






Scala Parser原理介绍与源码分析
版权声明:本文为博主原创文章,未经博主允许不得转载。
手动码字不易,请大家尊重劳动成果,谢谢
为了不耽误大家的时间,重要的事情说三遍:
本文不讲Scala Parser的用法!!
本文不讲Scala Parser的用法!!
本文不讲Scala Parser的用法!!
今天这篇文章,我准备介绍一下Status Monad,奥不,应该是Scala Parser,Status Monad是啥,好吃不。Scala Parser是scala库中提供的一个词法解析器,学习过编译原理的同学对这个东西的作用应该已经了解了。
话说Scala Parser是我当初在学习scala的时候遇到的一个大老虎了,作为电子专业毕业的,当初为了搞懂Scala Parser是干啥的,我花两周时间看完了大半本《编译原理》,又上网看各种官方文档。不得不说,百度上基本搜不到Scala Parser的东西,所以这一次,我专门写这一篇文章来介绍下。
废话不多说,我们正式开始我们的Scala Parser旅程。
Scala Parser源码分析
对于scala parser而言,主要的类就一个:
package scala.util.parsing.combinator
trait Parsers {
type Elem
type Input = Reader[Elem]
sealed abstract class ParseResult[+T] {
def map[U](f: T => U): ParseResult[U]
def mapPartial[U](f: PartialFunction[T, U], error: T => String): ParseResult[U]
}
abstract class Parser[+T] extends (Input => ParseResult[T]) {
def apply(in: Input): ParseResult[T]
def flatMap[U](f: T => Parser[U]): Parser[U] = Parser{ in => this(in) flatMapWithNext(f)}
def map[U](f: T => U): Parser[U] = Parser{ in => this(in) map(f)}
def ~ [U](q: => Parser[U]): Parser[~[T, U]]
def ~> [U](q: => Parser[U]): Parser[U]
//以及下面一大堆奇形怪状的函数定义,想看自己开源码吧
从上面的摘录代码中,我们大致可以看到Scala Parser的几个核心特质和类
trait Parsers
首先我们先来看最外层的类trait Parser。这个类是所有Scala Parser类的基类,包括我们经常使用的RegexParsers:
trait RegexParsers extends Parsers
这个特质为我们提供了最基本的Parser环境,通过对其进行扩展,我们就可以衍生出各种各样的匹配方式,比如RegexParsers就引入了正则表达式的匹配。
sealed abstract class ParseResult[+T]
顾名思义,这个类就是用来表示转换结果的,并且它被sealed标记,表示它的所有子类都在这个文件里,这个关键字简直就是源码阅读者的福音:
case class Success[+T](result: T, override val next: Input) extends ParseResult[T]
sealed abstract class NoSuccess(val msg: String, override val next: Input) extends ParseResult[Nothing]
