






JDK1.8常见的Stream流
背景:
本篇内容主要是在工作之后遇到的一些用stream流之后及其方便的一些方法,整理了一些,希望能帮助大家,特此记录。
Stream定义
java8之后,新增的Stream,配合同版本出现的 Lambda,给我们操作集合(Collection)提供了极大的便利。
那么,stream流是什么?
Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。
Stream可以由数组或集合创建,对流的操作分为两种:
中间操作,每次返回一个新的流,可以有多个。
终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值。
另外,Stream有几个特性:
- stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
- stream不会改变数据源,通常情况下会产生一个新的集合或一个值。
- stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
常用方法
1. 遍历: forEach遍历
用来遍历流中的数据
注:是一个终结方法,遍历之后就不能继续调用Stream流中的其他方法
public class Test1 {
public static void main(String[] args) {
List<String> list = Arrays.asList("字节","网易","百度", "美团", "阿里", "字节");
//获取一个Stream流
Stream<String> stream = list.stream();
//使用Stream流的方法forEach对stream流中的数据遍历
stream.forEach(System.out::println);
}
}
输出结果:
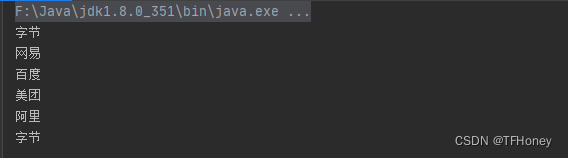
2. 过滤: fifter筛选
public class Test1 {
public static void main(String[] args) {
List<String> list = Arrays.asList("字节","网易","百度", "美团", "阿里巴巴", "字节");
//获取一个Stream流
Stream<String> stream = list.stream();
//使用Stream流的方法forEach对stream流中的数据遍历
stream.forEach(System.out::println);
//单条件过滤
Stream<String> stream1 = stream.filter((String name) -> {
return name.startsWith("字");
});
//多条件过滤
List<String> stream2 = stream.filter((String name) -> {
if(name.length()>=3 && name.equals("阿里巴巴")){
return true;
}
return false;
}).collect(Collectors.toList());
//遍历stream1
stream1.forEach(System.out::println);
//输出stream2
System.out.println(stream2);
}
}
3. 去重: distinct去重
public class Test1 {
public static void main(String[] args) {
List<String> list = Arrays.asList("字节","网易","百度", "美团", "阿里巴巴", "字节");
//获取一个Stream流
Stream<String> stream = list.stream();
//去重
List<String> stream1 = stream.distinct().collect(Collectors.toList());
//输出stream1
System.out.println(stream1);
}
}
输出结果:

