






算法day5
- 哈希表理论基础
- 242.有效的字母异位词
- 349 两个数组的交集
-
- 两数之和
- 202 快乐数
哈希表理论基础
哈希表是什么?
哈希表又称散列表,是一种数据结构,特点是数据元素的关键字与其存储地址直接相关。那这种相关怎么描述,这就引出了哈希函数。
哈希函数是什么?
就是一个函数,y=f(x),x就是关键字,y就是其存储地址,f就是函数的映射。看下面图中有个H(key)=key%13,模13就是函数映射,h就是存储地址,key就是关键字x。
我也喜欢把这种称为映射方式。

哈希表底层
从上面图就可以看出来,就可以理解为数组
哈希冲突
通过上图还可以发现一个问题,对于不同的关键字,计算出来的存储地址可能相同,比如14%13=1,那就存放在1的位置,后面1这个元素也计算存储地址1%13=1,也应该存放在1这个位置。但是发现这个位置已经有元素了,这种现象就叫做哈希冲突。这两个关键字用专业名词来说就叫做同义词。
这种现象是需要处理的,发生冲突的元素我们总得找地方存对吧。
哈希冲突处理
方法有好几种,我介绍常用的。
1.拉链法
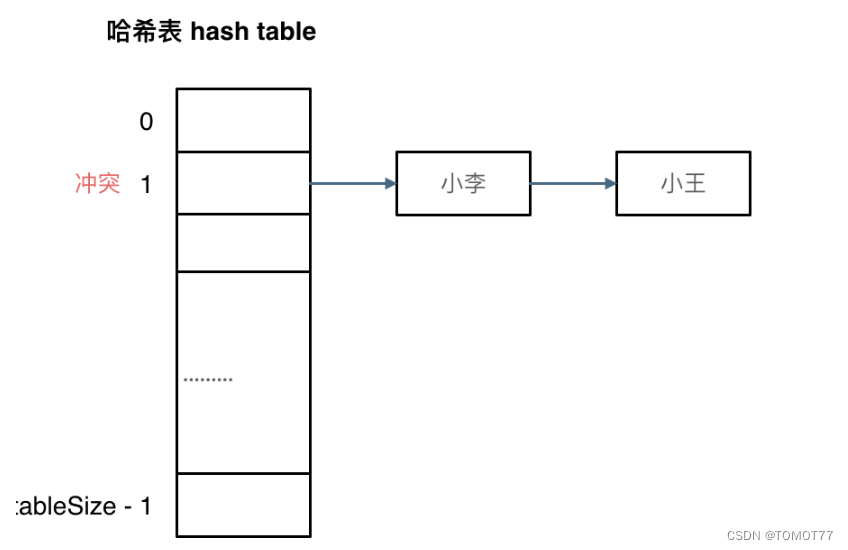
就是采用链表的方式,发生冲突了,我就把它挂在这个位置的链尾。
2.线性探测法
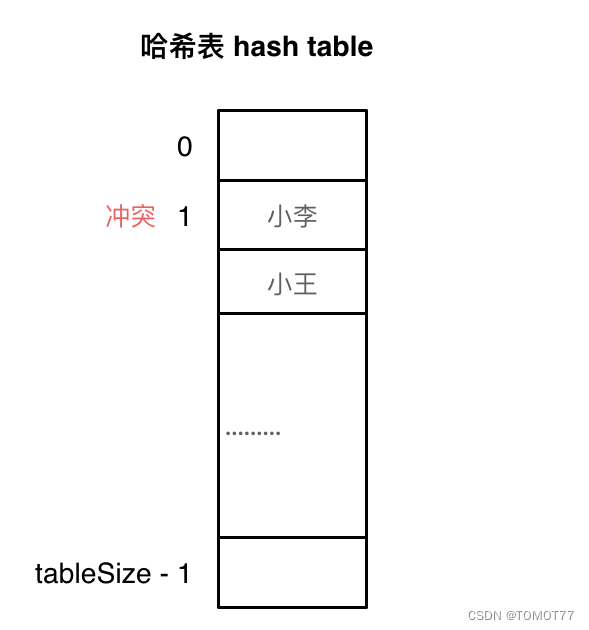
1这个位置有小李了,但是小王也是该存在这里,但是慢了,那就顺位往后面的空格放。
这种位置慢了就顺位往后面找空位的方法就叫线性探测法。
在go语言中的使用
1:在go语言中map是内置的,但set并不是内置的,但是这里可以直接用map来模拟set的行为。go语言中的内置map就是用于存储键值对,例如map[string]int,key为string,value为int。
2:set怎么模拟,这样:map[T]bool就可以实现,T是集合元素的数据类型,bool就是判断元素是否在集合中。
go语言中使用的常见问题(我认为搞懂这个会在写题的时候清醒)
1.怎么创建一个哈希表
2.访问一个不存在的key时会发生什么,是报错还是什么?