case class Failure(override val msg: String, override val next: Input) extends NoSuccess(msg, next)
case class Error(override val msg: String, override val next: Input) extends NoSuccess(msg, next)
这个类共有四个子类,并且只有三个是实体类。具体干啥的大家一看也就明白了吧。
abstract class Parser[+T]
重点来了,这个类简直就是一个神奇的存在。我们先来看一下它的类声明:
abstract class Parser[+T] extends (Input => ParseResult[T])
你看人家继承了啥东西,(Input => ParseResult[T])这个表达式是Function1[Input,ParseResult[T]]的语法糖,表明这个Parser类继承了一个函数,并且需要重写apply方法。学过scala的都知道apply方法就是为我们直接用括号来造语法糖的。
我们深入思考一个这个apply方法,它接受一个Input类型的输入,返回一个ParseResult[T]类型的输出,上面我们也看到了ParseResult[T]的几个子类,用来表示转换的结果。现在我们可以大胆猜测下,Parser类的apply方法就是实现了一个输入值的解析,并生成一个解析结果。
讲到这里,Scala Parser是不是就显而易见了,我们只用实现Parser的apply方法就能实现输入数据的解析了。既然Scala Parser是一个词法解析器,那我们就可以实现一个Json或者XML的解析器啊。是可以,想当初我为了读一个XML的注释和内容,花了一天写了一个XML解析器,可把我烦死了。但是我们要怎么来实现呢?直接重写apply方法,然后自己去读字符串吗?那还要Scala Parser干啥,一本《编译原理》不就搞定啦。
说道Scala Parser为我们提供的便利,那当然就是它的解析器组合能力了,它能把所有同一类型的Parser类实例以某种方式组合在一起,提供一系列DSL组合方法,让你可以清晰地定制你的解析器。下面我们就来详细分析一下它其中的原理。
Scala for语法糖介绍
在scala中,有些表达式长这个样子:
//看清楚了,带yield
for(a <- listA; b <- listB) {
yield (a, b)
}这个表达式返回了listA和listB的笛卡尔积。
其实这句话只是一句语法糖而已,它真正的实现是:
listA.flatMap(a -> listB.map(b -> (a, b)))不要怀疑,下面这个代码就是上边那个代码,一毛一样。
好了,语法糖介绍完毕,我们回到Scala Parser中来
Parser的组合
def flatMap[U](f: T => Parser[U]): Parser[U] = Parser{ in => this(in) flatMapWithNext(f)}
def map[U](f: T => U): Parser[U] = Parser{ in => this(in) map(f)}下面我们重点来看Parser类中的这两个方法。首先我们先看flatMap,这个方法会生成一个Parser的实例,这个实例接受一个in的入参,然后交给this的apply方法。之前我们介绍过了,apply会解析输入,然后生成一个ParseResult[T]。然后调用ParseResult[T]的flatMapWithNext方法,把faltMap的入参传进去了。
我们进入我们跟踪解析成功的路径,进入到Success类的flatMapWithNext方法中:
case class Success[+T](result: T, override val next: Input) extends ParseResult[T] {
