







windows10环境安装spark-3.0.3-bin-hadoop2.7和遇到的问题
前言
星光不问赶路人,时光不负有心人。
刚刚接触spark,安装环境就装了两天,目前遇到的问题,下面一一会有说明,希望能给到大家帮助,其中会借鉴其他大佬博客,有的可能忘记标记引用,如看到,可以联系本人,进行及时更改。
一、spark及其相关的软件
1.JDK安装(不会的网上有很多)本人安装的是Java 1.8.0_291
2.下载Hadoop_2.7.1
官网链接:http://hadoop.apache.org/releases.html
3.下载下载hadooponwindows-master.zip【能支持在windows运行hadoop的工具】
(后面会有这些软件的百度链接)
4.下载对应的scala(这里用的是Scala 2.12.10)
官网链接:https://www.scala-lang.org/download/scala2.html
5.去官网下载spark-3.0.3-bin-hadoop2.7,这里注意一定要注意spark、hadoop、scala的版本
官网链接:http://spark.apache.org/downloads.html
下面是本人下载的软件,有需要的可以自己提取,版本已经标注,最好去官网下载,主要是为了自己解决问题。
链接:https://pan.baidu.com/s/1nWI3wxe_cTi8usDW_cxqBA
提取码:c6xs
二、具体步骤
1.安装hadoop2.7.1
https://blog.csdn.net/qq_38025219/article/details/87365281
(我也是参考CSDN上大佬的文章)
下载hadoop2.7.1tar.gz,并解压到你想要的位置,我放在了D盘里面

下面开始配置环境变量:
1.windows10环境变量配置:
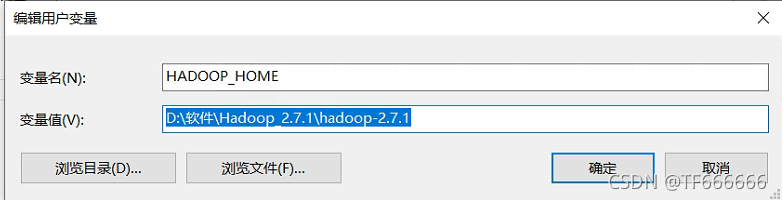
2.后面接着配置path,将hadooop的bin目录加入

3.修改需要配置的文件(hadoop)
编辑“D:\软件\Hadoop_2.7.1\hadoop-2.7.1\etc\hadoop”下的core-site.xml文件,将下列文本粘贴进去,并保存;
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/dev/hadoop-2.7.1/workplace/tmp</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/D:/dev/hadoop-2.7.1/workplace/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
编辑“D:\软件\Hadoop_2.7.1\hadoop-2.7.1\etc\hadoop”目录下的mapred-site.xml(没有就将mapred-site.xml.template重命名为mapred-site.xml)文件,粘贴一下内容并保存;
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/D:/dev/hadoop-2.7.1/workplace/data</value>
</property>
</configuration>
编辑“D:\软件\Hadoop_2.7.1\hadoop-2.7.1\etc\hadoop”目录下的yarn-site.xml文件,粘贴以下内容并保存;
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
编辑“D:\软件\Hadoop_2.7.1\hadoop-2.7.1\etc\hadoop”目录下的hadoop-env.cmd文件,将JAVA_HOME用 @rem注释掉,编辑为JAVA_HOME的路径,然后保存;
@rem set JAVA_HOME=%JAVA_HOME%
set JAVA_HOME=set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_291
4.替换文件(hadoop)
下载到的hadooponwindows-master.zip,解压,将bin目录(包含以下.dll和.exe文件)文件替换原来hadoop目录下的bin目录;
5.在cmd中进行运行
运行cmd窗口,执行“hdfs namenode -format”;
运行cmd窗口,切换到hadoop的sbin目录,执行“start-all.cmd”,它将会启动以下进程。
(启动以后会打开新的四个窗口,并且都是运行状态,具体图可以看上边我在CSDN中引用大佬的博客)
到目前来说hadoop基本就搭建完了,现在需要测试一下
根据上面你的core-site.xml的配置,接下来你就可以通过:hdfs://localhost:9000来对hdfs进行操作了
1.创建目录(这里要用管理员身份运行cmd窗口)
C:\WINDOWS\system32>hadoop fs -mkdir hdfs://localhost:9000/user/
C:\WINDOWS\system32>hadoop fs -mkdir hdfs://localhost:9000/user/wcinput
2.上传数据到目录(这里的.txt文件需要自己在对应文件夹创建,不创建会报错,错误说该文件夹中没有该文件,.txt文件内容自己任意写)
C:\WINDOWS\system32>hadoop fs -put D:\file1.txt hdfs://localhost:9000/user/wcinput
C:\WINDOWS\system32>hadoop fs -put D:\file2.txt hdfs://localhost:9000/user/wcinput
查看你所导入的文件:
hadoop fs -ls hdfs://localhost:9000/user/wcinput
(具体图可以看上边我在CSDN中引用大佬的博客)
这样hadoop的搭建就已经完成了
2.安装scala(这里用的是Scala 2.12.10)
https://www.runoob.com/scala/scala-install.html
(官网的教程已经很详细了windows10)
在官网进行下载,进行环境变量的配置,配置好以后在窗口输入cmd,然后输入scala,然后回车,环境变量就配置完了,你就可以看到对应的版本

