






一、认识Hadoop框架
1.What——什么是Hadoop?
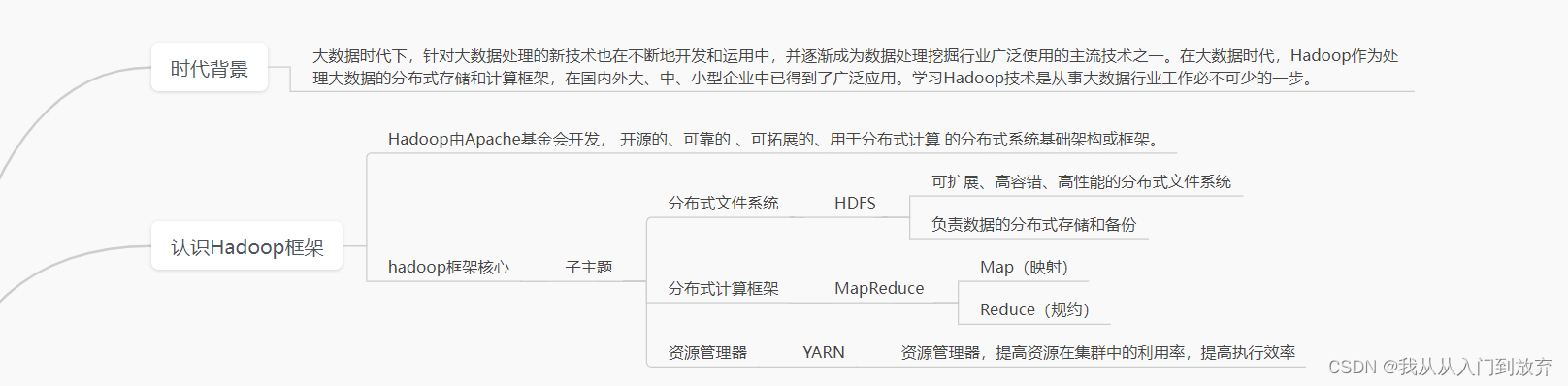
Hadoop由Apache基金会开发, 开源的、可靠的 、可拓展的、用于分布式计算 的分布式系统基础架构或框架。

2. Hadoop框架核心
(1) 分布式文件系统——HDFS
可扩展、高容错、高性能的分布式文件系统。
负责数据的分布式存储和备份。
(2) 分布式计算框架——MapReduce
① Map(映射)
② Reduce(规约)
(3) 资源管理器——YARN
资源管理器,提高资源在集群中的利用率,提高执行效率。
3. 了解Hadoop发展历史
(1)2002年——道格·卡廷和迈克·卡法雷拉创建Nutch
(2)2003年——谷歌公司发表了GFS和MapReduce论文
(3)2004年——道格·卡廷和其他开发者们开始研究NDFS和MapReduce
(4)2006年——道格·卡廷加入雅虎公司并带走了Hadoop
(5)2007年——开发人员在100个亚马逊的虚拟机服务器上使用Hadoop转换处理了4TB的图片数据
(6)2008年——Facebook创建了基于Hadoop的组件:Hive
(7)2009年——道格·卡廷加入Cloudera公司
(8)2011年——Hortonworkers公司成立
(9)2012年——推出YARN框架的第一个版本
(10)2013年——Hortonworkers公司完全开源
(11)2014年——Hadoop 2.x快速发展
(12)2016年——Hadoop及其生态圈组件得到广泛的应用
(13)2017年——Hadoop 3.x发布
(14)2022年——Hadoop 3.1.4发布
4. 了解Hadoop的特点
(1)高容错性
HDFS在存储文件时将在多台机器或多个节点上存储文件的备份副本,当读取该文件出错或某一个节点宕机时,系统会调用其他节点上的备份文件,保证程序顺利运行。
如果启动存储的任务失败,那么Hadoop 将重新运行该任务或启用其他任务来完成失败的任务中没有完成的部分。
(2)高可靠性
数据存储有多个备份,集群部署在不同机器上,可以防止一个节点宕机造成集群损坏。当数据处理请求失败时,Hadoop 将自动重新部署计算任务。
Hadoop框架中有备份机制和检验模式,可以对出现问题的部分进行修复,也可以通过设置快照的方式在集群出现问题时回到之前的一个时间点。
(3)高扩展性
Hadoop是在可用的计算机集群间分配数据并完成计算任务的。
为集群添加新的节点并不复杂,因此集群可以很容易地进行节点的扩展,以扩大集群。
(4)高效性
Hadoop可以在节点之间动态地移动数据,在数据所在节点进行并行处理并保证各个节点的动态平衡,因此处理速度非常快。
(5)低成本
Hadoop 是开源的,即不需要支付任何费用即可下载并安装使用,节省了软件购买的成本。
