






在分布式场景中开发大型MoE模型时,面临着巨大的通信开销问题。例如,使用流行的模型和框架时,仅MoE层的设备间通信就可能占据整个模型执行时间的47%。
如图1(a)所示,几个流行的MoE模型在前向过程中,设备间的通信占总执行时间的47%。在分布式环境中,执行MoE层涉及数据接收、专家计算和数据传输,如图1(b)所示。为了减少通信开销,一种有效的策略是将通信与专家计算重叠。这种方法将输入数据分成较小的数据块,使通信和计算阶段能够重叠。在图1(b)的例子中,接收到的输入数据被分成两块,这种粗粒度的重叠相比非管道化执行减少了总的执行时间。
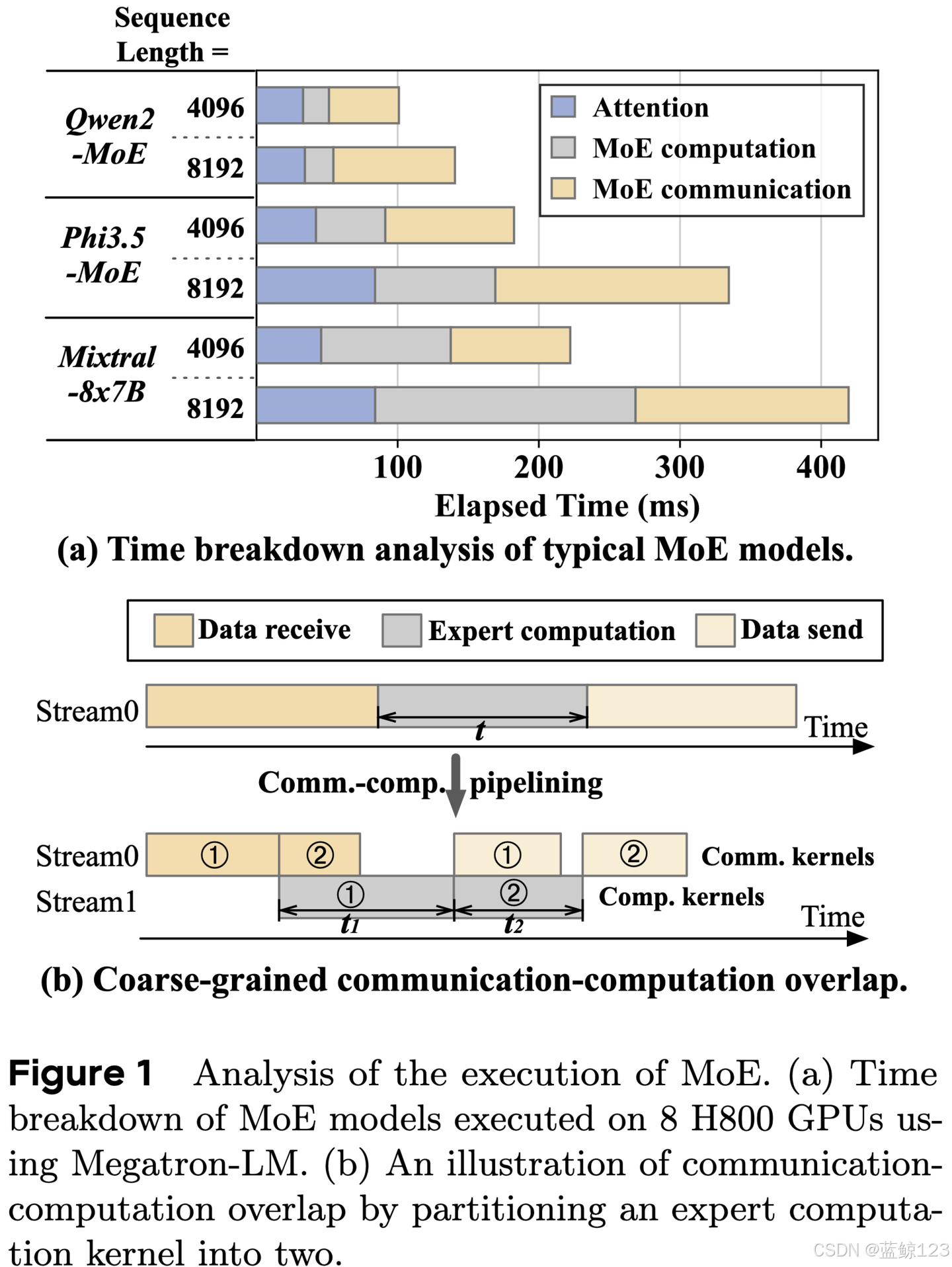
通信与计算的重叠仍存在两个主要问题:第一,随着数据块规模的缩小,计算效率降低,导致GPU计算资源的利用不足。此外,粗粒度的划分在通信的初始和结束阶段会导致不可避免的GPU空闲时间。第二,由于MoE的动态特性,专家在运行时的输入形状各异,给GPU带来了多样化的通信和计算负担。将通信和计算任务封装在不同的内核中,限制了对硬件资源的控制,导致内核性能不稳定,阻碍了通信与计算的无缝重叠。为了应对这些挑战,我们提出了一种名为Comet的系统,它通过两项关键设计实现了通信与计算的细粒度重叠:1)通过识别MoE中通信和计算操作之间的复杂数据依赖关系,优化计算通信管道的结构;2)**通过动态分配GPU线程块来平衡通信和计算工作负载,提高延迟隐藏效率。