3.创建的map有什么特性
4.map的底层是什么?是哈希表还是数组?那哈希表的底层又是什么?
5.res:=make(map[string]int)和res:=make(map[string]int,n)有什么区别,各自有什么好处?
6.这个n有什么含义,是代表了什么?是map的容量?还是哈希表维护的底层数组的容量?
7.如果我这个n分配的过多,会有什么问题吗?会出现我创建数组一样,多的地方都是零值吗?
回答:
1.用make,比如res:=make(map[string]int),或者,res:=make(map[string]int,n),
2.在go语言中并不会报错,当访问一个不存在的key时,只会返回value的默认值,int就是0,bool就是false。(这个性质在做题的时候常用)
3.自动扩容机制。
4.map的底层是哈希表,哈希表是一种使用哈希函数来计算存储位置的数据结构,可以实现快速查找、删除、插入等操作,简单来说就是使用键值对访问。哈希表的底层是数组,这个数组通常被称为桶数组。
5.res := make(map[string]int)创建map时,没有指定预分配空间,这种情况下,GO运行时会使用默认的大小来初始化map,这个默认大小足够小足以节省空间,足以用来处理小量的元素。如果后续需要更多空间,map会根据元素的个数进行自动扩容。所以res:=make(map[string]int)这种没有指定预分配空间也是高效且合理的。
res:=make(map[string]int,n),这就是预分配了空间。基本性质和上面没什么差别,直接来看看比上面好在哪里:扩容机制这么好的机制那肯定是有代价的,提前按需要分配空间,就能减少扩容的次数,进而提高性能。
6.这个n仅仅只代表了预分配的空间,也就是map的容量。这个n和哈希表底层维护的数组容量没有关系。
7.要说真有什么问题那就是分配多了用不完就是浪费空间,不会有这种和数组那样的问题,实际上遍历map,只会遍历出有key的地方,不会输出默认值。
什么时候用哈希
哈希表解决的问题:用来快速判断一个元素是否出现在集合里。
有效的字母异位词
拿到这个题我有两个想法:1.暴力两个for,这样时间复杂度就o(n^2)了,但是好处是空间o(1),2.用哈希表,因为哈希表相比1有个好处,就是可以实现快速查找,暴力解的之所以慢就是因为花了大量的开销在查找。
哈希写法
版本1
思路:map[rune]int,value是用来登记出现的次数的。然后我就去用m1和m2把两个字符串遍历然后对里面的元素出现次数进行统计。最后选长一点的字符串来进行遍历判断。
(注意这里一定要长的),比如abc 和abcd,你遍历短的那肯定就是true,但实际上结果是false。所以要遍历短的。
func isAnagram(s string, t string) bool {
res1:=[]rune(s)
res2:=[]rune(t)
m1:= make(map[rune]int,len(res1))
m2:= make(map[rune]int,len(res2))
for i:=0;i<len(res1);i++{
m1[res1[i]]++
}
for j:=0;j<len(res2);j++{
m2[res2[j]]++
}
if len(res1)>len(res2){
for k,v :=range m1{
if m2[k]!=v{
return false
}
}
}else{
for k,v :=range m2{
if m1[k]!=v{
return false
}
}
}
return true
}
这是我第一次写的版本,可能看着有点啰嗦。
写的过程中的问题
1.go语言不像c++,可以直接对字符串的下标进行访问,所以这里要转成rune类型的切片。我这里写的问题就是,之前我没有仔细思考过这个问题,很多代码都喜欢转字节切片,这样虽然没什么毛病,但是我想尽量像c++这种。那这里的处理方式就是转成rune类型的切片就可以实现像c++这种了。
版本2
这是本题另外的思考