(6)可构建在廉价机器上
Hadoop不要求机器的配置达到极高的水准,大部分普通商用服务器即可满足要求,通过提供多个副本和容错机制提高集群的可靠性。
(7)Hadoop基本框架用Java语言编写
Hadoop是一个用Java语言开发的框架,因此运行在Linux 系统上是非常理想的。
Hadoop 上的应用程序也可以使用其他语言编写,如C++和Python。
二、了解Hadoop核心组件
1. 了解
Hadoop有3大核心组件,分别是分布式文件系统HDFS、分布式计算框架MapReduce和集群资源管理器YARN。
2. 分布式文件系统——HDFS
(1) HDFS简介及架构
HDFS——以分布式进行存储的文件系统,主要负责集群数据的存储与读取。
HDFS——是一个主/从(Master/Slave)体系架构的分布式文件系统。

HDFS文件系统主要包含一个NameNode、一个Secondary NameNode和多个DataNode。
①NameNode
NameNode用于存储元数据以及处理客户端(Client)发出的请求。
元数据不是具体的文件内容,它包含3类重要信息。
第1类——是文件和目录自身的属性信息,如文件名、目录名、父目录信息、文件大小、创建时间、修改时间等;
第2类——是文件内容存储的相关信息,如文件分块情况、副本个数、每个副本所在的DataNode 信息等;
第3类——是HDFS中所有DataNode的信息,用于管理DataNode。
在NameNode 中存放元数据的文件是fsimage 文件。
在系统运行期间,所有对元数据的操作均保存在内存中,并被持久化到另一个文件edits中。
当NameNode启动时,fsimage文件将被加载至内存,再对内存里的数据执行edits文件中所记录的操作,以确保内存所保留的数据处于最新的状态。
②Secondary NameNode
Secondary NameNode 用于备份NameNode的数据,周期性地将edits文件合并到fsimage文件并在本地备份,将新的fsimage 文件存储至NameNode,覆盖原有的fsimage文件,删除edits文件,并创建一个新的edits文件继续存储文件当前的修改状态。
③DataNode
DataNode 是真正存储数据的地方,在DataNode中,文件以数据块的形式进行存储。
数据文件在上传至HDFS时将根据系统默认的文件块大小被划分成一个个数据块,Hadoop 3.x中一个数据块的大小为128MB,如果存储一个大小为129MB的文件,那么文件将被分为两个数据块进行存储。
再将每个数据块存储至不同的或相同的DataNode中,并且备份副本,一般默认备份3个副本,NameNode 负责记录文件的分块信息,确保在读取该文件时可以找到并整合所有该文件的数据块。

(2)分布式原理