这时scala就已经配置好了。
3.安装spark-3.0.3-bin-hadoop2.7
首先下载就是一个大问题,可能公司的网有限,还是在家里的网进行下载的,也下了2个多小时,虽然不大,但速度太慢,后面我会把相关的软件用百度网盘链接形式,需要的自己进行保存下载
官网下载网址:http://spark.apache.org/downloads.html
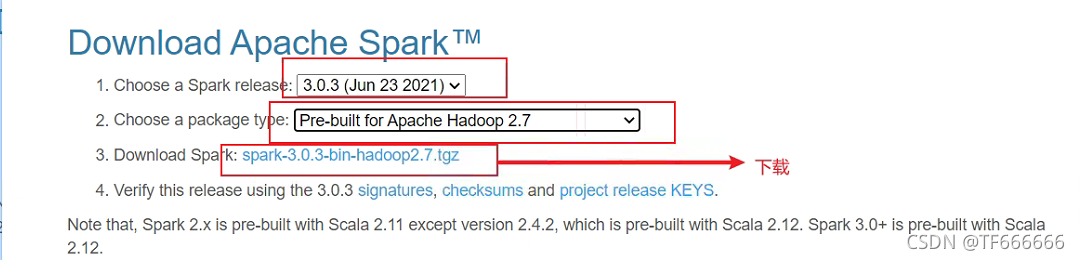
这是我在官网下载的截图
(同样在CSDN上也有相关大佬的配置方法)
大佬的博客
https://blog.csdn.net/weixin_51432117/article/details/115098331
1.配置环境
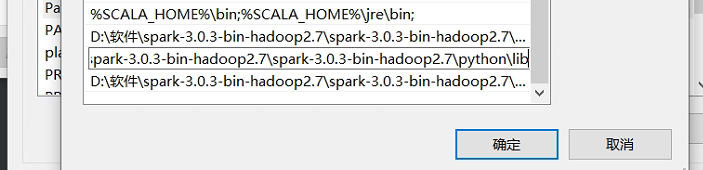
D:\软件\spark-3.0.3-bin-hadoop2.7\spark-3.0.3-bin-hadoop2.7\bin
D:\软件\spark-3.0.3-bin-hadoop2.7\spark-3.0.3-bin-hadoop2.7\python\lib
D:\软件\spark-3.0.3-bin-hadoop2.7\spark-3.0.3-bin-hadoop2.7\python
最好把python的路径也配置上,后面可能会用到。
配置完了以后就可以在cmd中输入:spark-shell
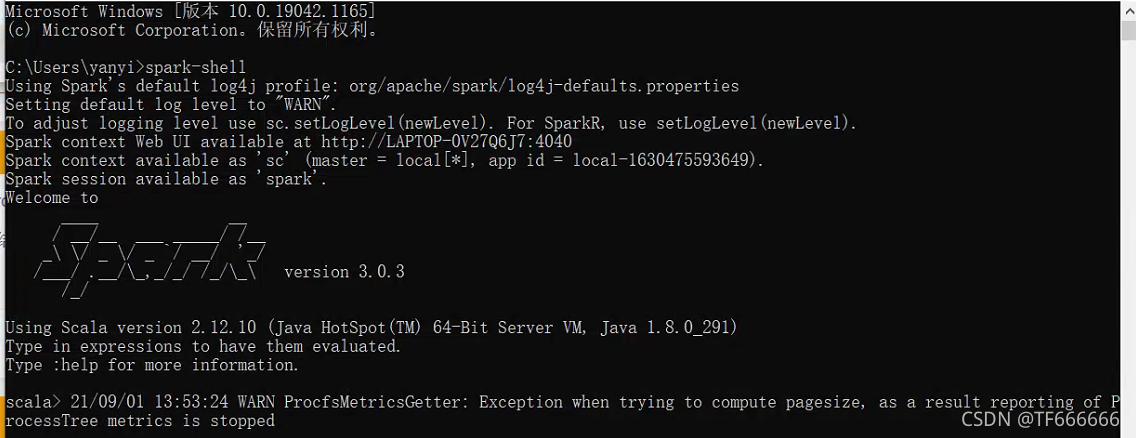
这样就成功了,如果有一些问题,可以看我上面链接大佬遇到的问题,几乎都可以解决了,解决不了的可以找度娘。