思考1:这是根据本题的性质来想的,由于只包含小写字母,那我完全可以开两个长度为26的数组进行模拟,两个数组分别取遍历这个字符串,然后就直接去遍历这个数组中每个索引的值,有一个对不上就返回false,遍历完全都对的上就返回true。但是我感觉这种记录映射的做法和哈希区别不大吧。
func isAnagram(s string, t string) bool {
if len(s) != len(t) {
return false
}
var countS, countT [26]int
for i := 0; i < len(s); i++ {
countS[s[i]-'a']++
countT[t[i]-'a']++
}
for i := 0; i < 26; i++ {
if countS[i] != countT[i] {
return false
}
}
return true
}
这个版本我觉得还是差了点,空间用的多了,所以我这里想办法再少用一个数组,这就得到了版本三。
版本三
版本三的思路是在版本二的基本上改的,我的哈希数组只记录字符串1的,然后我就直接去遍历字符串2。然后然后对应到数组去做减法,最后看数组的每一个元素是否都为0就判断成功了。否则判断失败。
func isAnagram(s string, t string) bool {
if len(s) != len(t) {
return false
}
var count [26]int
for _, char := range s {
count[char-'a']++
}
for _, char := range t {
count[char-'a']--
if count[char-'a'] < 0 {
return false
}
}
for _, c := range count {
if c != 0 {
return false
}
}
return true
}
两个数组的交集
拿到题时的思路:1.两个for肯定也还是能做出来,但是还是麻烦了好多。
2.哈希表,我看到找交集其实就已经想到了哈希表,因为哈希表模拟set可以快速判断集合中是否存在这个元素。
这里我就用了哈希表写。
版本一 我自己写的版本
func intersection(nums1 []int, nums2 []int) []int {
m1 := make(map[int]bool,len(nums1))
for i:=0;i<len(nums1);i++{
m1[nums1[i]]=true
}
res :=[]int{}
judge := make(map[int]bool)
for j:=0;j<len(nums2);j++{
if m1[nums2[j]]==false{
continue
}else{
if judge[nums2[j]] == false{
res = append(res, nums2[j])
judge[nums2[j]]=true
}
}
}
return res
}
思路:
1.先拿一个map先把nums1中的元素登记
2.创建一个res空切片用来存储结果
3.再创建一个登记map,输出有一个要求,那就是输出结果中的元素要唯一,创建登记map就可以实现快速查找我的res结果切片中是否存在该元素,如果存在了就不把元素加入结果切片,不存在就加入。
4.遍历nums2,同时进行map1的判断。满足map1中为true,且登记map中为false,就加入结果。
做的时候的问题:
1.以后创建空切片就可以这么搞res :=[]int{},这样简单又快捷,之前我老是去想计算大小然后用make来创建切片。当然各有各的好处,如果为了做题目我更加推荐前者。
2.一种问题的处理思路:判断某个元素是否已经存在切片中,那就用map进行登记即可。map直接处理了。我当时判断是否重复加入那里我就懵逼了一下。
版本2:数组来做
我觉得这个思路的本质也是哈希,但是本题能用数组那是因为题目限制了数的范围,那我直接开一个范围这么大的数组,直接当哈希表用了。这个做法我觉得和上面没啥差别,就是把map换成了数组。映射关系的本质我觉得是一样的。但是用哈希就比较通用,因为没有数大小限制。
于是这里进行一个数组和哈希的选择总结:数的范围比较大就map,否则数组。
总结一个用哈希的条件反射,判断一个元素是否出现过,立马哈希。