HDFS作为一个分分布式系统可以划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的整体功能。
利用多个节点共同协作完成一项或多项具体业务功能的系统即为分布式系统。
分布式文件系统,主要体现在3个方面 。
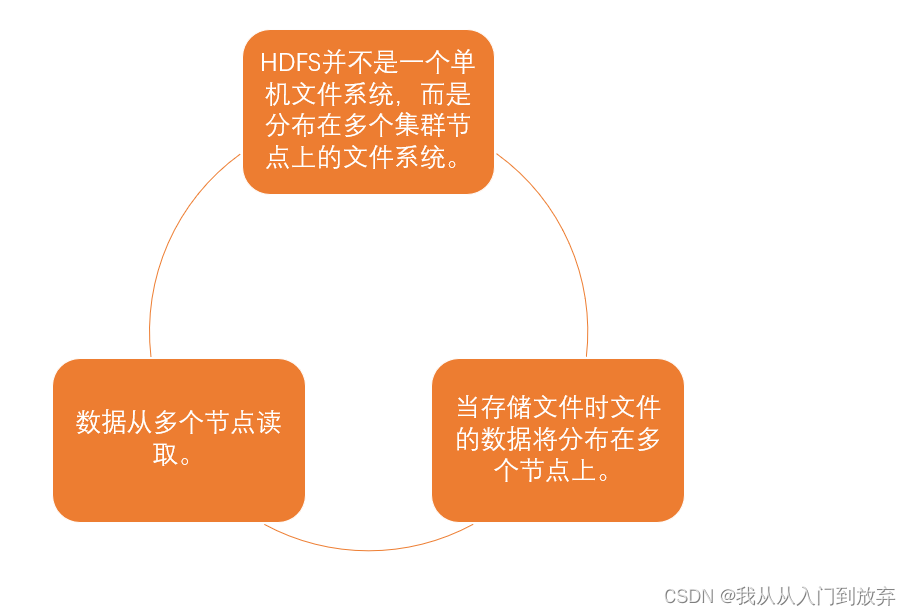
数据存储在文件系统中,如果某个节点宕机了,那么很容易造成数据流失。
(3)宕机处理
①冗余备份
在数据存储的过程中,对每个数据块都进行了副本备份,副本个数可以自行设置。
②副本存放
目前使用的策略是,以存放3个副本(dfs.replication=3)为例,
在同一机器的两个节点上各备份一个副本,再在另一台机器的某个节点上存放一个副本,前者可防止当该机器的某个节点宕机使可恢复数据,后者则防止当某个机器宕机时可恢复数据。
③宕机处理
a——如果NameNode在预定的时间内没有收到心跳信息(默认是10min),将该DataNode从集群中移除。
b——当HDFS读取某个数据块时,如果正好存储该数据块的某个节点宕机了,那么客户端将会在存储该数据块的其他节点上读取数据块信息。
c——当HDFS存储数据时,如果需要存放数据的节点宕机,那么HDFS将再重新分配一个节点给该数据块,并备份宕机节点中的数据。
(4)HDFS特点
① HAFS——优点
a. 高容错性
HDFS上传的数据自动保存多个副本,通过增加副本的数量增加HDFS的容错性,如果某一个副本丢失,那么HDFS将复制其他节点上的副本。
b.适合大规模数据的处理
HDFS能够处理上百万的GB、TB甚至PB级别的数据,数量非常大。
c.流式数据访问
流式数据访问·HDFS以流式数据访问模式存储超大文件,有着“一次写入,多次读取”的特点,
文件一旦写入,不能修改,只能增加,以保证数据的一致性。
② HAFS——缺点
A. 不适合低延迟数据访问
B. 无法高效存储大量小文件
C. 不支持多用户写人及任意修改文件
3. 了解分布式计算框架——MapReduce
(1) MapReduce简介
MapReduce是Hadoop的核心计算框架——是用于大规模数据集(大于1TB)并行运算的编程模型,主要包括Map(映射)和Reduce(规约)两个阶段。
MapReduce的核心思想是——当启动一个MapReduce任务时,Map端将会读取HDFS上的数据,将数据映射成所需要的键值对类型并传至Reduce端。
Reduce端接收Map端键值对类型的中间数据,并根据不同键进行分组,对每一组键相同的数据进行处理,得到新的键值对并输出至HDFS。
(2) MapReduce工作原理
一个完整的MapReduce过程包含数据的输入与分片、Map阶段数据处理、Shuffle&Sort阶段数据整合、Reduce阶段数据处理、数据输出等阶段。
