







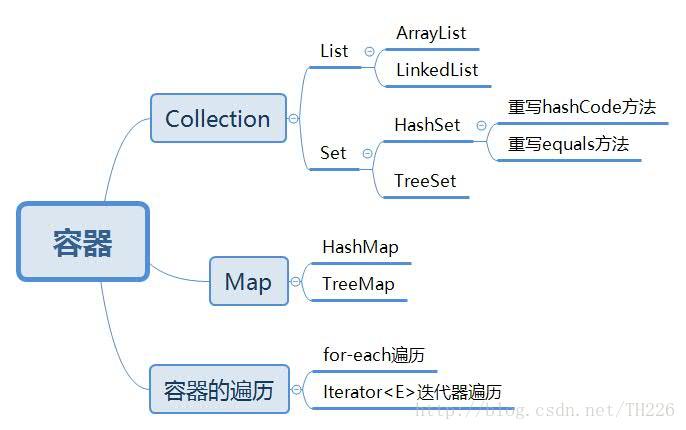
容器:在java中,如果有一个类专门用来存放其他类的对象,这个类就叫做容器,或者叫集合,集合就是将若干性质相同或者相近的类的对象组合在一起而形成一个整体。
boolean add(Object obj):向容器中添加指定的元素
Iterator iterator():返回能够遍历当前集合中所有元素的迭代器
Object[] toArray():返回包含此容器中所有元素的数组。
Object get(int index):获取下标为index的那个元素
Object remove(int index):删除下标为index的那个元素
Object set(int index,Object element):将下标为index的那个元素置为element
Object add(int index,Object element):在下标为index的位置添加一个对象element
Object put(Object key,Object value):向容器中添加指定的元素
Object get(Object key):获取关键字为key的那个对象
int size():返回容器中的元素数其中map、set、和List中的方法还是有所区别的,具体用法此处不做太多说明三种容器接口的方法详解:http://blog.csdn.net/lushuaiyin/article/details/7381478/
1.ArrayList区分元素顺序,允许包含重复的元素,输出的时候按照插入顺序输出
public class JavaCollection {
public static void main(String[] args) {
/**
* 容器循环输出
* 1.获取迭代器
* 2.使用.hasNext()方法实现循环
* 3.调用.next()方法获取值
*/
List<Integer> list = new ArrayList<Integer>();
list.add(10);
list.add(11);
list.add(44);
list.add(33);
list.add(33);
Iterator<Integer> iterator = list.iterator();//获取容器的迭代器
while(iterator.hasNext()){
Integer value = iterator.next();//获取下一个元素
System.out.println(value);
}
}
}
输出结果:
10
11
44
33
33 详解:http://blog.csdn.net/i_lovefish/article/details/8042883
public class JavaCollection {
public static void main(String[] args) {
LinkedList<Integer> linkList = new LinkedList<Integer>();
linkList.add(5);
linkList.add(2);
linkList.add(3);
linkList.add(1);
linkList.add(4);
System.out.println("链表的第一个元素是 : " + linkList.getFirst());
System.out.println("链表最后一个元素是 : " + linkList.getLast());
//循环获取容器中元素
for (Integer integer: linkList) {
System.out.println(integer);
}
}
}
输出结果
链表的第一个元素是 : 5
链表最后一个元素是 : 4
5
2
3
1
4Set容器不区分元素顺序,不允许出现重复元素,Set容器可以与数学中的集合相对应:相同的元素不会被加入
1.HashSet
HashSet与HashMap实现机制相同,HashSet 本身就采用 HashMap 来实现的,系统通过Hash函数决定参数的存储位置
2.TreeSet
TreeSet容器特殊,元素放进去的时候自动按照升序排列,输出的时候按照升序输出
public class JavaCollection {
public static void main(String[] args) {
/**
* 容器循环输出
* 1.获取迭代器
* 2.使用.hasNext()方法实现循环
* 3.调用.next()方法获取值
*/
Set<Integer> set = new TreeSet<Integer>();
set.add(10);
set.add(11);
set.add(44);
set.add(33);
set.add(33);
Iterator<Integer> iterator = set.iterator();//获取容器的迭代器
while(iterator.hasNext()){
Integer value = iterator.next();//获取下一个元素
System.out.println(value);
}
}
}
输出结果:
10
11
33
44 映射中不能包含重复的键值,每个键最多只能映射一个值,否则会出现覆盖的情况(后面的value值会将前面的value值覆盖掉)
1.HashMap:HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它 的值, 具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
HashMap中最重要的实现机制应该就是通过哈希函数获取参数的哈希值然后根据哈希值将参数存储,这又涉及到哈希值的求解以及
冲突的处理 ,通常来说哈希值求解最常用的方法是保留余数法,而处理冲突的方法则有:1.线性探测再散列法 2.平方探测散列3.拉链法
HashMap详解:http://blog.csdn.net/caihaijiang/article/details/6280251
public class JavaCollection {
public static void main(String[] args) {
Map<Integer, Integer> map = new TreeMap<Integer, Integer>();
map.put(1, 1);
map.put(2, 2);
map.put(5, 2);
map.put(3, 3);
map.put(3, 3);
map.put(5, 3);
for(Map.Entry<Integer, Integer> entry : map.entrySet()){
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue());
}
}
}
输出结果
key = 1, value = 1
key = 2, value = 2
key = 3, value = 3
key = 5, value = 3
public class JavaCollection {
public static void main(String[] args) {
Map<Integer, Integer> map = new LinkedHashMap<Integer, Integer>();
map.put(100, 1);
map.put(2, 2);
map.put(5, 2);
map.put(90, 3);
map.put(3, 3);
map.put(5, 3);
for(Map.Entry<Integer, Integer> entry : map.entrySet()){
System.out.println("key = " + entry.getKey() + ", value = " + entry.getValue());
}
Iterator<Integer> iterator = set.iterator();//获取容器的迭代器
while(iterator.hasNext()){
Integer value = iterator.next();//获取下一个元素
System.out.println(value);
}
}
}
输出结果:key = 100, value = 1
key = 2, value = 2
key = 5, value = 3
key = 90, value = 3
key = 3, value = 3List
1.ArrayList区分元素顺序,允许包含重复的元素,输出的时候按照插入顺序输出
2.LinkedList:LinkedList类是双向链表,链表中的每个节点都包含了对前一个和后一个元素的引用.
Set:不区分元素顺序,不允许出现重复元素,Set容器可以与数学中的集合相对应:相同的元素不会被加入
1.HashSet与HashMap实现机制相同,HashSet 本身就采用 HashMap 来实现的,系统通过Hash函数决定
参数的存储位置,输出顺序与输入顺序可能不同
2. TreeSet容器特殊,元素放进去的时候自然而然就有顺序了,输出的时候按照升序输出
Map<K,V> 映射:映射中不能包含重复的键值,每个键最多只能映射一个值,否则会出现覆盖的情况(后面的
value值会将前面的value值覆盖掉)
1.HashMap:HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以
直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
2.TreeMap:不能包含重复的键,每个键最多只能映射一个值,否则会出现覆盖的情况,输出时会按照键的大小升序输出
3.LinkedHashMap:是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,
它还可以按读取顺序来排列.















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