4. 截取: limit截取
public class Test1 {
public static void main(String[] args) {
List<String> list = Arrays.asList("字节","网易","百度", "美团", "阿里巴巴", "字节");
//获取一个Stream流
Stream<String> stream = list.stream();
//截取stream流的前2个元素
list = stream.limit(2).collect(Collectors.toList());
//输出stream1
System.out.println(list);
}
}
输出结果:
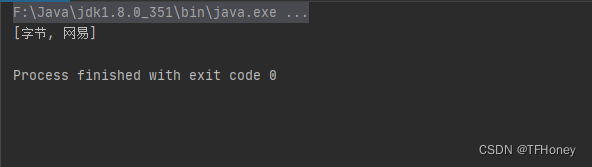
5. 转换: List结构转换Map结构
import lombok.Data;
@Data
public class Company {
private String name;
private int salary;
public Company(String name, int salary) {
this.name = name;
this.salary = salary;
}
public Company() {
}
}
public class Test1 {
public static void main(String[] args) {
List<Company> testList = new ArrayList<Company>();
testList.add(new Company("字节",23000));
testList.add(new Company("网易",24000));
testList.add(new Company("百度",22000));
//根据姓名转map,map的key为name
Map<String, Company> nameMap= testList.stream().collect(Collectors.toMap(Company::getName, Company -> Company));
System.out.println(nameMap);
}
}
注意:转换可能遇到的问题 https://www.cnblogs.com/xiaoyuicom/p/15386981.html
6. 排序: sorted排序
public class Test1 {
public static void main(String[] args) {
List<Company> testList = new ArrayList<Company>();
testList.add(new Company("字节",23000));
testList.add(new Company("网易",24000));
testList.add(new Company("百度",22000));
//根据工资进行排序 并返回list
List<String> list = testList.stream().sorted(Comparator.comparing(Company::getSalary).reversed()).map(Company::getName).collect(Collectors.toList());
System.out.println(list);
}
}
输出结果:
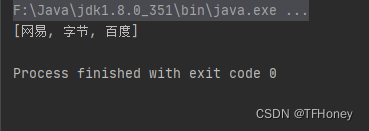
7. 转换: 列表Object对象转列表String
public class Test1 {
public static void main(String[] args) {
List<Company> testList = new ArrayList<Company>();
testList.add(new Company("字节",23000));
testList.add(new Company("网易",24000));
testList.add(new Company("百度",22000));
//获取公司名称集合
List<String> list = testList.stream().map(Company::getName).collect(Collectors.toList());
System.out.println(list);
}
}
输出结果:
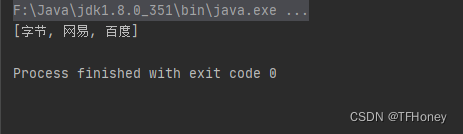
8. 转换: 列表Object对象转列表Object
public class Human {
private String name;
private int salary;
public Human(String name, int salary) {
this.name = name;
this.salary = salary;
}
public Human() {
}
}
public class Test1 {
public static void main(String[] args) {
List<Company> testList = new ArrayList<Company>();
testList.add(new Company("字节",23000));
testList.add(new Company("网易",24000));
testList.add(new Company("百度",22000));
//转化新的对象
List<Human> humanList= testList.stream().map(s -> {
return new Human(s.getName(), s.getSalary());})
.collect(Collectors.toList());
System.out.println(humanList);
}
}
值得注意的是:map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
.map(Company::getName) 表示映射为一个String 返回
.map(s -> { return new Human(s.getName(), s.getSalary());}) 表示映射为一个新的对象 返回
顺序流和并行流
每个Stream都有两种模式:顺序执行和并行执行。
//顺序流:
List <Person> people = list.getStream.collect(Collectors.toList());
//并行流:
List <Person> people = list.getStream.parallel().collect(Collectors.toList());
//可以看出,要使用并行流,只需要.parallel()即可
顾名思义,当使用顺序方式去遍历时,每个item读完后再读下一个item。
而使用并行去遍历时,数组会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。
并行流原理:
List originalList = someData;
split1 = originalList(0, mid);//将数据分小部分
split2 = originalList(mid,end);
new Runnable(split1.process());//小部分执行操作
new Runnable(split2.process());
List revisedList = split1 + split2;//将结果合并
性能:如果是多核机器,理论上并行流则会比顺序流快上一倍。
以下是借用他人的一个测试两者性能的Demo.
package com.lambda.stream;
import java.util.stream.IntStream;
public class TestPerformance {
public static void main(String[] args) {
long t0 = System.nanoTime();
//初始化一个范围100万整数流,求能被2整除的数字,toArray()是终点方法
int a[]=IntStream.range(0, 1_000_000).filter(p -> p % 2==0).toArray();
long t1 = System.nanoTime();
//和上面功能一样,这里是用并行流来计算
int b[]=IntStream.range(0, 1_000_000).parallel().filter(p -> p % 2==0).toArray();
long t2 = System.nanoTime();
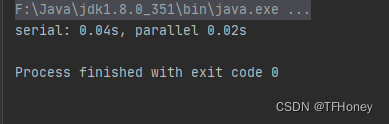
//结果是serial: 0.04s, parallel 0.02s,证明并行流确实比顺序流快
System.out.printf("serial: %.2fs, parallel %.2fs%n", (t1 - t0) * 1e-9, (t2 - t1) * 1e-9);
}
}
输出结果:
大功告成!希望对大家有帮助!














 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