a根据设置的分片大小划分文件,得到一到多个文件块,一个文件块对应一个Map
b针对所有键相同的数据,对其值进行整合
c整合后的数据传送到Reduce端处理
图: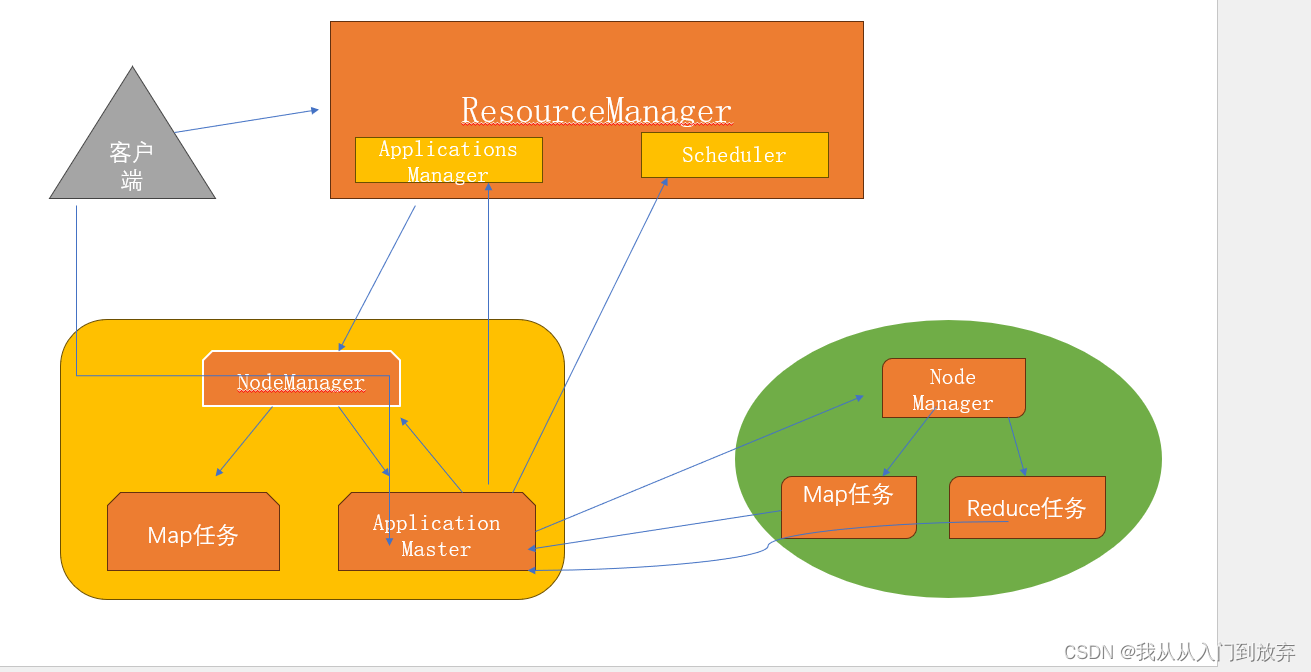
(3)了解HDFS
①读取输入数据
从HDFS分布式文件系统中读取的,根据所设置的分片大小对文件重新分片(Split)。
②Map阶段
数据将以键值对的形式被读入,键的值一般为每行首字符与文件最初始位置的偏移量,即中间所隔字符个数,值为该行的数据记录。
根据具体的需求对键值对进行处理,映射成新的键值对,将新的键值对传输至Reduce端。
③Shuffle&Sort阶段
将同一个Map中输出的键相同的数据先进行整合,减少传输的数据量,并且在整合后将数据按照键进行排序。
④Reduce阶段
针对所有键相同的数据,对数据进行规约,形成新的键值对。
⑤输出阶段
将数据文件输出至HDFS,输出的文件个数和Reduce的个数一致,如果只有一个Reduce,那么输出的只有一个数据文件,默认命名为“part-r-00000”。
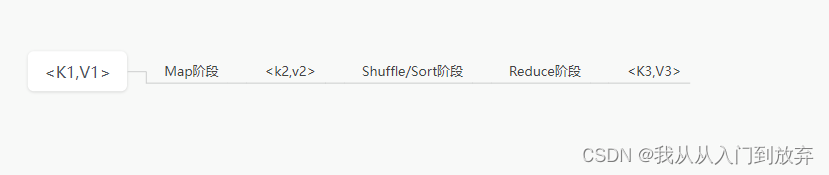
(4)MapReduce的本质
将一组键值对<K1,V1>经过Map阶段映射成新的键值对<K2,V2>,接着经过Shuffle/Sort阶段进行排序和整合,最后经过Reduce阶段,将整合后的键值对组进行规约处理,输出新的键值对<K3,V3>。
图:
4. 了解集群资源管理器——YARN
(1) YARN简介
①YARN是Hadoop的资源管理器,提交应用至YARN上执行可以提高资源在集群的利用率,加快执行速率。
②HadoopYARN的目的是使得Hadoop数据处理能力超越MapReduce。
③YARN的另一个目标就是拓展Hadoop,使得YARN不仅可以支持MapReduce计算,而且还可以很方便地管理如Hive、HBase、Pig、Spark/Shark等组件的应用程序。
(2)YARN的基本架构和任务流程
A. YARN的基本组成结构 YARN主要由
ResourceManager、NodeManager、ApplicationMaster和Client Application这4部分构成。
图:
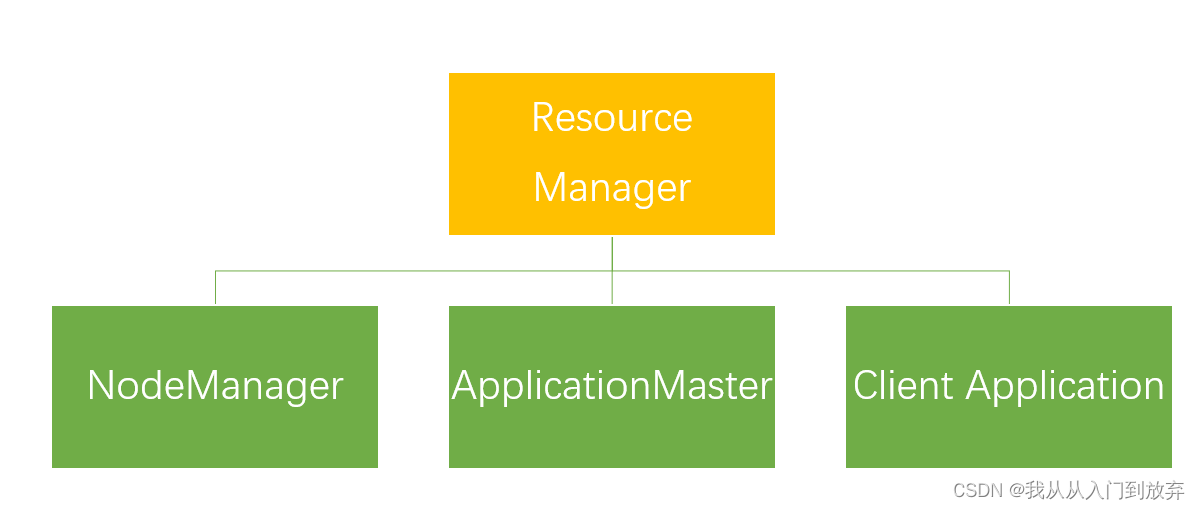
① ResourceManager(简称RM):
一个全局的资源管理器,负责整个系统的资源管理和分配,主要由两个组件构成,即调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
调度器负责将系统中的资源分配给各个正在运行的应用程序,不从事任何与具体应用程序相关的工作,如监控或跟踪应用程序的执行状态等,也不负责重新启动因应用程序行失败或硬件故障而导致的失败任务。
