







代码块
import requests
import time
from tqdm import tqdm
from bs4 import BeautifulSoup # 解析网页数据
def get_content(target):
req=requests.get(url=target)
req.encoding = 'utf-8'
html = req.text
bf = BeautifulSoup(html,'lxml')
texts = bf.find('div',id='content')
content=texts.text.strip().split('\xa0'*4)
return content # 返回的为字符数组
if __name__ == '__main__':
server = "https://www.vbiquge.com" # 新笔趣阁总网址
target = "https://www.vbiquge.com/15_15338" # 诡秘之主 小说目录
book_name = './WebSpider/诡秘之主.txt'
rep = requests.get(url = target)
rep.encoding = 'uft-8' # 指定文档为 utf-8 编码
html = rep.text
# 获取 HTML 后进行解析
bs = BeautifulSoup(html,'lxml') # 使用 lxml 解析 HTML
# print(bs.prettify()) # 格式化输出 HTML 页面
# 查找 id 属性为 list 的 div 标签,在符合条件的 div 标签提取出 标签 a
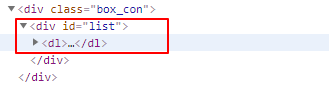
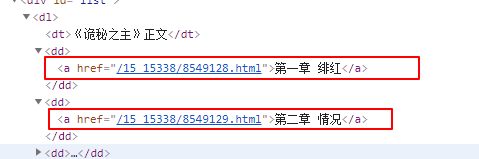
chapters = bs.find('div',id='list').find_all('a')
with tqdm(chapters,desc='NUM',ncols=80) as tq:
# 进度条向下滚动(多个进度条)是因为太长了,使用ncols参数规定滚动条长度即可
for chapter in tq:
href = chapter.get('href')
chapter_name = chapter.string
url = server + href
content = get_content(url)
with open(book_name,'a',encoding='utf-8') as f:
f.write(chapter_name)
f.write('\n')
f.write('\n'.join(content))
# 以换行符 将content字符数组连接生成新字符串
f.write('\n')
代码剖析
字符 \xa0
\xa0 是不间断空白符
我们通常所用的空格是 \x20 ,是在标准ASCII可见字符 0x20~0x7e 范围内。
而 \xa0 属于 latin1 (ISO/IEC_8859-1)中的扩展字符集字符,代表空白符nbsp(non-breaking space)。latin1 字符集向下兼容 ASCII ( 0x20~0x7e )。通常我们见到的字符多数是 latin1 的,比如在 MySQL 数据库中。

删除:.strip();分割:.split()
s.strip(rm) : 删除s字符串中开头、结尾处,位于 rm删除序列的字符,默认删除空白符(包括'\n', '\r', '\t', ' ')
split(rm)分隔后是一个列表,按 字符rm 进行分割,[0]表示取其第一个元素;

join()方法:
join(): 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串
解析库

find();find_all
chapters = bs.find('div',id='list').find_all('a')
传送门
Python3 网络爬虫(二):下载小说的正确姿势
Python 爬虫利器二之 Beautiful Soup 的用法
python中去掉字符串中的\xa0、\t、\n
python strip() 函数和 split() 函数的详解及实例
BeautifulSoup中find和find_all的使用
详解使用Python中的tqdm模块显示进度条
解决tqdm一直往下滚动的问题















 1151
1151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









