},groupId = "testGroup1")
public void receive(ConsumerRecord<?, ?> record){
logger.info("消费得到的消息1---key: " + record.key());
logger.info("消费得到的消息1---value: " + record.value().toString());
}
/**
* 消费kafka里面的消息
* @param record
*/
//下面的主题是一个数组,可以同时订阅多主题,只需按数组格式即可,也就是用“,”隔开
@KafkaListener(topics = {"testTopic2"},groupId = "testGroup2")
public void receive2(ConsumerRecord<?, ?> record){
logger.info("消费得到的消息2---key: " + record.key());
logger.info("消费得到的消息2---value: " + record.value().toString());
}
}
@KafkaListener(topics = {“testTopic2”},groupId = “testGroup1”)
可以指定监听的toptic(可同时监听多个),可以设置guoupid
FAQ
1、kafka的消息被消费后会删除吗?
rabbitmq的消息消费后会被删除,而kafka的消息消费后不会删除,每个消费者组记录并维护自己对订阅toptic的分区里消息的offset,这样就可以知道自己读到了哪位置的数据了。kafka的消息只有到过期时间或者磁盘满时才会被删除。

2、kafka如何保证消息的有序性
kafka只能保证一个分区内是有序的,不能保证整个toptic有序。
如果想要保证有序,方案:
- topic内只建一个分区
- 将有顺序的消息发送时设置的key要一样,这样经过hash算法,确保相同key的消息一定会存到同一个分区内
3、一条消息知道要被发送到哪个分区?
默认情况下,Kafka根据传递消息的key来进行分区的分配,即hash(key) % numPartitions。
key为null时,会从缓存中取分区id或者随机取一个
4、单播和广播
单播:一个消费者组订阅toptic
广播:多个消费者组订阅同一个toptic,每个消费者组都会消费这个toptic的消息(因为每个消费者组都会记录并维护自己对订阅toptic的分区里消息的offset,这样不同消费者组对同一个toptic消息的消费就互不影响了)
5、消费者组内的消费者数量最大为多少?
消费者组内的消费者数量建议小于toptic的分区数量,因为toptic中的一个分区只能被同一个消费者组内某一个消费者消费,如果消费者数量大于分区数量,则一定有消费者空闲了!
6、一个消费者组可以订阅多个toptic吗?
一个消费者组可以订阅多个toptic!
反之亦可,一个toptic可以被多个消费者组订阅,即实现了广播的功能!
7、分区的副本数目最大多少?
分区的副本数目最大按机器数量来,即broker数量














 19万+
19万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