应用程序管理器负责处理客户端提交的任务以及协商第一个Container(包装资源的对象)以供ApplicationMaster 运行,并且在Application Master失败时会将其重新启动。 其中,Container 是YARN中的资源承载,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
当Application Master 向 ResourceManager 申请资源时,ResourceManager为ApplicationMaster 返回的资源就是使用Container 表示的。
YARN会为每个任务分配一个Container,且该任务只能使用该Container 中描述的资源。
②NodeManager(简称NM):
每个节点上的资源和任务管理器。
一方面,它会定时地向ResourceManager 汇报本节点上的资源使用情况和各个Container的运行状态;
另一方面,它将接收并处理来自 ApplicationMaster 的Container 启动或停止等各种请求。
③ ApplicationMaster(简称AM):
在用户提交每个应用程序时,系统会生成一个ApplicationMaster 并将其添加到提交的应用程序里。
ApplicationMaster 的主要功能如下。
——与ResourceManager 调度器协商以获取资源(用Container 表示)。
——将得到的任务进行进一步的分配。
——与NodeManager 通信以启动或停止任务。
——监控所有任务运行状态,在任务运行失败时重新为任务申请资源并重启任务。
④ Client Application:客户端应用程序。
客户端将应用程序提交到ResourceManager时,
首先——将创建一个Application 上下文对象,
再——设置 ApplicationMaster 必需的资源请求信息,
最后——提交至ResourceManager。
B——YARN的工作流程。
YARN从提交任务到完成任务的整个工作流程如下:
YARN的工作流程:
① 用户通过客户端提交一个应用程序到YARN中进行处理,其中包括 ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
②ResourceManager 为该应用程序分配第一个Container,并与分配的Container 所在位置的NodeManager 通信,要求NodeManager 在这个Container 中启动应用程序的ApplicationMaster。该Container 用于启动 ApplicationMaster 和 ApplicationMaster后续的命令。