Comet通过分析通信和计算操作之间的共享数据缓冲区(称为共享张量),消除了通信和计算之间的粒度不匹配,从而实现细粒度的重叠。**为了确保资源分配精确和有效隐藏延迟,Comet在融合的GPU内核中集成了通信和计算任务。通过线程块的专门化,Comet将通信对计算性能的影响隔离,保持了高计算效率。通过调整分配给每个工作负载的线程块数量,Comet有效平衡了通信和计算延迟,减少了重叠中的气泡现象。
与现有的最先进MoE系统相比,Comet在典型的MoE层上实现了1.96倍的加速,对于端到端的MoE模型执行(如Mixtral-8x7B、Qwen2-MoE、Phi3.5-MoE等),平均实现了1.71倍的加速。
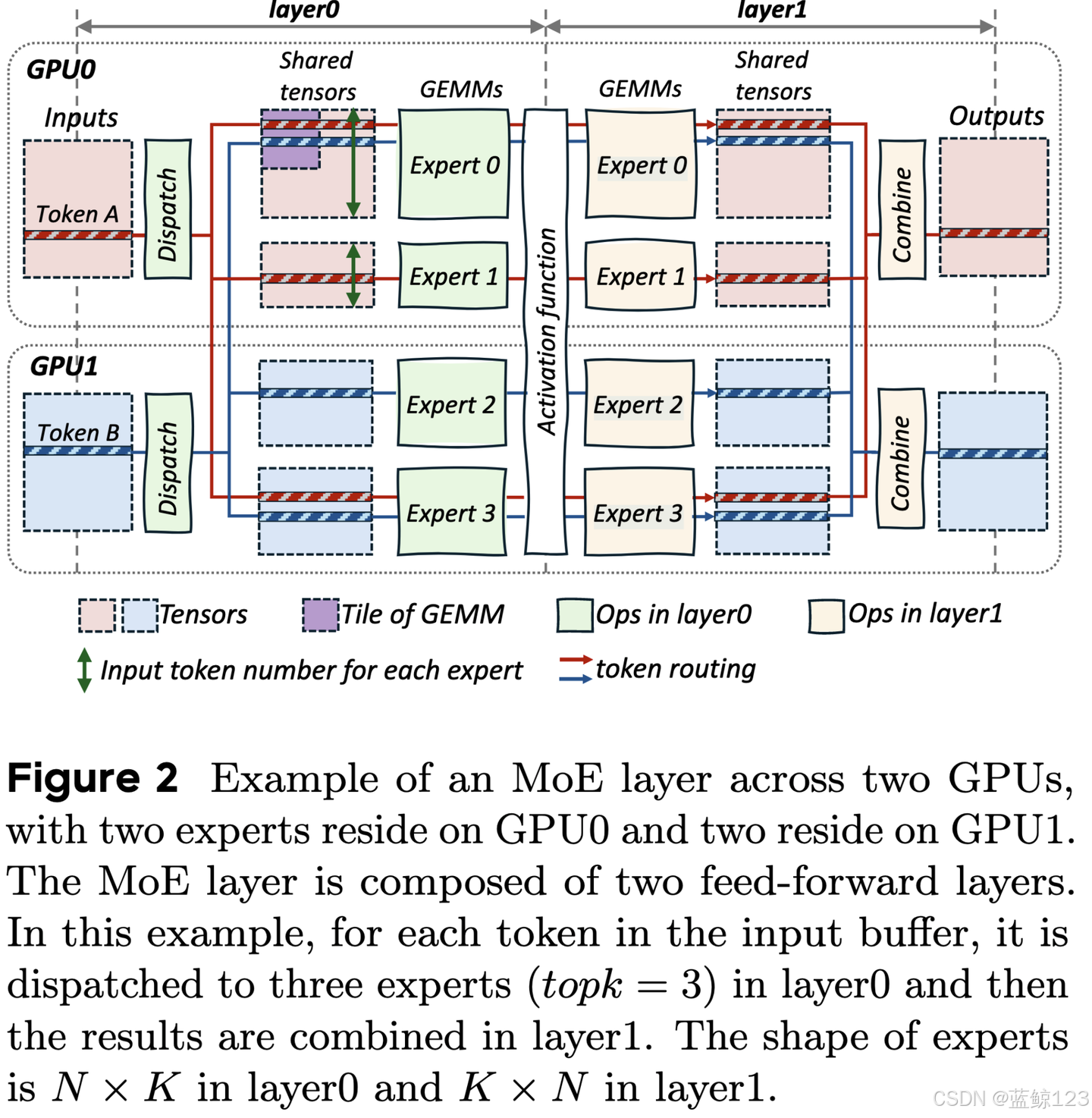
MoE主要采用两种并行策略:专家并行和张量并行。在专家并行中,不同专家的权重分布在不同的GPU上,每个专家的权重保持完整。输入数据会被传输到对应专家的GPU上。图2展示了一个专家并行的例子,专家0和专家1位于GPU0上,其他专家位于GPU1上。相比之下,张量并行会将所有专家的权重沿隐藏维度进行划分,每个GPU上存储所有专家权重的一部分。在实际部署MoE模型时,通常会采用专家并行和张量并行相结合的混合并行方法,以实现高效执行。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