这个问题我也去查过,不受后面使用的影响,所以,后面如果遇到,在进行补充,不过网上有很多解决办法,对于我来说,只要使用不影响到我,我就无所谓。
4.测试python模块
重点来了,本人是做AI的,所以重点在这里,这里是最大的坑,解决这些问题网上资料是在太少。
首先安装pyspark
很多人是pip install pyspark
这里本人不建议,如果你成功了就无所谓了
因为你下载的spark-3.0.3-bin-hadoop2.7里面有专门的模块是pyspark,所以你将本模块放到你对应的python中就可以
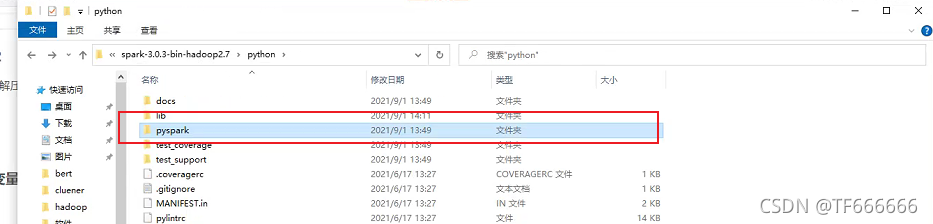
你将pyspark复制,然后复制到你python环境里面的lib–>sit-packages,复制到sit-packages文件夹即可,如果你用的是虚拟环境,你用的是miniconda还是anaconda你找到对应的虚拟环境,路径都是相似的,放到相同的文件夹里面。