③ ApplicationMaster 启动后先向 ResourceManager 注册,这样用户就可以直接通过ResourceManager 查看应用程序的运行状态,再为提交的应用程序所需要执行的各个任务申请资源,并监控任务的运行状态,直至运行结束,即重复步骤④~⑦。图1-7所示的示例应用程序需要执行两个Map任务和一个Reduce任务,因此需要轮番执行步骤④~⑦共3次,先执行Map任务,再执行Reduce任务。
④ ApplicationMaster 采用轮询的方式通过远程进程调用(Remote Procedure Call,RPC)协议向ResourceManager 申请和领取资源。因此多个应用程序同时提交时,不一定是第一个应用程序先执行。
⑤一旦 ApplicationMaster 申请到资源,便与资源对应的 NodeManager 通信,要求NodeManager 在分配的资源中启动任务。
⑥NodeManager 为任务设置好运行环境(包括环境变量、Jar包、二进制程序等)后,将任务启动命令写入一个脚本中,并通过运行该脚本启动任务。
⑦ 被启动的任务开始执行,各个任务通过某个RPC 协议向 ApplicationMaster 汇报运行的状态和进度,以便让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC协议向ApplicationMaster查询应用程序的当前运行状态。
⑧应用程序运行完成后,ApplicationMaster 向ResourceManager进行注销,释放资源。
⑨关闭客户端与 ApplicationMaster
三、Hadoop的基本操作命令
1.启动Hadoop
进入HADOOP_HOME目录。
执行:
bin/start-all.sh2.关闭Hadoop
进入HADOOP_HOME目录。
执行:
sh bin/stop-all.sh3.查看指定目录下内容
Hadoopdfs –ls (文件目录)4.打开某个已存在文件
hadoop dfs –cat (文件路径)5.将本地文件存储至hadoop
hadoop fs –put (本地地址) (hadoop目录)6.将hadoop上某个文件down至本地已有目录下
hadoop fs -get (文件目录])(本地目录)7.删除hadoop上指定文件
hadoop fs –rm (文件地址)8.删除hadoop上指定文件夹(包含子目录等)
hadoop fs –rm (目录地址)9.在hadoop指定目录内创建新目录
hadoop fs –mkdir (新的目录)10.在hadoop指定目录下新建一个空文件
使用touchz命令:
hadoop fs -touchz (新的)















 1280
1280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