def flatMapWithNext[U](f: T => Input => ParseResult[U]): ParseResult[U] = f(result)(next)
}我们可以很明显看到,这个函数就是把之前解析出来的结果和剩下的还没解析完的一部分结果应用到了f函数里,我们看一下f的类型:f: T => Parser[U],因为Parser[U]是Input => ParseResult[U]类型,所以f函数的类型就是T => Input => ParseResult[U],我们看到上面这个flatMapWithNext函数里,给f传入了上次解析的结果result,这个的用处后面再说。紧接着,把剩下的未解析的一部分输入交给了f。到这里,你可能已经明白了这个解析器的原理,那就是通过这种组合方式,跟链表一样一个一个函数进行解析,并把剩下的无法解析的部分交给后面的解析器。
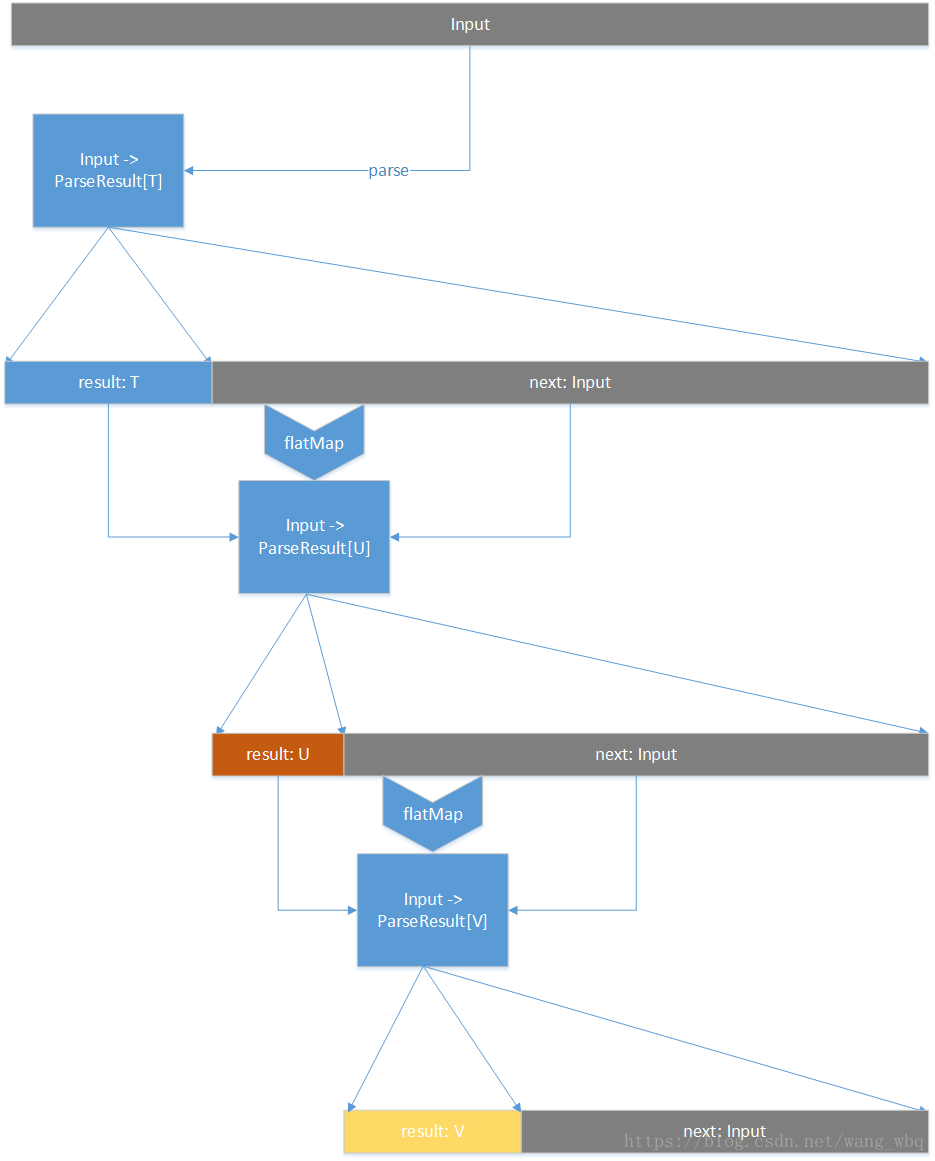
基本上就是图中画的这样了,不过关注下result引出的箭头,它实际上并没有进入到Input => ParseResult[U]函数中去,而是到了flatMap的第一个函数入参中去了。
最后,我们就可以看一下Scala Parser的Parser组合函数了:
def ~ [U](q: => Parser[U]): Parser[~[T, U]] = { lazy val p = q // lazy argument
(for(a <- this; b <- p) yield new ~(a,b)).named("~")
}
def ~> [U](q: => Parser[U]): Parser[U] = { lazy val p = q // lazy argument
(for(a <- this; b <- p) yield b).named("~>")
}
def <~ [U](q: => Parser[U]): Parser[T] = { lazy val p = q // lazy argument
(for(a <- this; b <- p) yield a).named("<~")
}
def ^^ [U](f: T => U): Parser[U] = map(f).named(toString+"^^")函数还有很多,我们举几个有代表性的讲一下。我们先看第一个方法~,它其实就是一个连接符号。看它的定义,加上我们之前说的for语法糖,我们可以看出a <- this这句话中的a,就是之前我们看到的result: T,也就是当前Parser类的解析结果会被导出到a变量中。同理可知,Parserp接受了当前类this的解析剩下的输入next: Input并且将其解析出的result: U导出到了b变量中。之后Scala Parser又定义了一个类~,其实就是一个Tuple2来保存这两个解析出的结果值,并将其命名为~。
解释了第一个方法的原理后,第二个和第三个方法的原理就很显而易见了:~>这个像态射一样的方法,跟它毛关系没有,它就是匹配this和p,然后只保留p的解析结果,而将this的解析结果直接丢弃。<~这个函数同理,就是把p的解析结果丢弃,只保留this的解析结果。
第四个方法看着就简单是吧,就是把之前已经解析好的类型为T的结果转换为类型为U的类上,仅仅是一个直接对解析结果的转换。
到这里,Scala Parser的主要内容已经讲完了,不知道大家看懂没有。因为这些内容涉及到函数式编程的相关知识,还涉及到Status Monad这个东西,着实会让人十分费解。由于本文不是专门来介绍Status Monad,因此对其中的原理思想也没有过多的阐述,如果读者有兴趣,欢迎进入到函数式编程这个大坑里来~~~














 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