这样重新启动你的pycharm就可以了。
下面就是测试遇到的问题了,要知道安装没有安装好,就要用代码进行测试,开始展示:
新建一个python文件(这里注意你的python环境)
from pyspark import SparkConf
from pyspark.sql import SparkSession
import traceback
appname = "test" # 任务名称
master = "local" # 单机模式设置
'''
local: 所有计算都运行在一个线程当中,没有任何并行计算,通常我们在本机执行一些测试代码,或者练手,就用这种模式。
local[K]: 指定使用几个线程来运行计算,比如local[4]就是运行4个worker线程。通常我们的cpu有几个core,就指定几个线程,最大化利用cpu的计算能力
local[*]: 这种模式直接帮你按照cpu最多cores来设置线程数了。
'''
spark_driver_host = "10.0.0.248"
try:
# conf = SparkConf().setAppName(appname).setMaster(master).set("spark.driver.host", spark_driver_host) # 集群
conf = SparkConf().setAppName(appname).setMaster(master) # 本地
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
words = sc.parallelize(
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"
])
counts = words.count()
print("Number of elements in RDD is %i" % counts)
sc.stop()
print('计算成功!')
except:
sc.stop()
traceback.print_exc() # 返回出错信息
print('连接出错!')
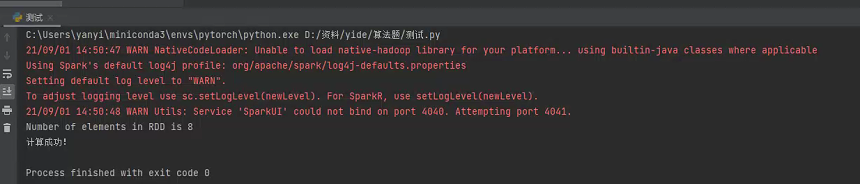
有警告,但不受影响,如果想解决,就百度吧
这样就成功了。
如果遇到运行时如果报错sc没有被定义,你需要把下面代码复制到测试代码中
from pyspark import SparkContext
from pyspark import SparkConf
conf = SparkConf().setAppName("test")
sc = SparkContext(conf=conf)
如果你有遇到的是Could not find valid SPARK_HOME while searching这个问题
搜索时找不到有效的SPARK_HOME
可以参考一下链接:https://www.pianshen.com/article/82521714106/
如果你遇到的是ModuleNotFoundError: No module named 'py4j’是这个问题,其实就是上面Could not find valid SPARK_HOME while searching这个问题,只要按照这个方法机型解决就可以了。
解决方法,这里用的是pycharm
在pycharm中打开设置,Settings–>Project:xxx–>Project Structure,点击+号,添加pyspark zip包:
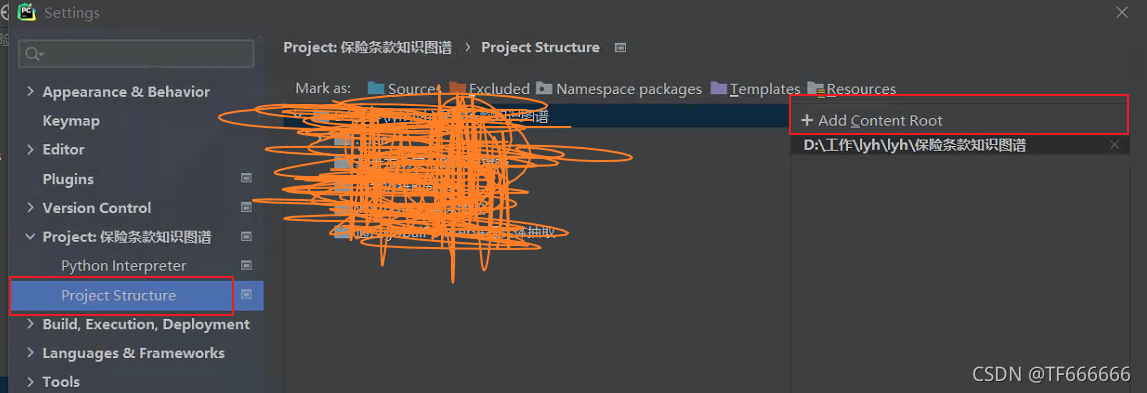
在加号那里面把py4j和pyspark的压缩包进行添加即可
更详细资料上边有链接,链接里面有视频,非常详细。
后面还需要配置一下系统变量:
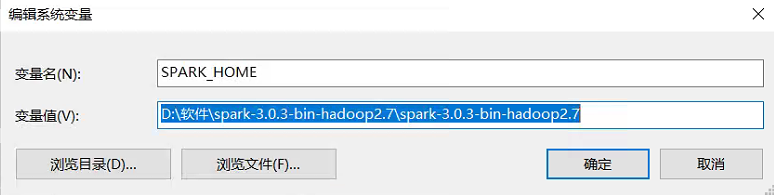
按照自己的路径进行配置即可,没有就新建。
到这里我们我们就解决完了,如果你遇到新的问题可以留言,同时感谢各位大佬的文章,本文章不作为商用,只是供给大家作为一个参考,如果涉及侵权,可以联系本人,本人进行核实下架处理。
参考资料
https://blog.csdn.net/weixin_39750084/article/details/84453711
https://www.pianshen.com/article/82521714106/
https://blog.csdn.net/qq_38025219/article/details/87365281
https://www.runoob.com/scala/scala-install.html















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









