







引言
Redis官网对于redis有以下的介绍
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Redis是一个开源(BSD许可)的内存数据结构存储,用作数据库、缓存和消息代理。Redis提供数据结构,如字符串、哈希、列表、集合、带范围查询、位图、超对数、地理空间索引和流的排序集。Redis具有内置的复制、Lua脚本、LRU驱逐、事务和不同级别的磁盘持久性,并通过Redis Sentinel和Redis Cluster的自动分区提供高可用性。
1. Redis的特性
redis具有以下的特性:
- 异常快 - Redis 非常快,每秒可执行大约 110000 次的设置(SET)操作,每秒大约可执行 81000 次的读取/获取(GET)操作。
- 支持丰富的数据类型 - Redis 支持开发人员常用的大多数数据类型,例如列表,集合,排序集和散列等等。这使得 Redis 很容易被用来解决各种问题,因为我们知道哪些问题可以更好使用地哪些数据类型来处理解决。
- 操作具有原子性 - 所有 Redis 操作都是原子操作,这确保如果两个客户端并发访问,Redis 服务器能接收更新的值。
- 多实用工具 - Redis 是一个多实用工具,可用于多种用例,如:缓存,消息队列(Redis 本地支持发布/订阅),应用程序中的任何短期数据,例如,web应用程序中的会话,网页命中计数等。
2. Redis 数据结构
Redis 有 5 种基础数据结构,它们分别是:String(字符串)、List(列表)、Hash(字典)、Set(集合) 和 Zset(有序集合)。这 5 种是 Redis 相关知识中最基础、最重要的部分,下面我们结合源码以及一些实践来给大家分别讲解一下。
2.1 String 数据类型
Redis 中的字符串是一种 动态字符串,这意味着使用者可以修改,它的底层实现有点类似于 Java 中的 ArrayList,有一个字符数组,从源码的 sds.h/sdshdr 文件 中可以看到 Redis 底层对于字符串的定义 SDS,即 Simple Dynamic String 结构:
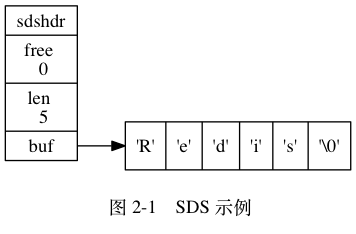
SDS和C语言中字符串的区别:
- 获取字符串长度为 O(N) 级别的操作 → 因为 C 不保存数组的长度,每次都需要遍历一遍整个数组;
- 不能很好的杜绝 缓冲区溢出/内存泄漏 的问题 → 跟上述问题原因一样,如果执行拼接 or 缩短字符串的操作,如果操作不当就很容易造成上述问题;
- C 字符串 只能保存文本数据 → 因为 C 语言中的字符串必须符合某种编码(比如 ASCII),例如中间出现的
'\0'可能会被判定为提前结束的字符串而识别不了;
2.2 List 数据类型
Redis 的列表相当于 Java 语言中的 LinkedList,注意它是链表而不是数组。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n)。
我们可以从源码的 adlist.h/listNode 来看到对其的定义:

链表的基本操作
LPUSH和RPUSH分别可以向 list 的左边(头部)和右边(尾部)添加一个新元素;LRANGE命令可以从 list 中取出一定范围的元素;LINDEX命令可以从 list 中取出指定下表的元素,相当于 Java 链表操作中的get(int index)操作;
list 实现队列:
队列是先进先出的数据结构,常用于消息排队和异步逻辑处理,它会确保元素的访问顺序:
list 实现栈:
栈是先进后出的数据结构,跟队列正好相反:
2.3 Map 数据结构
Redis 中的字典相当于 Java 中的 HashMap,内部实现也差不多类似,都是通过 “数组 + 链表” 的链地址法来解决部分 哈希冲突,同时这样的结构也吸收了两种不同数据结构的优点。
可以从上面的源码中看到,实际上字典结构的内部包含两个 hashtable,通常情况下只有一个 hashtable 是有值的,但是在字典扩容缩容时,需要分配新的 hashtable,然后进行 渐进式搬迁 (下面说原因)。

渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,如上图所示,查询时会同时查询两个 hash 结构,然后在后续的定时任务以及 hash 操作指令中,循序渐进的把旧字典的内容迁移到新字典中。当搬迁完成了,就会使用新的 hash 结构取而代之。
扩容条件
正常情况下,当 hash 表中 元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是 原数组大小的 2 倍。不过如果 Redis 正在做 bgsave(持久化命令),为了减少内存也得过多分离,Redis 尽量不去扩容,但是如果 hash 表非常满了,达到了第一维数组长度的 5 倍了,这个时候就会 强制扩容。
当 hash 表因为元素逐渐被删除变得越来越稀疏时,Redis 会对 hash 表进行缩容来减少 hash 表的第一维数组空间占用。所用的条件是 元素个数低于数组长度的 10%,缩容不会考虑 Redis 是否在做 bgsave。
2.4 Set 数据结构
Redis 的集合相当于 Java 语言中的 HashSet,它内部的键值对是无序、唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值 NULL。
2.5 有序列表

想象你是一家创业公司的老板,刚开始只有几个人,大家都平起平坐。后来随着公司的发展,人数越来越多,团队沟通成本逐渐增加,渐渐地引入了组长制,对团队进行划分,于是有一些人又是员工又有组长的身份。再后来,公司规模进一步扩大,公司需要再进入一个层级:部门。于是每个部门又会从组长中推举一位选出部长。跳跃表就类似于这样的机制,最下面一层所有的元素都会串起来,都是员工,然后每隔几个元素就会挑选出一个代表,再把这几个代表使用另外一级指针串起来。然后再在这些代表里面挑出二级代表,再串起来。最终形成了一个金字塔的结构。















 1909
1909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