两数之和
这个暴力做就是两个for把结果全遍历出来
哈希表做法:
思路:
1.遍历nums切片,然后用map登记对应元素的下标。
2.再遍历nums,这次是为了找target-nums[j]是否存在,存在的话可以通过map快速得到另一个元素的下标。
3.还要进行一个特判,i不能等于j
4.对于同一个元素在答案里不能重复出现这里我直接返回结果,就不会考虑后面多出来的元素。
func twoSum(nums []int, target int) []int {
m1:= make(map[int]int)
for i:=0;i<len(nums);i++{
m1[nums[i]]=i
}
for j:=0;j<len(nums);j++{
i ,exist:= m1[target-nums[j]]
if exist==true && i!=j{
return []int{j,i}
}
}
return []int{}
}
写的时候的问题
1.这用到了一个性质,访问map时其实是有两个返回值,一个是value,另一个是一个bool类型的值,代表该元素是否存在。通过这个性质我可以直接存储下标就可以快速得到结果。
但是我在写的时候一开始没想到或者说想到了还是纠结一个地方,我当时还打算用0去判断,但是我又考虑到下标有0,于是我就做不下去了。后来看到了这个性质,所以用0来判断根本就没必要。
202 快乐数
这个题我是第一眼就爆炸了,因为我不太擅长处理单数,如果这个数是定的我还换,他会变长我就寄了。这里我直接看题解了。
首先来看这个不断地计算过程中会发生什么事
首先猜测有这么三种情况
a->x->x->x->x->…->p
这个p要么最终等于1,要么这个p又绕回前面的某一个数形成环,要么p越来越大。
我举几个例子

这个满足了情况1
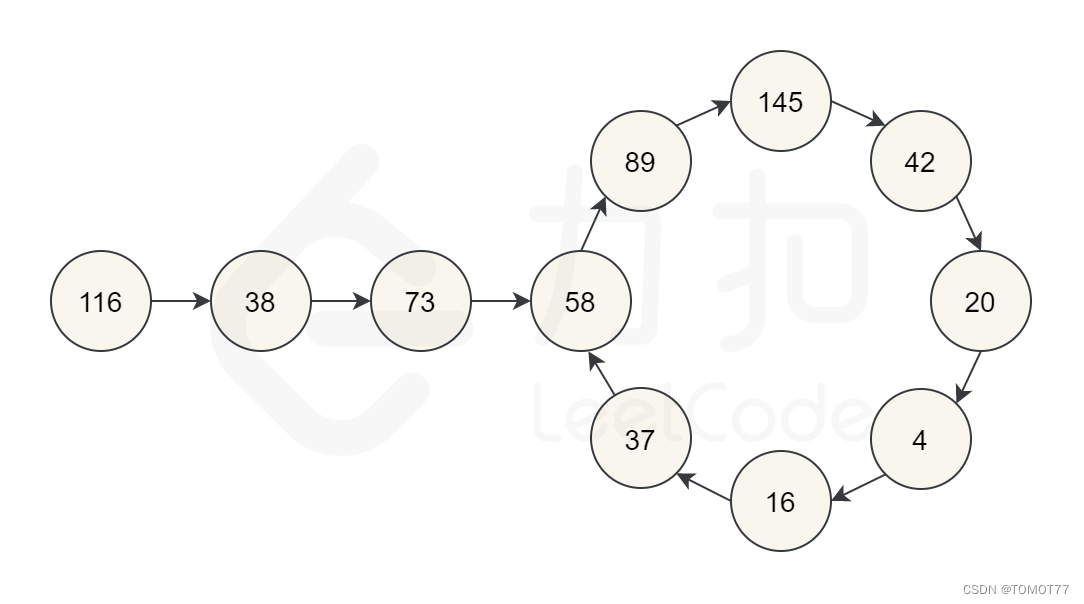
这个满足了情况2
那第三种情况:有一个规律的推导:
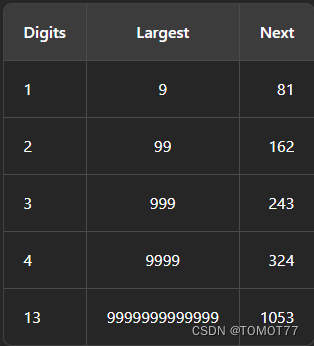
从这个规律我们可以发现,对于三位数的数字,他在怎么转换,转换后的结果都不可能大于243,因为三位都是9转换出来的就是转换后的最大值,这能说明什么,三位大于0的数字它的转换的数字范围始终在1-243这个循环里面,它能不能回到1这个不清楚,但是可以确定一个结论如果没有环,那么肯定能转到1去,如果出现了环,那么肯定转不动1。这样就找到了控制退出的出口。
这个推导进行推广:可知对于更高位的数进行转换,终究要么是在环里转变,要么最终转变到1.
这样代码逻辑就可以总结出来:就干两件事情
1.将数字不断地进行平方和转换
2.不断的查询哈希表,看是否进入了环。
如果查到了环就返回假,查到了1就返回真
func getsum(n int)int{
sum :=0
for n>0{
temp := n%10
sum+= temp*temp
n/=10
}
return sum
}
func isHappy(n int) bool {
m1:=make(map[int]bool)
for n!=1{
if m1[n]==true{
return false
}
m1[n]=true
n=getsum(n)
}
return true
}
我写的时候遇到的难点:
就是一开始没不太会处理这种各位数字,老师想多,想什么要是他位数变多了,我是不是还得考虑它的位数什么的来控制循环的进行。
这个是我需要掌握的一个点,之前没怎么积累。
我只能说经过学习后,根本没必要这么做
直接拿到这个数不停的模10,然后除十,不断循环下去,直到数被除成0,这样每一位都拿到了,根本不用考虑什么位数变化。
我只能说这个快乐数是需要自己去模拟的,不自己去模拟推导,可能觉得看不出什么规律,如果直接按照题目要求直接硬求和可能导致的就是如果不是快乐数,你不知道在哪里退出循环返回false。
总结
今天的题目主要关注三个东西,算法思路,语法性质,常用的算法处理。














 812
812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









